 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDMLR: Data-centric Machine Learning Research -- Past, Present and Future
Nov 21, 2023


Drawing from discussions at the inaugural DMLR workshop at ICML 2023 and meetings prior, in this report we outline the relevance of community engagement and infrastructure development for the creation of next-generation public datasets that will advance machine learning science. We chart a path forward as a collective effort to sustain the creation and maintenance of these datasets and methods towards positive scientific, societal and business impact.
Speech Wikimedia: A 77 Language Multilingual Speech Dataset
Aug 30, 2023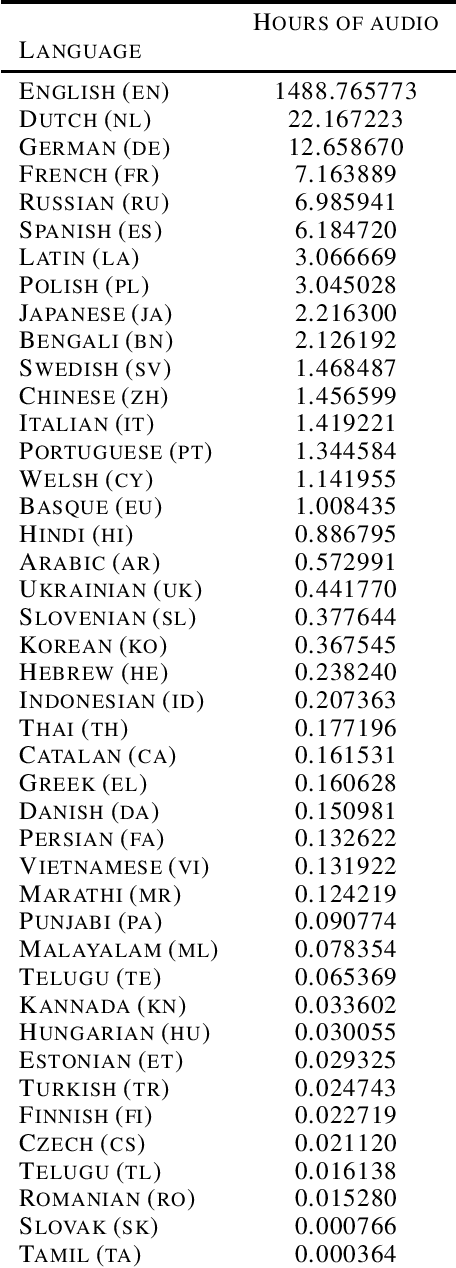
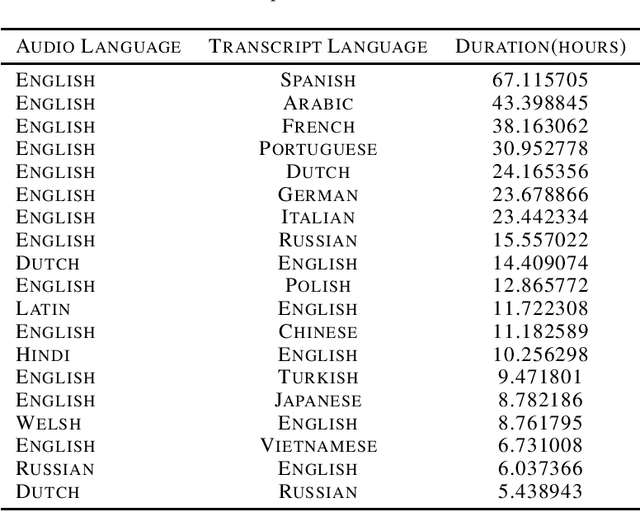
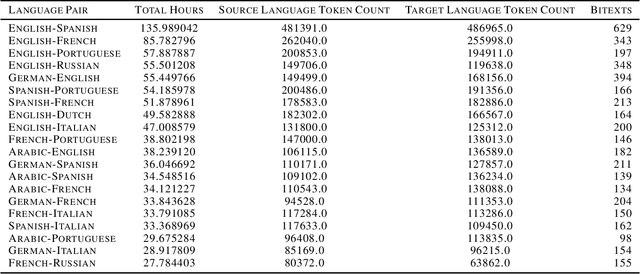

The Speech Wikimedia Dataset is a publicly available compilation of audio with transcriptions extracted from Wikimedia Commons. It includes 1780 hours (195 GB) of CC-BY-SA licensed transcribed speech from a diverse set of scenarios and speakers, in 77 different languages. Each audio file has one or more transcriptions in different languages, making this dataset suitable for training speech recognition, speech translation, and machine translation models.