 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegment Anything Model Can Not Segment Anything: Assessing AI Foundation Model's Generalizability in Permafrost Mapping
Jan 16, 2024
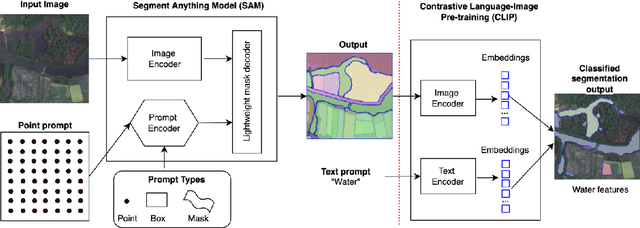
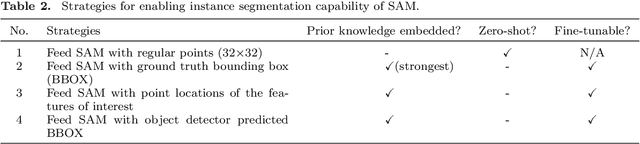

This paper assesses trending AI foundation models, especially emerging computer vision foundation models and their performance in natural landscape feature segmentation. While the term foundation model has quickly garnered interest from the geospatial domain, its definition remains vague. Hence, this paper will first introduce AI foundation models and their defining characteristics. Built upon the tremendous success achieved by Large Language Models (LLMs) as the foundation models for language tasks, this paper discusses the challenges of building foundation models for geospatial artificial intelligence (GeoAI) vision tasks. To evaluate the performance of large AI vision models, especially Meta's Segment Anything Model (SAM), we implemented different instance segmentation pipelines that minimize the changes to SAM to leverage its power as a foundation model. A series of prompt strategies was developed to test SAM's performance regarding its theoretical upper bound of predictive accuracy, zero-shot performance, and domain adaptability through fine-tuning. The analysis used two permafrost feature datasets, ice-wedge polygons and retrogressive thaw slumps because (1) these landform features are more challenging to segment than manmade features due to their complicated formation mechanisms, diverse forms, and vague boundaries; (2) their presence and changes are important indicators for Arctic warming and climate change. The results show that although promising, SAM still has room for improvement to support AI-augmented terrain mapping. The spatial and domain generalizability of this finding is further validated using a more general dataset EuroCrop for agricultural field mapping. Finally, we discuss future research directions that strengthen SAM's applicability in challenging geospatial domains.
Self-Supervised Masked Digital Elevation Models Encoding for Low-Resource Downstream Tasks
Sep 06, 2023The lack of quality labeled data is one of the main bottlenecks for training Deep Learning models. As the task increases in complexity, there is a higher penalty for overfitting and unstable learning. The typical paradigm employed today is Self-Supervised learning, where the model attempts to learn from a large corpus of unstructured and unlabeled data and then transfer that knowledge to the required task. Some notable examples of self-supervision in other modalities are BERT for Large Language Models, Wav2Vec for Speech Recognition, and the Masked AutoEncoder for Vision, which all utilize Transformers to solve a masked prediction task. GeoAI is uniquely poised to take advantage of the self-supervised methodology due to the decades of data collected, little of which is precisely and dependably annotated. Our goal is to extract building and road segmentations from Digital Elevation Models (DEM) that provide a detailed topography of the earths surface. The proposed architecture is the Masked Autoencoder pre-trained on ImageNet (with the limitation that there is a large domain discrepancy between ImageNet and DEM) with an UperNet Head for decoding segmentations. We tested this model with 450 and 50 training images only, utilizing roughly 5% and 0.5% of the original data respectively. On the building segmentation task, this model obtains an 82.1% Intersection over Union (IoU) with 450 Images and 69.1% IoU with only 50 images. On the more challenging road detection task the model obtains an 82.7% IoU with 450 images and 73.2% IoU with only 50 images. Any hand-labeled dataset made today about the earths surface will be immediately obsolete due to the constantly changing nature of the landscape. This motivates the clear necessity for data-efficient learners that can be used for a wide variety of downstream tasks.
What Does TERRA-REF's High Resolution, Multi Sensor Plant Sensing Public Domain Data Offer the Computer Vision Community?
Aug 18, 2021
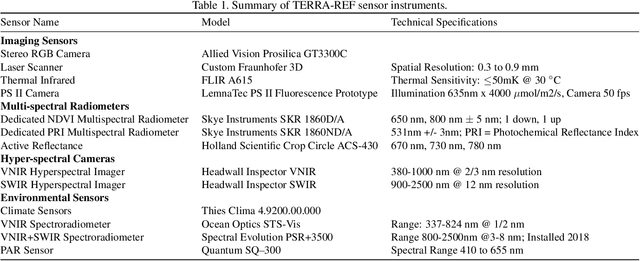


A core objective of the TERRA-REF project was to generate an open-access reference dataset for the evaluation of sensing technologies to study plants under field conditions. The TERRA-REF program deployed a suite of high-resolution, cutting edge technology sensors on a gantry system with the aim of scanning 1 hectare (10$^4$) at around 1 mm$^2$ spatial resolution multiple times per week. The system contains co-located sensors including a stereo-pair RGB camera, a thermal imager, a laser scanner to capture 3D structure, and two hyperspectral cameras covering wavelengths of 300-2500nm. This sensor data is provided alongside over sixty types of traditional plant phenotype measurements that can be used to train new machine learning models. Associated weather and environmental measurements, information about agronomic management and experimental design, and the genomic sequences of hundreds of plant varieties have been collected and are available alongside the sensor and plant phenotype data. Over the course of four years and ten growing seasons, the TERRA-REF system generated over 1 PB of sensor data and almost 45 million files. The subset that has been released to the public domain accounts for two seasons and about half of the total data volume. This provides an unprecedented opportunity for investigations far beyond the core biological scope of the project. The focus of this paper is to provide the Computer Vision and Machine Learning communities an overview of the available data and some potential applications of this one of a kind data.
Convergence of Artificial Intelligence and High Performance Computing on NSF-supported Cyberinfrastructure
Mar 18, 2020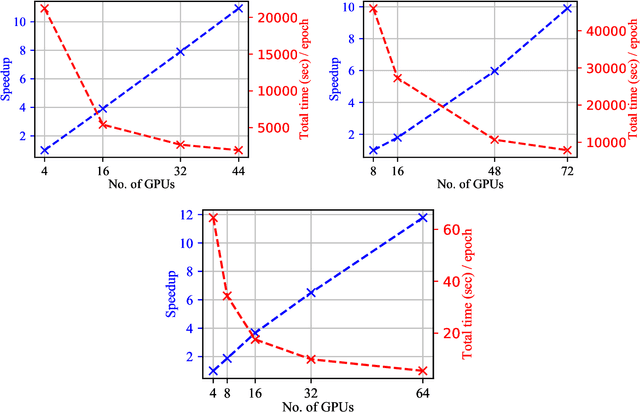
Significant investments to upgrade or construct large-scale scientific facilities demand commensurate investments in R&D to design algorithms and computing approaches to enable scientific and engineering breakthroughs in the big data era. The remarkable success of Artificial Intelligence (AI) algorithms to turn big-data challenges in industry and technology into transformational digital solutions that drive a multi-billion dollar industry, which play an ever increasing role shaping human social patterns, has promoted AI as the most sought after signal processing tool in big-data research. As AI continues to evolve into a computing tool endowed with statistical and mathematical rigor, and which encodes domain expertise to inform and inspire AI architectures and optimization algorithms, it has become apparent that single-GPU solutions for training, validation, and testing are no longer sufficient. This realization has been driving the confluence of AI and high performance computing (HPC) to reduce time-to-insight and to produce robust, reliable, trustworthy, and computationally efficient AI solutions. In this white paper, we present a summary of recent developments in this field, and discuss avenues to accelerate and streamline the use of HPC platforms to design accelerated AI algorithms.
Enabling real-time multi-messenger astrophysics discoveries with deep learning
Nov 26, 2019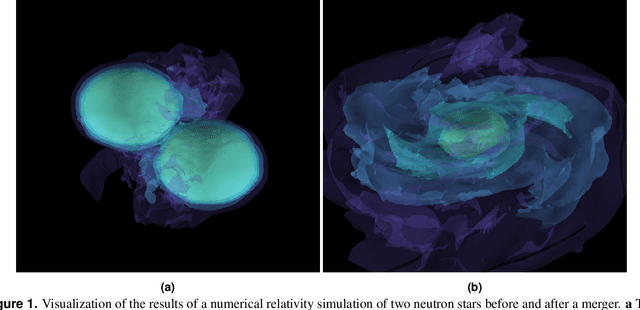
Multi-messenger astrophysics is a fast-growing, interdisciplinary field that combines data, which vary in volume and speed of data processing, from many different instruments that probe the Universe using different cosmic messengers: electromagnetic waves, cosmic rays, gravitational waves and neutrinos. In this Expert Recommendation, we review the key challenges of real-time observations of gravitational wave sources and their electromagnetic and astroparticle counterparts, and make a number of recommendations to maximize their potential for scientific discovery. These recommendations refer to the design of scalable and computationally efficient machine learning algorithms; the cyber-infrastructure to numerically simulate astrophysical sources, and to process and interpret multi-messenger astrophysics data; the management of gravitational wave detections to trigger real-time alerts for electromagnetic and astroparticle follow-ups; a vision to harness future developments of machine learning and cyber-infrastructure resources to cope with the big-data requirements; and the need to build a community of experts to realize the goals of multi-messenger astrophysics.
* Invited Expert Recommendation for Nature Reviews Physics. The art work produced by E. A. Huerta and Shawn Rosofsky for this article was used by Carl Conway to design the cover of the October 2019 issue of Nature Reviews Physics
Deep Learning for Multi-Messenger Astrophysics: A Gateway for Discovery in the Big Data Era
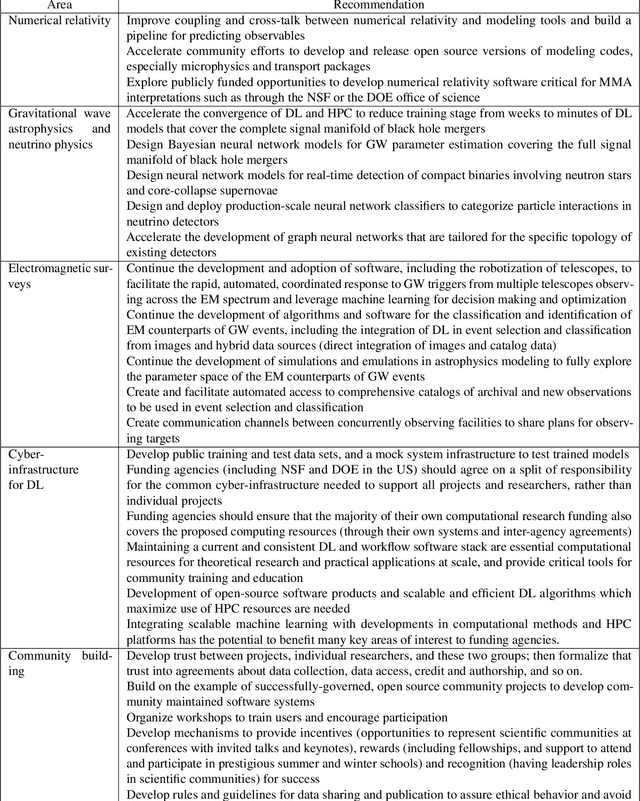
Feb 01, 2019This report provides an overview of recent work that harnesses the Big Data Revolution and Large Scale Computing to address grand computational challenges in Multi-Messenger Astrophysics, with a particular emphasis on real-time discovery campaigns. Acknowledging the transdisciplinary nature of Multi-Messenger Astrophysics, this document has been prepared by members of the physics, astronomy, computer science, data science, software and cyberinfrastructure communities who attended the NSF-, DOE- and NVIDIA-funded "Deep Learning for Multi-Messenger Astrophysics: Real-time Discovery at Scale" workshop, hosted at the National Center for Supercomputing Applications, October 17-19, 2018. Highlights of this report include unanimous agreement that it is critical to accelerate the development and deployment of novel, signal-processing algorithms that use the synergy between artificial intelligence (AI) and high performance computing to maximize the potential for scientific discovery with Multi-Messenger Astrophysics. We discuss key aspects to realize this endeavor, namely (i) the design and exploitation of scalable and computationally efficient AI algorithms for Multi-Messenger Astrophysics; (ii) cyberinfrastructure requirements to numerically simulate astrophysical sources, and to process and interpret Multi-Messenger Astrophysics data; (iii) management of gravitational wave detections and triggers to enable electromagnetic and astro-particle follow-ups; (iv) a vision to harness future developments of machine and deep learning and cyberinfrastructure resources to cope with the scale of discovery in the Big Data Era; (v) and the need to build a community that brings domain experts together with data scientists on equal footing to maximize and accelerate discovery in the nascent field of Multi-Messenger Astrophysics.