 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Experimental Design for Reliable Learning of History-Dependent Constitutive Laws
Mar 12, 2026History-dependent constitutive models serve as macroscopic closures for the aggregated effects of micromechanics. Their parameters are typically learned from experimental data. With a limited experimental budget, eliciting the full range of responses needed to characterize the constitutive relation can be difficult. As a result, the data can be well explained by a range of parameter choices, leading to parameter estimates that are uncertain or unreliable. To address this issue, we propose a Bayesian optimal experimental design framework to quantify, interpret, and maximize the utility of experimental designs for reliable learning of history-dependent constitutive models. In this framework, the design utility is defined as the expected reduction in parametric uncertainty or the expected information gain. This enables in silico design optimization using simulated data and reduces the cost of physical experiments for reliable parameter identification. We introduce two approximations that make this framework practical for advanced material testing with expensive forward models and high-dimensional data: (i) a Gaussian approximation of the expected information gain, and (ii) a surrogate approximation of the Fisher information matrix. The former enables efficient design optimization and interpretation, while the latter extends this approach to batched design optimization by amortizing the cost of repeated utility evaluations. Our numerical studies of uniaxial tests for viscoelastic solids show that optimized specimen geometries and loading paths yield image and force data that significantly improve parameter identifiability relative to random designs, especially for parameters associated with memory effects.
Learning Memory and Material Dependent Constitutive Laws
Feb 08, 2025The theory of homogenization provides a systematic approach to the derivation of macroscale constitutive laws, obviating the need to repeatedly resolve complex microstructure. However, the unit cell problem that defines the constitutive model is typically not amenable to explicit evaluation. It is therefore of interest to learn constitutive models from data generated by the unit cell problem. Many viscoelastic and elastoviscoplastic materials are characterized by memory-dependent constitutive laws. In order to amortize the computational investment in finding such memory-dependent constitutive laws, it is desirable to learn their dependence on the material microstructure. While prior work has addressed learning memory dependence and material dependence separately, their joint learning has not been considered. This paper focuses on the joint learning problem and proposes a novel neural operator framework to address it. In order to provide firm foundations, the homogenization problem for linear Kelvin-Voigt viscoelastic materials is studied. The theoretical properties of the cell problem in this Kelvin-Voigt setting are used to motivate the proposed general neural operator framework; these theoretical properties are also used to prove a universal approximation theorem for the learned macroscale constitutive model. This formulation of learnable constitutive models is then deployed beyond the Kelvin-Voigt setting. Numerical experiments are presented showing that the resulting data-driven methodology accurately learns history- and microstructure-dependent linear viscoelastic and nonlinear elastoviscoplastic constitutive models, and numerical results also demonstrate that the resulting constitutive models can be deployed in macroscale simulation of material deformation.
Learning Homogenization for Elliptic Operators
Jul 07, 2023



Multiscale partial differential equations (PDEs) arise in various applications, and several schemes have been developed to solve them efficiently. Homogenization theory is a powerful methodology that eliminates the small-scale dependence, resulting in simplified equations that are computationally tractable. In the field of continuum mechanics, homogenization is crucial for deriving constitutive laws that incorporate microscale physics in order to formulate balance laws for the macroscopic quantities of interest. However, obtaining homogenized constitutive laws is often challenging as they do not in general have an analytic form and can exhibit phenomena not present on the microscale. In response, data-driven learning of the constitutive law has been proposed as appropriate for this task. However, a major challenge in data-driven learning approaches for this problem has remained unexplored: the impact of discontinuities and corner interfaces in the underlying material. These discontinuities in the coefficients affect the smoothness of the solutions of the underlying equations. Given the prevalence of discontinuous materials in continuum mechanics applications, it is important to address the challenge of learning in this context; in particular to develop underpinning theory to establish the reliability of data-driven methods in this scientific domain. The paper addresses this unexplored challenge by investigating the learnability of homogenized constitutive laws for elliptic operators in the presence of such complexities. Approximation theory is presented, and numerical experiments are performed which validate the theory for the solution operator defined by the cell-problem arising in homogenization for elliptic PDEs.
Neural Operator: Learning Maps Between Function Spaces
Sep 06, 2021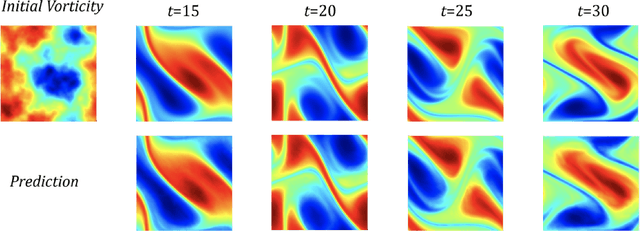
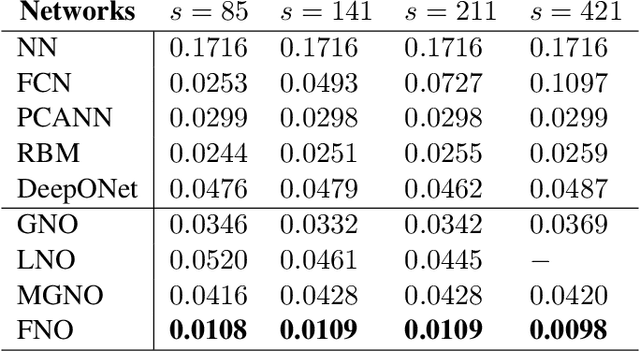
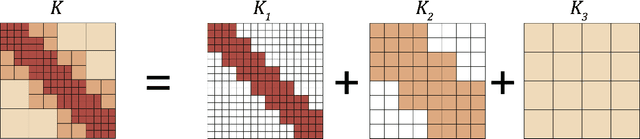
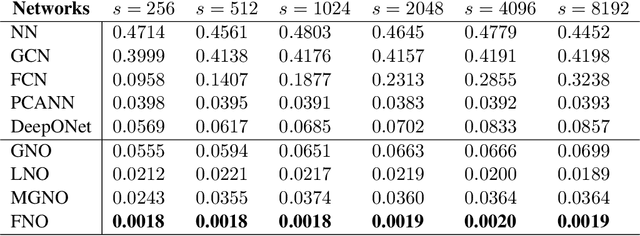
The classical development of neural networks has primarily focused on learning mappings between finite dimensional Euclidean spaces or finite sets. We propose a generalization of neural networks tailored to learn operators mapping between infinite dimensional function spaces. We formulate the approximation of operators by composition of a class of linear integral operators and nonlinear activation functions, so that the composed operator can approximate complex nonlinear operators. We prove a universal approximation theorem for our construction. Furthermore, we introduce four classes of operator parameterizations: graph-based operators, low-rank operators, multipole graph-based operators, and Fourier operators and describe efficient algorithms for computing with each one. The proposed neural operators are resolution-invariant: they share the same network parameters between different discretizations of the underlying function spaces and can be used for zero-shot super-resolutions. Numerically, the proposed models show superior performance compared to existing machine learning based methodologies on Burgers' equation, Darcy flow, and the Navier-Stokes equation, while being several order of magnitude faster compared to conventional PDE solvers.
Markov Neural Operators for Learning Chaotic Systems
Jun 13, 2021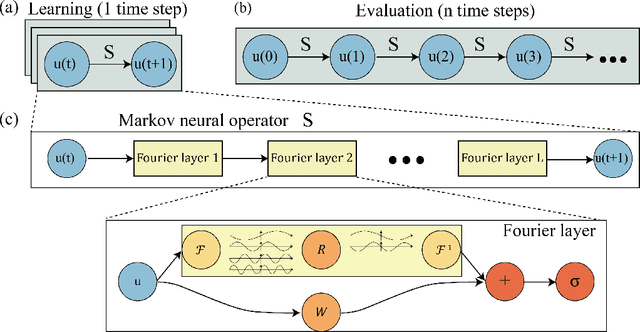
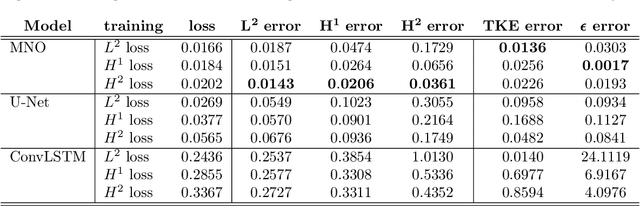
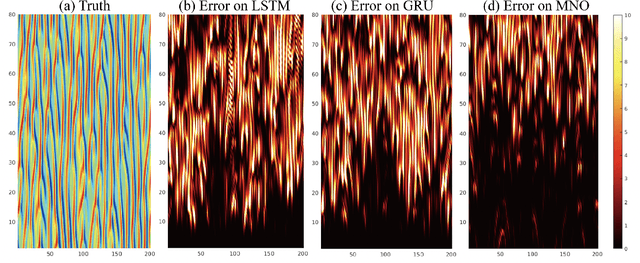
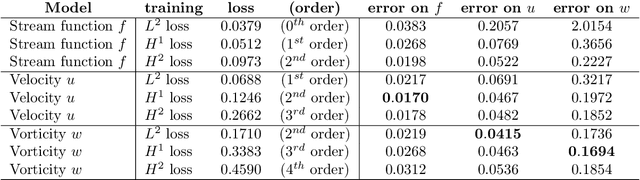
Chaotic systems are notoriously challenging to predict because of their instability. Small errors accumulate in the simulation of each time step, resulting in completely different trajectories. However, the trajectories of many prominent chaotic systems live in a low-dimensional subspace (attractor). If the system is Markovian, the attractor is uniquely determined by the Markov operator that maps the evolution of infinitesimal time steps. This makes it possible to predict the behavior of the chaotic system by learning the Markov operator even if we cannot predict the exact trajectory. Recently, a new framework for learning resolution-invariant solution operators for PDEs was proposed, known as neural operators. In this work, we train a Markov neural operator (MNO) with only the local one-step evolution information. We then compose the learned operator to obtain the global attractor and invariant measure. Such a Markov neural operator forms a discrete semigroup and we empirically observe that does not collapse or blow up. Experiments show neural operators are more accurate and stable compared to previous methods on chaotic systems such as the Kuramoto-Sivashinsky and Navier-Stokes equations.
Fourier Neural Operator for Parametric Partial Differential Equations
Oct 18, 2020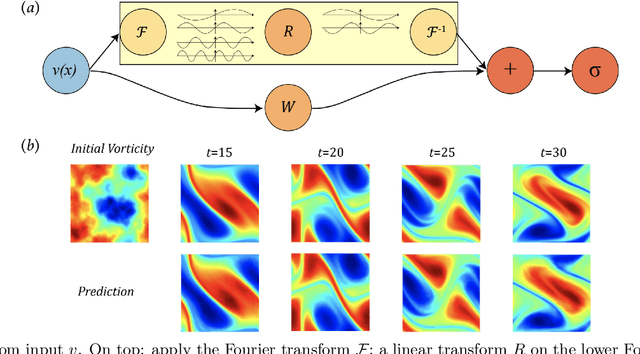
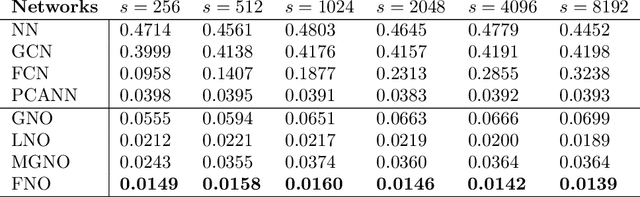
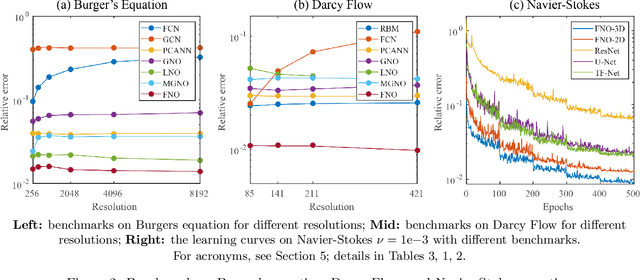
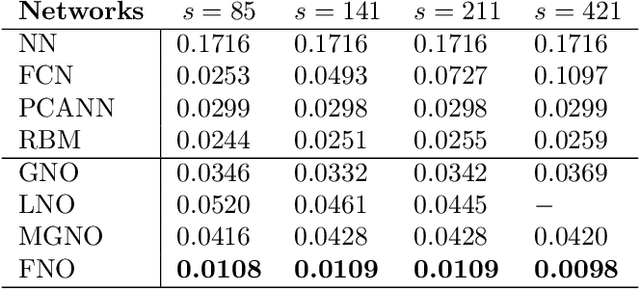
The classical development of neural networks has primarily focused on learning mappings between finite-dimensional Euclidean spaces. Recently, this has been generalized to neural operators that learn mappings between function spaces. For partial differential equations (PDEs), neural operators directly learn the mapping from any functional parametric dependence to the solution. Thus, they learn an entire family of PDEs, in contrast to classical methods which solve one instance of the equation. In this work, we formulate a new neural operator by parameterizing the integral kernel directly in Fourier space, allowing for an expressive and efficient architecture. We perform experiments on Burgers' equation, Darcy flow, and the Navier-Stokes equation (including the turbulent regime). Our Fourier neural operator shows state-of-the-art performance compared to existing neural network methodologies and it is up to three orders of magnitude faster compared to traditional PDE solvers.
Multipole Graph Neural Operator for Parametric Partial Differential Equations
Jun 16, 2020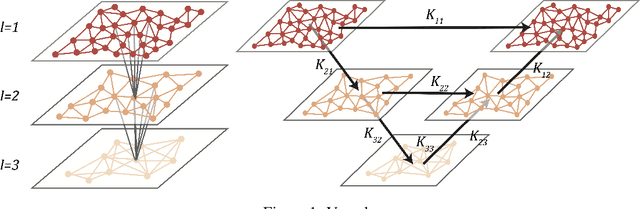
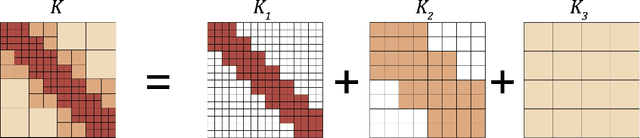
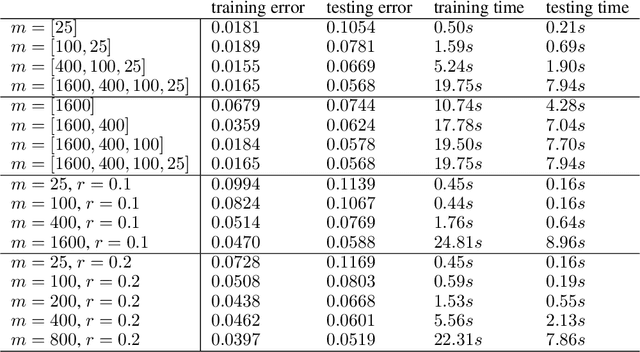
One of the main challenges in using deep learning-based methods for simulating physical systems and solving partial differential equations (PDEs) is formulating physics-based data in the desired structure for neural networks. Graph neural networks (GNNs) have gained popularity in this area since graphs offer a natural way of modeling particle interactions and provide a clear way of discretizing the continuum models. However, the graphs constructed for approximating such tasks usually ignore long-range interactions due to unfavorable scaling of the computational complexity with respect to the number of nodes. The errors due to these approximations scale with the discretization of the system, thereby not allowing for generalization under mesh-refinement. Inspired by the classical multipole methods, we propose a novel multi-level graph neural network framework that captures interaction at all ranges with only linear complexity. Our multi-level formulation is equivalent to recursively adding inducing points to the kernel matrix, unifying GNNs with multi-resolution matrix factorization of the kernel. Experiments confirm our multi-graph network learns discretization-invariant solution operators to PDEs and can be evaluated in linear time.
Model Reduction and Neural Networks for Parametric PDEs
May 07, 2020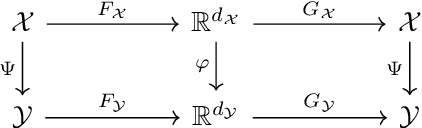

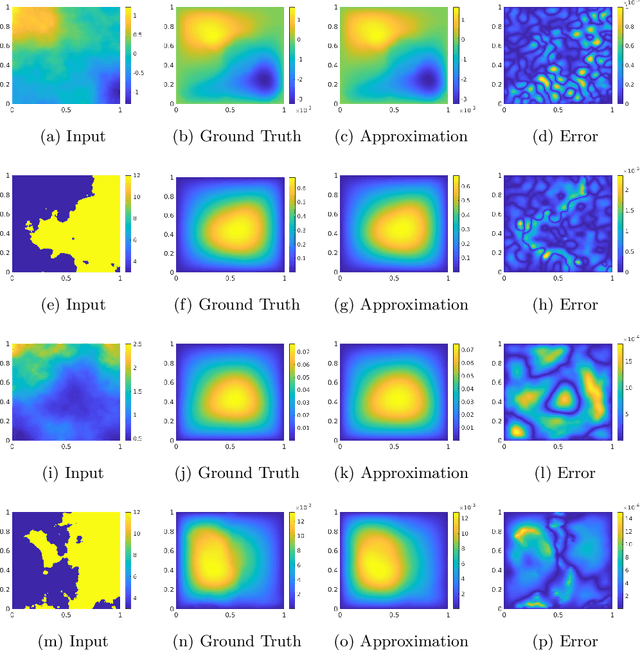
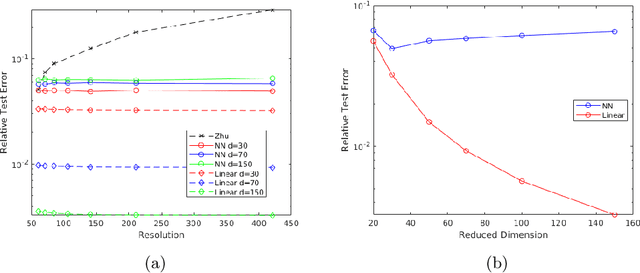
We develop a general framework for data-driven approximation of input-output maps between infinite-dimensional spaces. The proposed approach is motivated by the recent successes of neural networks and deep learning, in combination with ideas from model reduction. This combination results in a neural network approximation which, in principle, is defined on infinite-dimensional spaces and, in practice, is robust to the dimension of finite-dimensional approximations of these spaces required for computation. For a class of input-output maps, and suitably chosen probability measures on the inputs, we prove convergence of the proposed approximation methodology. Numerically we demonstrate the effectiveness of the method on a class of parametric elliptic PDE problems, showing convergence and robustness of the approximation scheme with respect to the size of the discretization, and compare our method with existing algorithms from the literature.
Neural Operator: Graph Kernel Network for Partial Differential Equations
Mar 07, 2020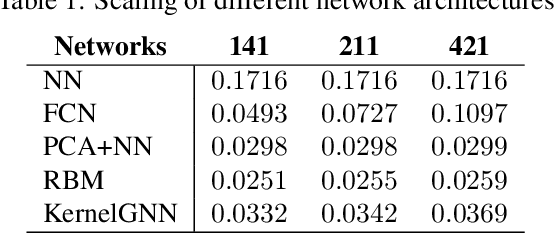
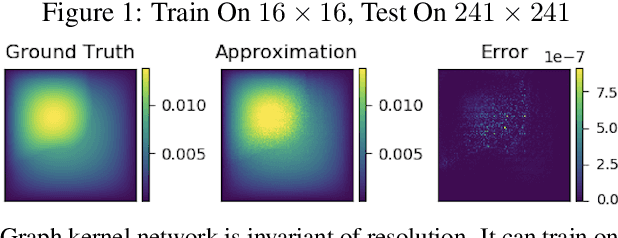

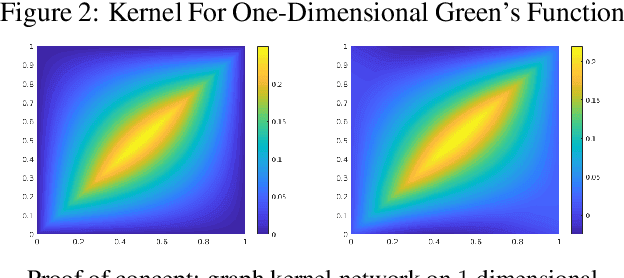
The classical development of neural networks has been primarily for mappings between a finite-dimensional Euclidean space and a set of classes, or between two finite-dimensional Euclidean spaces. The purpose of this work is to generalize neural networks so that they can learn mappings between infinite-dimensional spaces (operators). The key innovation in our work is that a single set of network parameters, within a carefully designed network architecture, may be used to describe mappings between infinite-dimensional spaces and between different finite-dimensional approximations of those spaces. We formulate approximation of the infinite-dimensional mapping by composing nonlinear activation functions and a class of integral operators. The kernel integration is computed by message passing on graph networks. This approach has substantial practical consequences which we will illustrate in the context of mappings between input data to partial differential equations (PDEs) and their solutions. In this context, such learned networks can generalize among different approximation methods for the PDE (such as finite difference or finite element methods) and among approximations corresponding to different underlying levels of resolution and discretization. Experiments confirm that the proposed graph kernel network does have the desired properties and show competitive performance compared to the state of the art solvers.