 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Operator: Learning Maps Between Function Spaces
Paper and Code
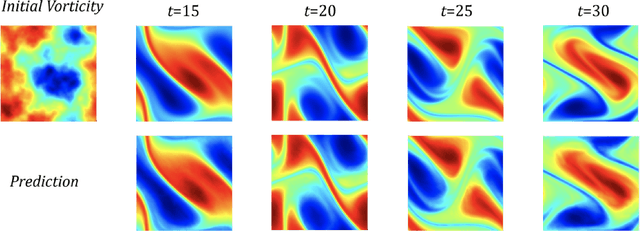
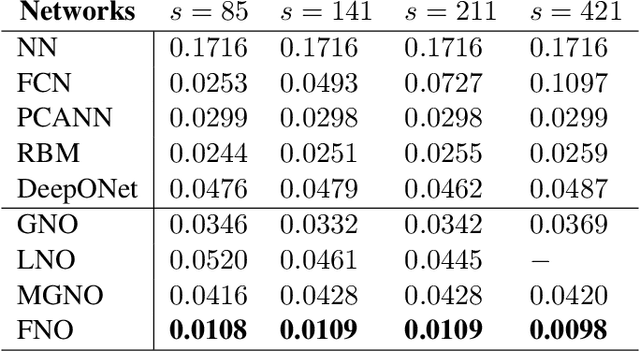
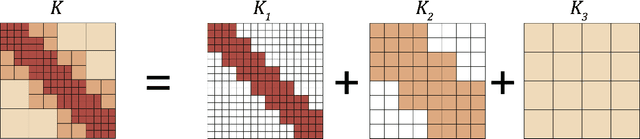
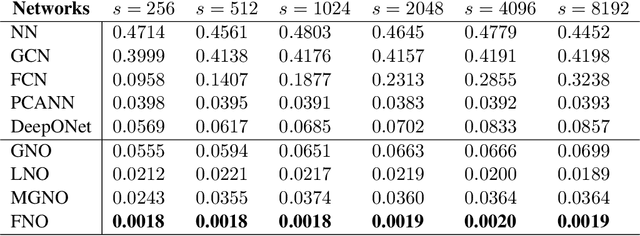
The classical development of neural networks has primarily focused on learning mappings between finite dimensional Euclidean spaces or finite sets. We propose a generalization of neural networks tailored to learn operators mapping between infinite dimensional function spaces. We formulate the approximation of operators by composition of a class of linear integral operators and nonlinear activation functions, so that the composed operator can approximate complex nonlinear operators. We prove a universal approximation theorem for our construction. Furthermore, we introduce four classes of operator parameterizations: graph-based operators, low-rank operators, multipole graph-based operators, and Fourier operators and describe efficient algorithms for computing with each one. The proposed neural operators are resolution-invariant: they share the same network parameters between different discretizations of the underlying function spaces and can be used for zero-shot super-resolutions. Numerically, the proposed models show superior performance compared to existing machine learning based methodologies on Burgers' equation, Darcy flow, and the Navier-Stokes equation, while being several order of magnitude faster compared to conventional PDE solvers.