 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISTA: Monocular Segmentation-Based Mapping for Appearance and View-Invariant Global Localization
Jul 15, 2025Global localization is critical for autonomous navigation, particularly in scenarios where an agent must localize within a map generated in a different session or by another agent, as agents often have no prior knowledge about the correlation between reference frames. However, this task remains challenging in unstructured environments due to appearance changes induced by viewpoint variation, seasonal changes, spatial aliasing, and occlusions -- known failure modes for traditional place recognition methods. To address these challenges, we propose VISTA (View-Invariant Segmentation-Based Tracking for Frame Alignment), a novel open-set, monocular global localization framework that combines: 1) a front-end, object-based, segmentation and tracking pipeline, followed by 2) a submap correspondence search, which exploits geometric consistencies between environment maps to align vehicle reference frames. VISTA enables consistent localization across diverse camera viewpoints and seasonal changes, without requiring any domain-specific training or finetuning. We evaluate VISTA on seasonal and oblique-angle aerial datasets, achieving up to a 69% improvement in recall over baseline methods. Furthermore, we maintain a compact object-based map that is only 0.6% the size of the most memory-conservative baseline, making our approach capable of real-time implementation on resource-constrained platforms.
Collective Online Learning via Decentralized Gaussian Processes in Massive Multi-Agent Systems
May 23, 2018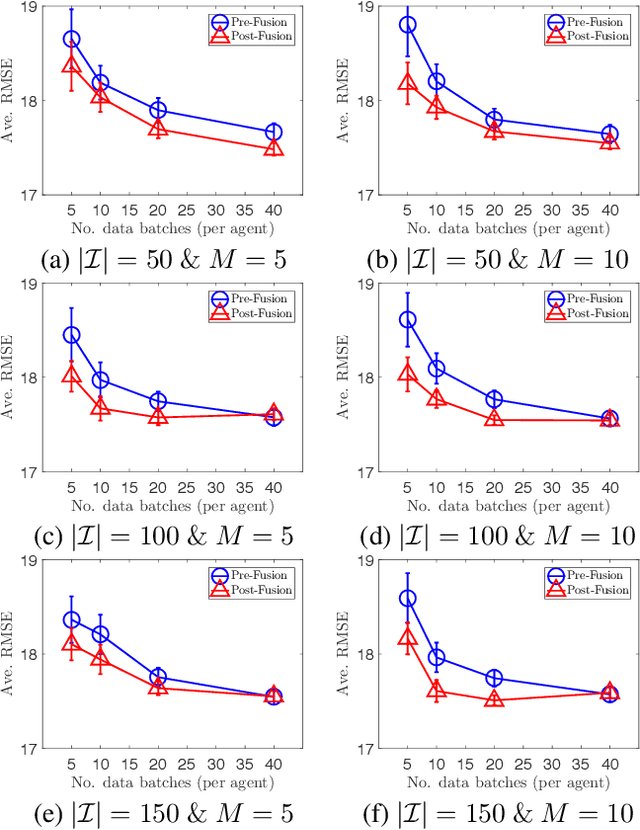
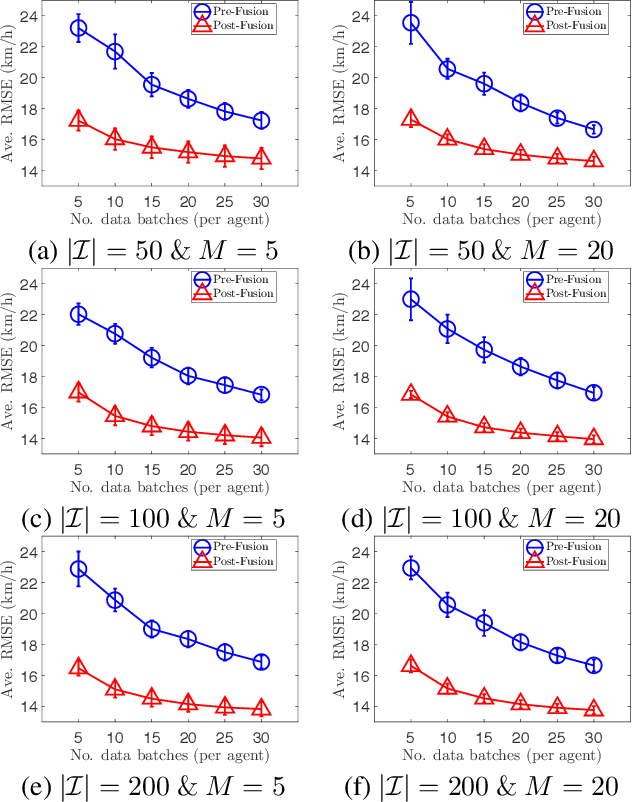
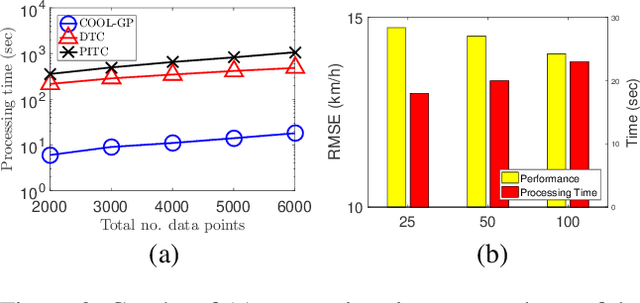
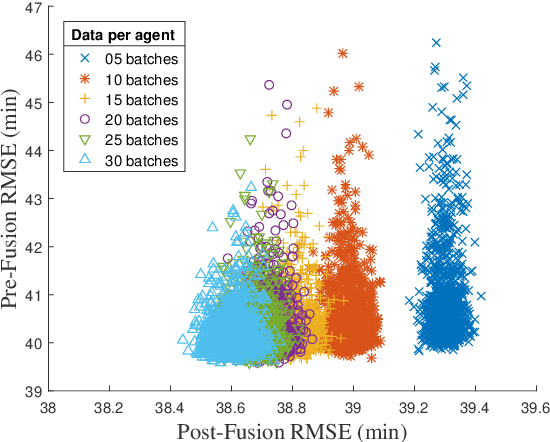
Distributed machine learning (ML) is a modern computation paradigm that divides its workload into independent tasks that can be simultaneously achieved by multiple machines (i.e., agents) for better scalability. However, a typical distributed system is usually implemented with a central server that collects data statistics from multiple independent machines operating on different subsets of data to build a global analytic model. This centralized communication architecture however exposes a single choke point for operational failure and places severe bottlenecks on the server's communication and computation capacities as it has to process a growing volume of communication from a crowd of learning agents. To mitigate these bottlenecks, this paper introduces a novel Collective Online Learning Gaussian Process framework for massive distributed systems that allows each agent to build its local model, which can be exchanged and combined efficiently with others via peer-to-peer communication to converge on a global model of higher quality. Finally, our empirical results consistently demonstrate the efficiency of our framework on both synthetic and real-world datasets.
Near-Optimal Adversarial Policy Switching for Decentralized Asynchronous Multi-Agent Systems
Oct 17, 2017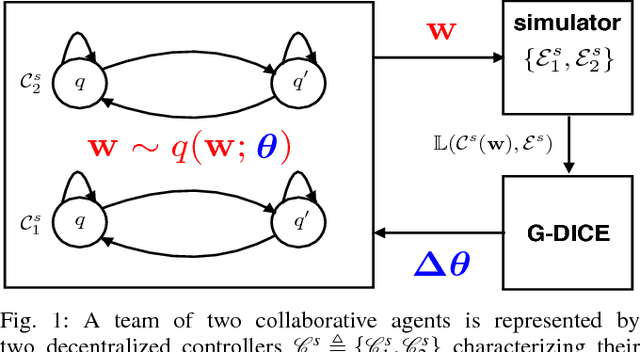
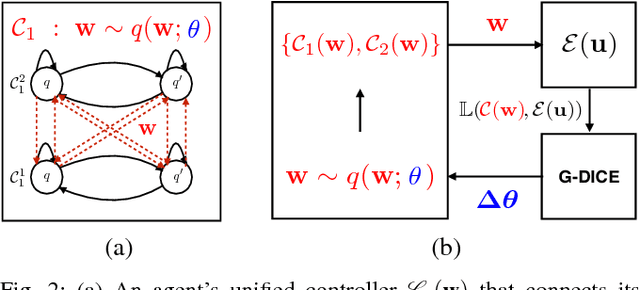
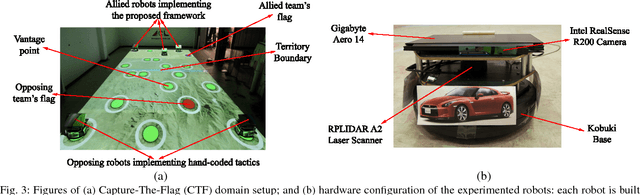
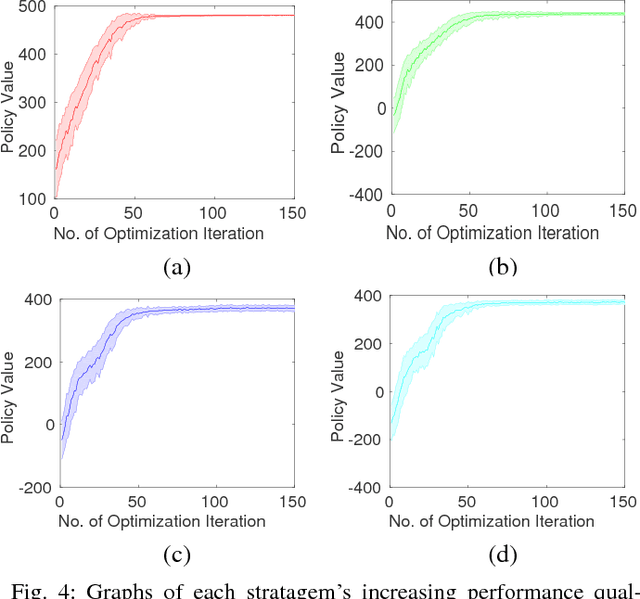
A key challenge in multi-robot and multi-agent systems is generating solutions that are robust to other self-interested or even adversarial parties who actively try to prevent the agents from achieving their goals. The practicality of existing works addressing this challenge is limited to only small-scale synchronous decision-making scenarios or a single agent planning its best response against a single adversary with fixed, procedurally characterized strategies. In contrast this paper considers a more realistic class of problems where a team of asynchronous agents with limited observation and communication capabilities need to compete against multiple strategic adversaries with changing strategies. This problem necessitates agents that can coordinate to detect changes in adversary strategies and plan the best response accordingly. Our approach first optimizes a set of stratagems that represent these best responses. These optimized stratagems are then integrated into a unified policy that can detect and respond when the adversaries change their strategies. The near-optimality of the proposed framework is established theoretically as well as demonstrated empirically in simulation and hardware.
Dynamic Clustering Algorithms via Small-Variance Analysis of Markov Chain Mixture Models
Jul 26, 2017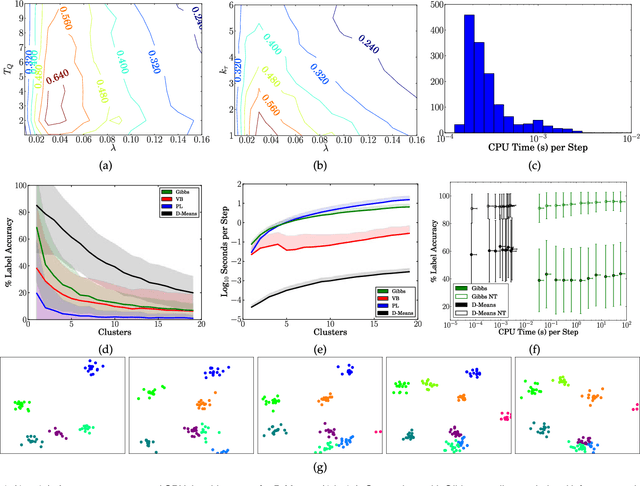

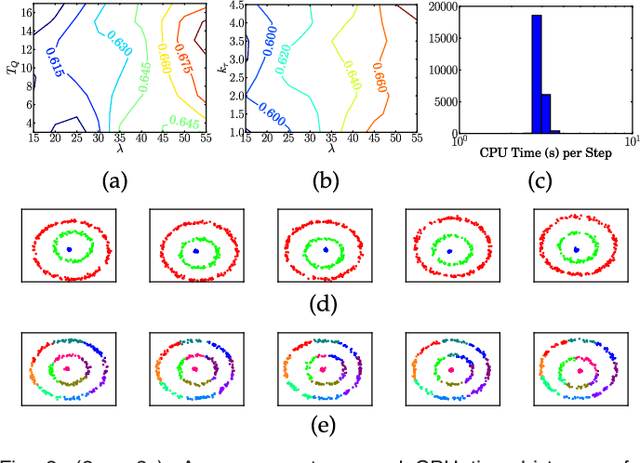
Bayesian nonparametrics are a class of probabilistic models in which the model size is inferred from data. A recently developed methodology in this field is small-variance asymptotic analysis, a mathematical technique for deriving learning algorithms that capture much of the flexibility of Bayesian nonparametric inference algorithms, but are simpler to implement and less computationally expensive. Past work on small-variance analysis of Bayesian nonparametric inference algorithms has exclusively considered batch models trained on a single, static dataset, which are incapable of capturing time evolution in the latent structure of the data. This work presents a small-variance analysis of the maximum a posteriori filtering problem for a temporally varying mixture model with a Markov dependence structure, which captures temporally evolving clusters within a dataset. Two clustering algorithms result from the analysis: D-Means, an iterative clustering algorithm for linearly separable, spherical clusters; and SD-Means, a spectral clustering algorithm derived from a kernelized, relaxed version of the clustering problem. Empirical results from experiments demonstrate the advantages of using D-Means and SD-Means over contemporary clustering algorithms, in terms of both computational cost and clustering accuracy.
SLAM with Objects using a Nonparametric Pose Graph
Apr 19, 2017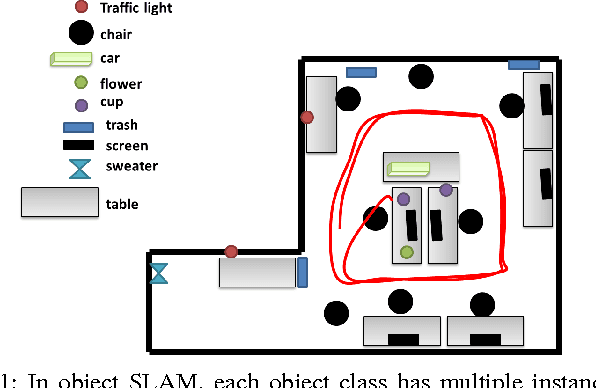
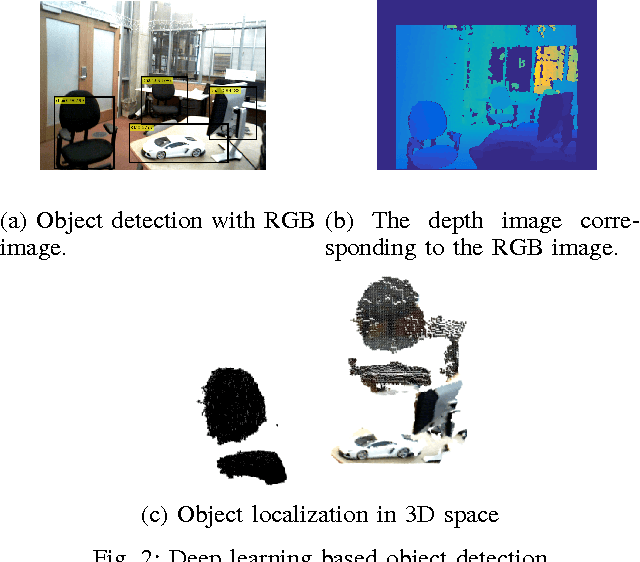
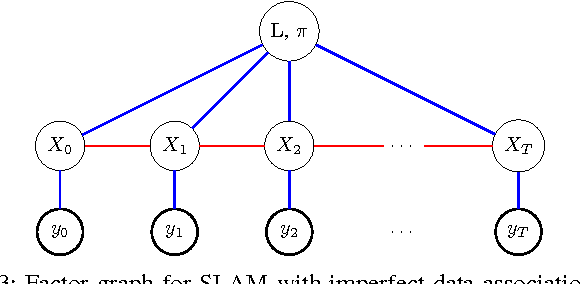
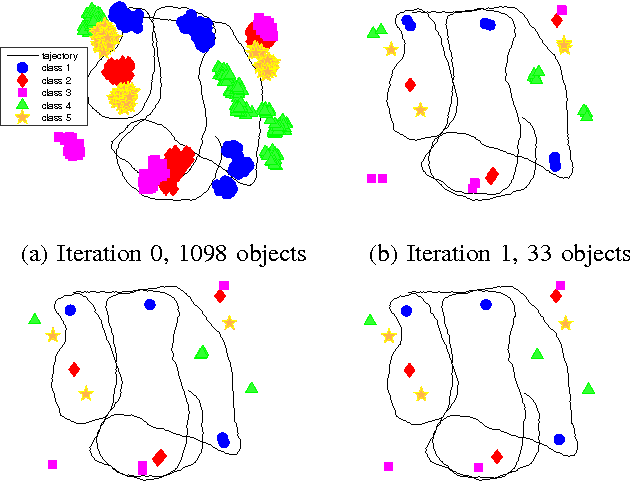
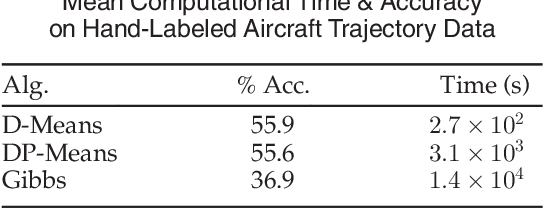
Mapping and self-localization in unknown environments are fundamental capabilities in many robotic applications. These tasks typically involve the identification of objects as unique features or landmarks, which requires the objects both to be detected and then assigned a unique identifier that can be maintained when viewed from different perspectives and in different images. The \textit{data association} and \textit{simultaneous localization and mapping} (SLAM) problems are, individually, well-studied in the literature. But these two problems are inherently tightly coupled, and that has not been well-addressed. Without accurate SLAM, possible data associations are combinatorial and become intractable easily. Without accurate data association, the error of SLAM algorithms diverge easily. This paper proposes a novel nonparametric pose graph that models data association and SLAM in a single framework. An algorithm is further introduced to alternate between inferring data association and performing SLAM. Experimental results show that our approach has the new capability of associating object detections and localizing objects at the same time, leading to significantly better performance on both the data association and SLAM problems than achieved by considering only one and ignoring imperfections in the other.
Information-based Active SLAM via Topological Feature Graphs
Aug 29, 2016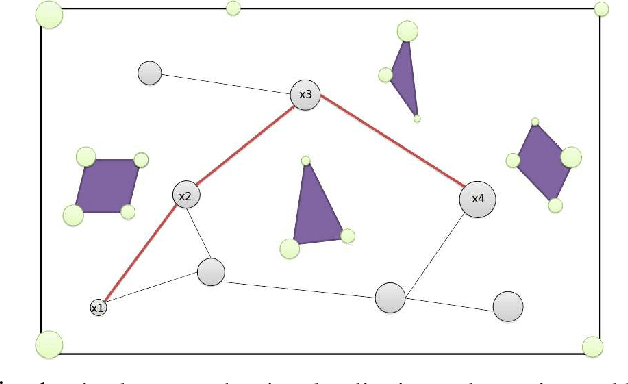

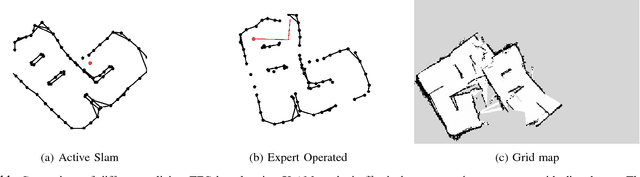
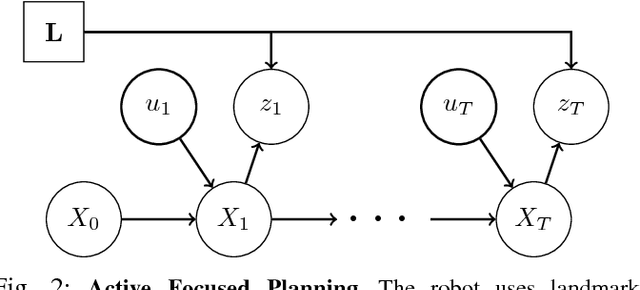
Active SLAM is the task of actively planning robot paths while simultaneously building a map and localizing within. Existing work has focused on planning paths with occupancy grid maps, which do not scale well and suffer from long term drift. This work proposes a Topological Feature Graph (TFG) representation that scales well and develops an active SLAM algorithm with it. The TFG uses graphical models, which utilize independences between variables, and enables a unified quantification of exploration and exploitation gains with a single entropy metric. Hence, it facilitates a natural and principled balance between map exploration and refinement. A probabilistic roadmap path-planner is used to generate robot paths in real time. Experimental results demonstrate that the proposed approach achieves better accuracy than a standard grid-map based approach while requiring orders of magnitude less computation and memory resources.
Batch-iFDD for Representation Expansion in Large MDPs
Sep 26, 2013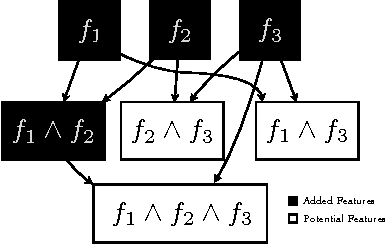
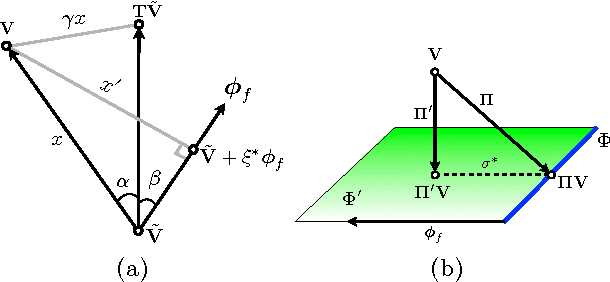
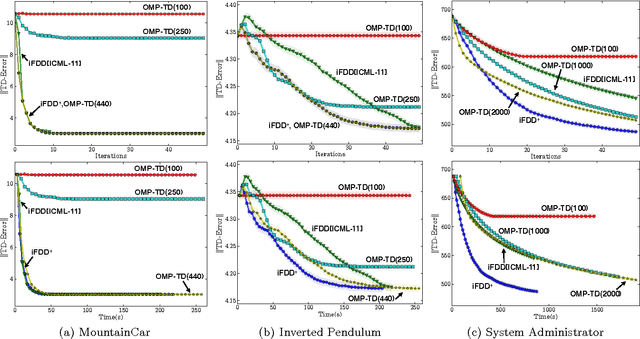
Matching pursuit (MP) methods are a promising class of feature construction algorithms for value function approximation. Yet existing MP methods require creating a pool of potential features, mandating expert knowledge or enumeration of a large feature pool, both of which hinder scalability. This paper introduces batch incremental feature dependency discovery (Batch-iFDD) as an MP method that inherits a provable convergence property. Additionally, Batch-iFDD does not require a large pool of features, leading to lower computational complexity. Empirical policy evaluation results across three domains with up to one million states highlight the scalability of Batch-iFDD over the previous state of the art MP algorithm.