 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-Optimal Adversarial Policy Switching for Decentralized Asynchronous Multi-Agent Systems
Oct 17, 2017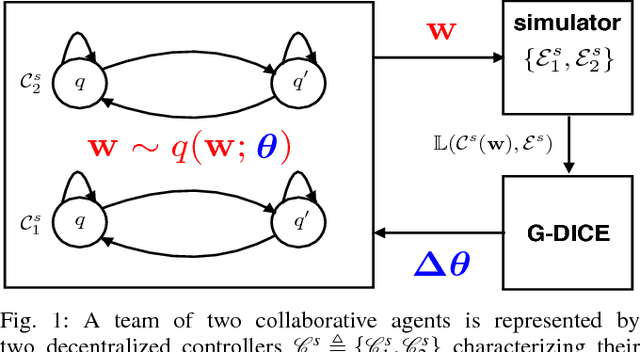
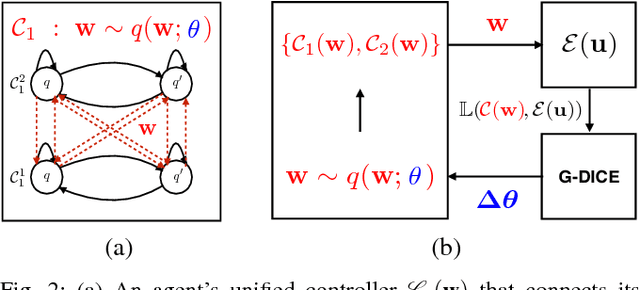
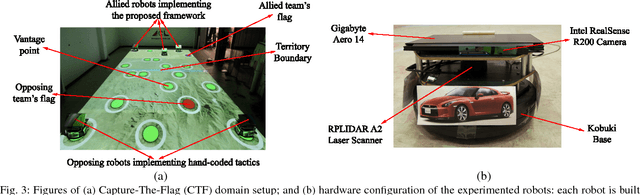
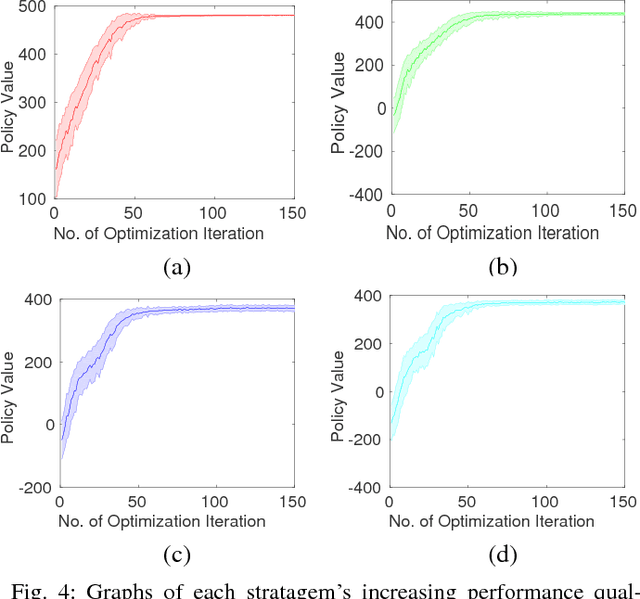
A key challenge in multi-robot and multi-agent systems is generating solutions that are robust to other self-interested or even adversarial parties who actively try to prevent the agents from achieving their goals. The practicality of existing works addressing this challenge is limited to only small-scale synchronous decision-making scenarios or a single agent planning its best response against a single adversary with fixed, procedurally characterized strategies. In contrast this paper considers a more realistic class of problems where a team of asynchronous agents with limited observation and communication capabilities need to compete against multiple strategic adversaries with changing strategies. This problem necessitates agents that can coordinate to detect changes in adversary strategies and plan the best response accordingly. Our approach first optimizes a set of stratagems that represent these best responses. These optimized stratagems are then integrated into a unified policy that can detect and respond when the adversaries change their strategies. The near-optimality of the proposed framework is established theoretically as well as demonstrated empirically in simulation and hardware.
Learning for Multi-robot Cooperation in Partially Observable Stochastic Environments with Macro-actions
Aug 18, 2017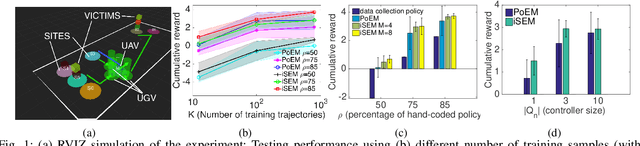



This paper presents a data-driven approach for multi-robot coordination in partially-observable domains based on Decentralized Partially Observable Markov Decision Processes (Dec-POMDPs) and macro-actions (MAs). Dec-POMDPs provide a general framework for cooperative sequential decision making under uncertainty and MAs allow temporally extended and asynchronous action execution. To date, most methods assume the underlying Dec-POMDP model is known a priori or a full simulator is available during planning time. Previous methods which aim to address these issues suffer from local optimality and sensitivity to initial conditions. Additionally, few hardware demonstrations involving a large team of heterogeneous robots and with long planning horizons exist. This work addresses these gaps by proposing an iterative sampling based Expectation-Maximization algorithm (iSEM) to learn polices using only trajectory data containing observations, MAs, and rewards. Our experiments show the algorithm is able to achieve better solution quality than the state-of-the-art learning-based methods. We implement two variants of multi-robot Search and Rescue (SAR) domains (with and without obstacles) on hardware to demonstrate the learned policies can effectively control a team of distributed robots to cooperate in a partially observable stochastic environment.