 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Role of Synthetic Data Augmentation in Controllable Human-Centric Video Generation
Apr 23, 2026Controllable human video generation aims to produce realistic videos of humans with explicitly guided motions and appearances,serving as a foundation for digital humans, animation, and embodied AI.However, the scarcity of largescale, diverse, and privacy safe human video datasets poses a major bottleneck, especially for rare identities and complex actions.Synthetic data provides a scalable and controllable alternative,yet its actual contribution to generative modeling remains underexplored due to the persistent Sim2Real gap.In this work,we systematically investigate the impact of synthetic data on controllable human video generation. We propose a diffusion-based framework that enables fine-grained control over appearance and motion while providing a unfied testbed to analyze how synthetic data interacts with real world data during training. Through extensive experiments, we reveal the complementary roles of synthetic and real data and demonstrate possible methods for efficiently selecting synthetic samples to enhance motion realism,temporal consistency,and identity preservation.Our study offers the first comprehensive exploration of synthetic data's role in human-centric video synthesis and provides practical insights for building data-efficient and generalizable generative models.
GraphRAG-IRL: Personalized Recommendation with Graph-Grounded Inverse Reinforcement Learning and LLM Re-ranking
Apr 21, 2026Personalized recommendation requires models that capture sequential user preferences while remaining robust to sparse feedback and semantic ambiguity. Recent work has explored large language models (LLMs) as recommenders and re-rankers, but pure prompt-based ranking often suffers from poor calibration, sensitivity to candidate ordering, and popularity bias. These limitations make LLMs useful semantic reasoners, but unreliable as standalone ranking engines. We present \textbf{GraphRAG-IRL}, a hybrid recommendation framework that combines graph-grounded feature construction, inverse reinforcement learning (IRL), and persona-guided LLM re-ranking. Our method constructs a heterogeneous knowledge graph over items, categories, and concepts, retrieves both individual and community preference context, and uses these signals to train a Maximum Entropy IRL model for calibrated pre-ranking. An LLM is then applied only to a short candidate list, where persona-guided prompts provide complementary semantic judgments that are fused with IRL rankings. Experiments show that GraphRAG-IRL is a strong standalone recommender: IRL-MLP with GraphRAG improves NDCG@10 by 15.7\% on MovieLens and 16.6\% on KuaiRand over supervised baselines. The results also show that IRL and GraphRAG are superadditive, with the combined gain exceeding the sum of their individual improvements. Persona-guided LLM fusion further improves ranking quality, yielding up to 16.8\% NDCG@10 improvement over the IRL-only baseline on MovieLens ml-1m, while score fusion on KuaiRand provides consistent gains of 4--6\% across LLM providers.
TAG: Target-Agnostic Guidance for Stable Object-Centric Inference in Vision-Language-Action Models
Mar 25, 2026Vision--Language--Action (VLA) policies have shown strong progress in mapping language instructions and visual observations to robotic actions, yet their reliability degrades in cluttered scenes with distractors. By analyzing failure cases, we find that many errors do not arise from infeasible motions, but from instance-level grounding failures: the policy often produces a plausible grasp trajectory that lands slightly off-target or even on the wrong object instance. To address this issue, we propose TAG (Target-Agnostic Guidance), a simple inference-time guidance mechanism that explicitly reduces distractor- and appearance-induced bias in VLA policies. Inspired by classifier-free guidance (CFG), TAG contrasts policy predictions under the original observation and an object-erased observation, and uses their difference as a residual steering signal that strengthens the influence of object evidence in the decision process. TAG does not require modifying the policy architecture and can be integrated with existing VLA policies with minimal training and inference changes. We evaluate TAG on standard manipulation benchmarks, including LIBERO, LIBERO-Plus, and VLABench, where it consistently improves robustness under clutter and reduces near-miss and wrong-object executions.
The Geometry of Transfer: Unlocking Medical Vision Manifolds for Training-Free Model Ranking
Feb 27, 2026The advent of large-scale self-supervised learning (SSL) has produced a vast zoo of medical foundation models. However, selecting optimal medical foundation models for specific segmentation tasks remains a computational bottleneck. Existing Transferability Estimation (TE) metrics, primarily designed for classification, rely on global statistical assumptions and fail to capture the topological complexity essential for dense prediction. We propose a novel Topology-Driven Transferability Estimation framework that evaluates manifold tractability rather than statistical overlap. Our approach introduces three components: (1) Global Representation Topology Divergence (GRTD), utilizing Minimum Spanning Trees to quantify feature-label structural isomorphism; (2) Local Boundary-Aware Topological Consistency (LBTC), which assesses manifold separability specifically at critical anatomical boundaries; and (3) Task-Adaptive Fusion, which dynamically integrates global and local metrics based on the semantic cardinality of the target task. Validated on the large-scale OpenMind benchmark across diverse anatomical targets and SSL foundation models, our approach significantly outperforms state-of-the-art baselines by around \textbf{31\%} relative improvement in the weighted Kendall, providing a robust, training-free proxy for efficient model selection without the cost of fine-tuning. The code will be made publicly available upon acceptance.
Stable Language Guidance for Vision-Language-Action Models
Jan 07, 2026Vision-Language-Action (VLA) models have demonstrated impressive capabilities in generalized robotic control; however, they remain notoriously brittle to linguistic perturbations. We identify a critical ``modality collapse'' phenomenon where strong visual priors overwhelm sparse linguistic signals, causing agents to overfit to specific instruction phrasings while ignoring the underlying semantic intent. To address this, we propose \textbf{Residual Semantic Steering (RSS)}, a probabilistic framework that disentangles physical affordance from semantic execution. RSS introduces two theoretical innovations: (1) \textbf{Monte Carlo Syntactic Integration}, which approximates the true semantic posterior via dense, LLM-driven distributional expansion, and (2) \textbf{Residual Affordance Steering}, a dual-stream decoding mechanism that explicitly isolates the causal influence of language by subtracting the visual affordance prior. Theoretical analysis suggests that RSS effectively maximizes the mutual information between action and intent while suppressing visual distractors. Empirical results across diverse manipulation benchmarks demonstrate that RSS achieves state-of-the-art robustness, maintaining performance even under adversarial linguistic perturbations.
Topology-aware Pathological Consistency Matching for Weakly-Paired IHC Virtual Staining
Jan 06, 2026Immunohistochemical (IHC) staining provides crucial molecular characterization of tissue samples and plays an indispensable role in the clinical examination and diagnosis of cancers. However, compared with the commonly used Hematoxylin and Eosin (H&E) staining, IHC staining involves complex procedures and is both time-consuming and expensive, which limits its widespread clinical use. Virtual staining converts H&E images to IHC images, offering a cost-effective alternative to clinical IHC staining. Nevertheless, using adjacent slides as ground truth often results in weakly-paired data with spatial misalignment and local deformations, hindering effective supervised learning. To address these challenges, we propose a novel topology-aware framework for H&E-to-IHC virtual staining. Specifically, we introduce a Topology-aware Consistency Matching (TACM) mechanism that employs graph contrastive learning and topological perturbations to learn robust matching patterns despite spatial misalignments, ensuring structural consistency. Furthermore, we propose a Topology-constrained Pathological Matching (TCPM) mechanism that aligns pathological positive regions based on node importance to enhance pathological consistency. Extensive experiments on two benchmarks across four staining tasks demonstrate that our method outperforms state-of-the-art approaches, achieving superior generation quality with higher clinical relevance.
MGI: Multimodal Contrastive pre-training of Genomic and Medical Imaging
Jun 02, 2024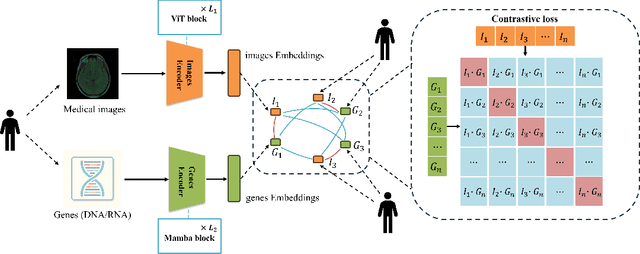
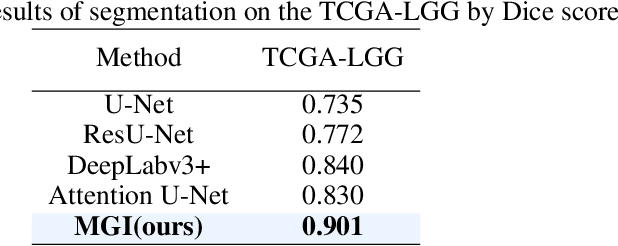
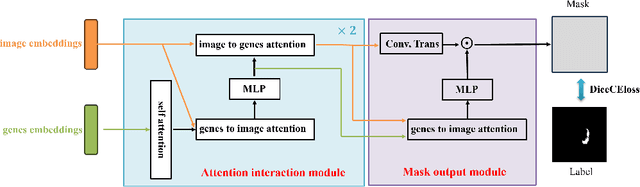
Medicine is inherently a multimodal discipline. Medical images can reflect the pathological changes of cancer and tumors, while the expression of specific genes can influence their morphological characteristics. However, most deep learning models employed for these medical tasks are unimodal, making predictions using either image data or genomic data exclusively. In this paper, we propose a multimodal pre-training framework that jointly incorporates genomics and medical images for downstream tasks. To address the issues of high computational complexity and difficulty in capturing long-range dependencies in genes sequence modeling with MLP or Transformer architectures, we utilize Mamba to model these long genomic sequences. We aligns medical images and genes using a self-supervised contrastive learning approach which combines the Mamba as a genetic encoder and the Vision Transformer (ViT) as a medical image encoder. We pre-trained on the TCGA dataset using paired gene expression data and imaging data, and fine-tuned it for downstream tumor segmentation tasks. The results show that our model outperformed a wide range of related methods.
Uncertainty-Aware Adapter: Adapting Segment Anything Model (SAM) for Ambiguous Medical Image Segmentation
Mar 19, 2024



The Segment Anything Model (SAM) gained significant success in natural image segmentation, and many methods have tried to fine-tune it to medical image segmentation. An efficient way to do so is by using Adapters, specialized modules that learn just a few parameters to tailor SAM specifically for medical images. However, unlike natural images, many tissues and lesions in medical images have blurry boundaries and may be ambiguous. Previous efforts to adapt SAM ignore this challenge and can only predict distinct segmentation. It may mislead clinicians or cause misdiagnosis, especially when encountering rare variants or situations with low model confidence. In this work, we propose a novel module called the Uncertainty-aware Adapter, which efficiently fine-tuning SAM for uncertainty-aware medical image segmentation. Utilizing a conditional variational autoencoder, we encoded stochastic samples to effectively represent the inherent uncertainty in medical imaging. We designed a new module on a standard adapter that utilizes a condition-based strategy to interact with samples to help SAM integrate uncertainty. We evaluated our method on two multi-annotated datasets with different modalities: LIDC-IDRI (lung abnormalities segmentation) and REFUGE2 (optic-cup segmentation). The experimental results show that the proposed model outperforms all the previous methods and achieves the new state-of-the-art (SOTA) on both benchmarks. We also demonstrated that our method can generate diverse segmentation hypotheses that are more realistic as well as heterogeneous.
Enhancing In-Context Learning with Answer Feedback for Multi-Span Question Answering
Jun 07, 2023Whereas the recent emergence of large language models (LLMs) like ChatGPT has exhibited impressive general performance, it still has a large gap with fully-supervised models on specific tasks such as multi-span question answering. Previous researches found that in-context learning is an effective approach to exploiting LLM, by using a few task-related labeled data as demonstration examples to construct a few-shot prompt for answering new questions. A popular implementation is to concatenate a few questions and their correct answers through simple templates, informing LLM of the desired output. In this paper, we propose a novel way of employing labeled data such that it also informs LLM of some undesired output, by extending demonstration examples with feedback about answers predicted by an off-the-shelf model, e.g., correct, incorrect, or incomplete. Experiments on three multi-span question answering datasets as well as a keyphrase extraction dataset show that our new prompting strategy consistently improves LLM's in-context learning performance.
Clues Before Answers: Generation-Enhanced Multiple-Choice QA
Apr 30, 2022
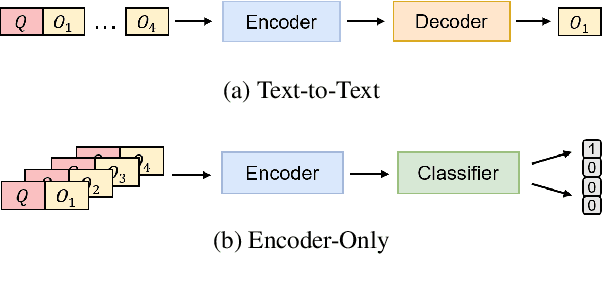
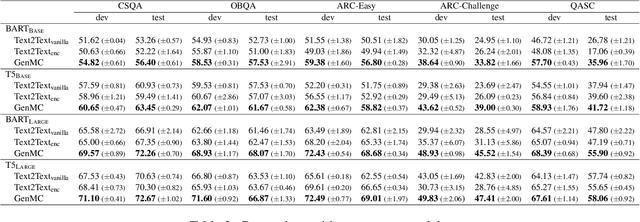
A trending paradigm for multiple-choice question answering (MCQA) is using a text-to-text framework. By unifying data in different tasks into a single text-to-text format, it trains a generative encoder-decoder model which is both powerful and universal. However, a side effect of twisting a generation target to fit the classification nature of MCQA is the under-utilization of the decoder and the knowledge that can be decoded. To exploit the generation capability and underlying knowledge of a pre-trained encoder-decoder model, in this paper, we propose a generation-enhanced MCQA model named GenMC. It generates a clue from the question and then leverages the clue to enhance a reader for MCQA. It outperforms text-to-text models on multiple MCQA datasets.