 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClues Before Answers: Generation-Enhanced Multiple-Choice QA
Apr 30, 2022
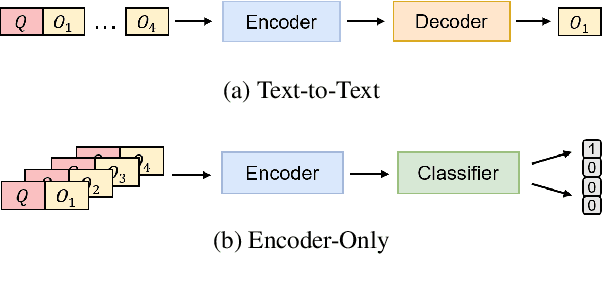
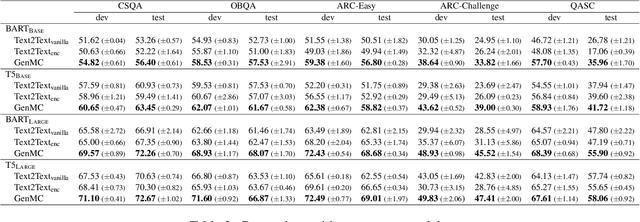
A trending paradigm for multiple-choice question answering (MCQA) is using a text-to-text framework. By unifying data in different tasks into a single text-to-text format, it trains a generative encoder-decoder model which is both powerful and universal. However, a side effect of twisting a generation target to fit the classification nature of MCQA is the under-utilization of the decoder and the knowledge that can be decoded. To exploit the generation capability and underlying knowledge of a pre-trained encoder-decoder model, in this paper, we propose a generation-enhanced MCQA model named GenMC. It generates a clue from the question and then leverages the clue to enhance a reader for MCQA. It outperforms text-to-text models on multiple MCQA datasets.
When Retriever-Reader Meets Scenario-Based Multiple-Choice Questions
Sep 05, 2021

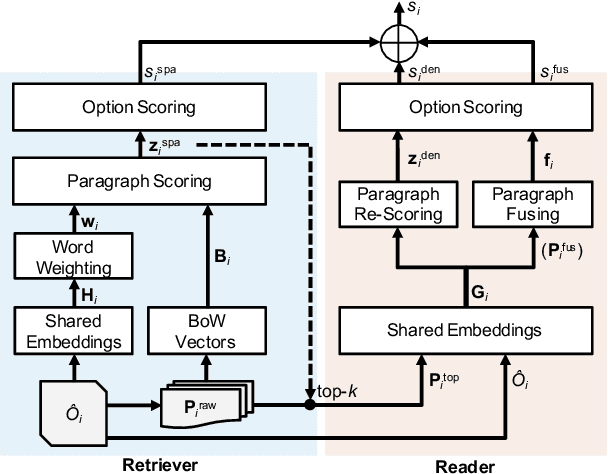

Scenario-based question answering (SQA) requires retrieving and reading paragraphs from a large corpus to answer a question which is contextualized by a long scenario description. Since a scenario contains both keyphrases for retrieval and much noise, retrieval for SQA is extremely difficult. Moreover, it can hardly be supervised due to the lack of relevance labels of paragraphs for SQA. To meet the challenge, in this paper we propose a joint retriever-reader model called JEEVES where the retriever is implicitly supervised only using QA labels via a novel word weighting mechanism. JEEVES significantly outperforms a variety of strong baselines on multiple-choice questions in three SQA datasets.