 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMirrorGuard: Toward Secure Computer-Use Agents via Simulation-to-Real Reasoning Correction
Jan 19, 2026Large foundation models are integrated into Computer Use Agents (CUAs), enabling autonomous interaction with operating systems through graphical user interfaces (GUIs) to perform complex tasks. This autonomy introduces serious security risks: malicious instructions or visual prompt injections can trigger unsafe reasoning and cause harmful system-level actions. Existing defenses, such as detection-based blocking, prevent damage but often abort tasks prematurely, reducing agent utility. In this paper, we present MirrorGuard, a plug-and-play defense framework that uses simulation-based training to improve CUA security in the real world. To reduce the cost of large-scale training in operating systems, we propose a novel neural-symbolic simulation pipeline, which generates realistic, high-risk GUI interaction trajectories entirely in a text-based simulated environment, which captures unsafe reasoning patterns and potential system hazards without executing real operations. In the simulation environment, MirrorGuard learns to intercept and rectify insecure reasoning chains of CUAs before they produce and execute unsafe actions. In real-world testing, extensive evaluations across diverse benchmarks and CUA architectures show that MirrorGuard significantly mitigates security risks. For instance, on the ByteDance UI-TARS system, it reduces the unsafe rate from 66.5% to 13.0% while maintaining a marginal false refusal rate (FRR). In contrast, the state-of-the-art GuardAgent only achieves a reduction to 53.9% and suffers from a 15.4% higher FRR. Our work proves that simulation-derived defenses can provide robust, real-world protection while maintaining the fundamental utility of the agent. Our code and model are publicly available at https://bmz-q-q.github.io/MirrorGuard/.
Geometry Attention Transformer with Position-aware LSTMs for Image Captioning
Oct 01, 2021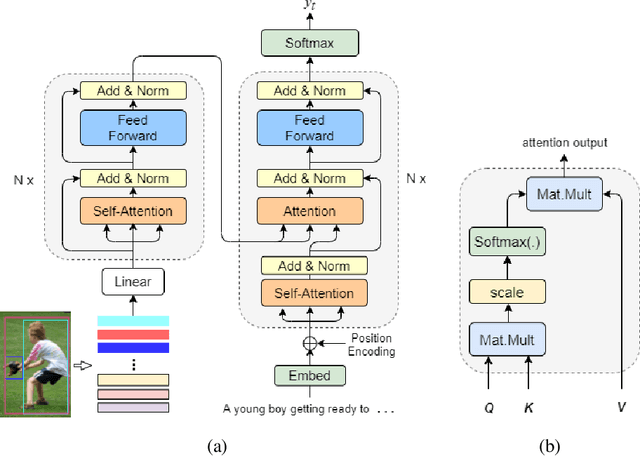
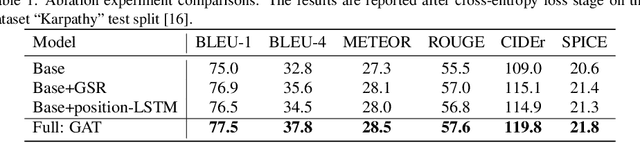
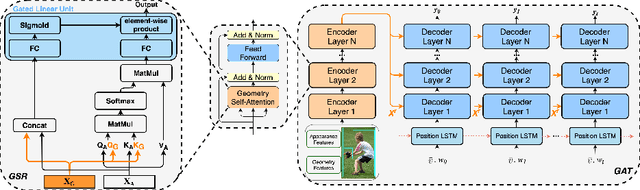

In recent years, transformer structures have been widely applied in image captioning with impressive performance. For good captioning results, the geometry and position relations of different visual objects are often thought of as crucial information. Aiming to further promote image captioning by transformers, this paper proposes an improved Geometry Attention Transformer (GAT) model. In order to further leverage geometric information, two novel geometry-aware architectures are designed respectively for the encoder and decoder in our GAT. Besides, this model includes the two work modules: 1) a geometry gate-controlled self-attention refiner, for explicitly incorporating relative spatial information into image region representations in encoding steps, and 2) a group of position-LSTMs, for precisely informing the decoder of relative word position in generating caption texts. The experiment comparisons on the datasets MS COCO and Flickr30K show that our GAT is efficient, and it could often outperform current state-of-the-art image captioning models.
When Retriever-Reader Meets Scenario-Based Multiple-Choice Questions
Sep 05, 2021

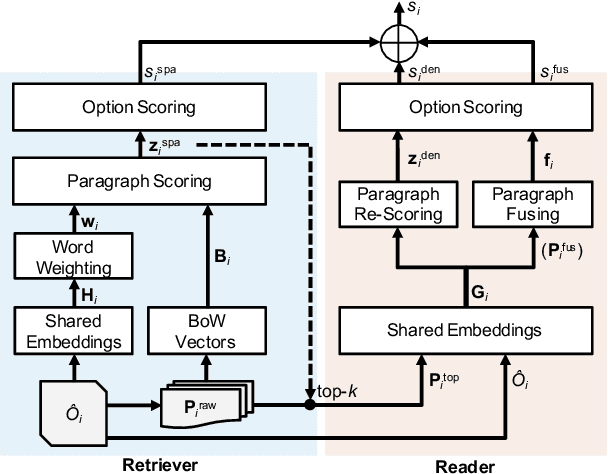

Scenario-based question answering (SQA) requires retrieving and reading paragraphs from a large corpus to answer a question which is contextualized by a long scenario description. Since a scenario contains both keyphrases for retrieval and much noise, retrieval for SQA is extremely difficult. Moreover, it can hardly be supervised due to the lack of relevance labels of paragraphs for SQA. To meet the challenge, in this paper we propose a joint retriever-reader model called JEEVES where the retriever is implicitly supervised only using QA labels via a novel word weighting mechanism. JEEVES significantly outperforms a variety of strong baselines on multiple-choice questions in three SQA datasets.
GeoSQA: A Benchmark for Scenario-based Question Answering in the Geography Domain at High School Level
Aug 20, 2019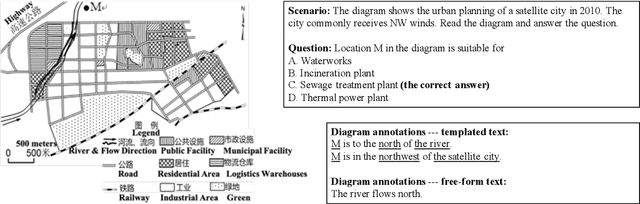

Scenario-based question answering (SQA) has attracted increasing research attention. It typically requires retrieving and integrating knowledge from multiple sources, and applying general knowledge to a specific case described by a scenario. SQA widely exists in the medical, geography, and legal domains---both in practice and in the exams. In this paper, we introduce the GeoSQA dataset. It consists of 1,981 scenarios and 4,110 multiple-choice questions in the geography domain at high school level, where diagrams (e.g., maps, charts) have been manually annotated with natural language descriptions to benefit NLP research. Benchmark results on a variety of state-of-the-art methods for question answering, textual entailment, and reading comprehension demonstrate the unique challenges presented by SQA for future research.