 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMGI: Multimodal Contrastive pre-training of Genomic and Medical Imaging
Paper and Code
Jun 02, 2024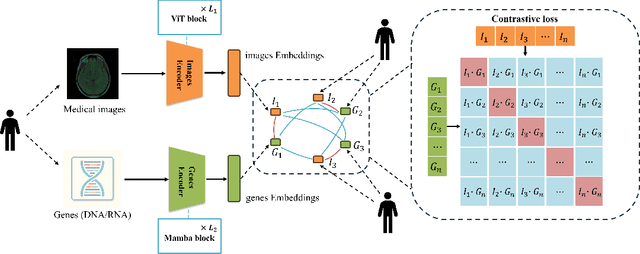
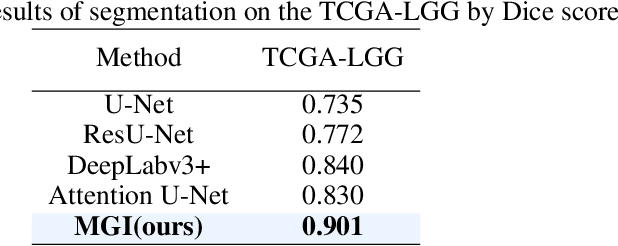
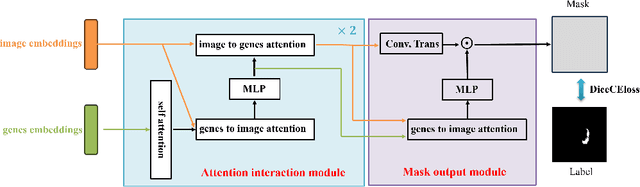
Medicine is inherently a multimodal discipline. Medical images can reflect the pathological changes of cancer and tumors, while the expression of specific genes can influence their morphological characteristics. However, most deep learning models employed for these medical tasks are unimodal, making predictions using either image data or genomic data exclusively. In this paper, we propose a multimodal pre-training framework that jointly incorporates genomics and medical images for downstream tasks. To address the issues of high computational complexity and difficulty in capturing long-range dependencies in genes sequence modeling with MLP or Transformer architectures, we utilize Mamba to model these long genomic sequences. We aligns medical images and genes using a self-supervised contrastive learning approach which combines the Mamba as a genetic encoder and the Vision Transformer (ViT) as a medical image encoder. We pre-trained on the TCGA dataset using paired gene expression data and imaging data, and fine-tuned it for downstream tumor segmentation tasks. The results show that our model outperformed a wide range of related methods.