 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Video-to-Audio Generation via Multiple Foundation Models Mapper
Sep 05, 2025Recent Video-to-Audio (V2A) generation relies on extracting semantic and temporal features from video to condition generative models. Training these models from scratch is resource intensive. Consequently, leveraging foundation models (FMs) has gained traction due to their cross-modal knowledge transfer and generalization capabilities. One prior work has explored fine-tuning a lightweight mapper network to connect a pre-trained visual encoder with a text-to-audio generation model for V2A. Inspired by this, we introduce the Multiple Foundation Model Mapper (MFM-Mapper). Compared to the previous mapper approach, MFM-Mapper benefits from richer semantic and temporal information by fusing features from dual visual encoders. Furthermore, by replacing a linear mapper with GPT-2, MFM-Mapper improves feature alignment, drawing parallels between cross-modal features mapping and autoregressive translation tasks. Our MFM-Mapper exhibits remarkable training efficiency. It achieves better performance in semantic and temporal consistency with fewer training consuming, requiring only 16\% of the training scale compared to previous mapper-based work, yet achieves competitive performance with models trained on a much larger scale.
DenoiseReID: Denoising Model for Representation Learning of Person Re-Identification
Jun 13, 2024In this paper, we propose a novel Denoising Model for Representation Learning and take Person Re-Identification (ReID) as a benchmark task, named DenoiseReID, to improve feature discriminative with joint feature extraction and denoising. In the deep learning epoch, backbones which consists of cascaded embedding layers (e.g. convolutions or transformers) to progressively extract useful features, becomes popular. We first view each embedding layer in a backbone as a denoising layer, processing the cascaded embedding layers as if we are recursively denoise features step-by-step. This unifies the frameworks of feature extraction and feature denoising, where the former progressively embeds features from low-level to high-level, and the latter recursively denoises features step-by-step. Then we design a novel Feature Extraction and Feature Denoising Fusion Algorithm (FEFDFA) and \textit{theoretically demonstrate} its equivalence before and after fusion. FEFDFA merges parameters of the denoising layers into existing embedding layers, thus making feature denoising computation-free. This is a label-free algorithm to incrementally improve feature also complementary to the label if available. Besides, it enjoys two advantages: 1) it's a computation-free and label-free plugin for incrementally improving ReID features. 2) it is complementary to the label if the label is available. Experimental results on various tasks (large-scale image classification, fine-grained image classification, image retrieval) and backbones (transformers and convolutions) show the scalability and stability of our method. Experimental results on 4 ReID datasets and various of backbones show the stability and impressive improvements. We also extend the proposed method to large-scale (ImageNet) and fine-grained (e.g. CUB200) classification tasks, similar improvements are proven.
Semantically consistent Video-to-Audio Generation using Multimodal Language Large Model
Apr 26, 2024


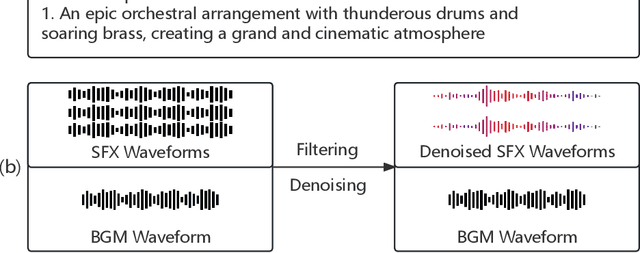
Existing works have made strides in video generation, but the lack of sound effects (SFX) and background music (BGM) hinders a complete and immersive viewer experience. We introduce a novel semantically consistent v ideo-to-audio generation framework, namely SVA, which automatically generates audio semantically consistent with the given video content. The framework harnesses the power of multimodal large language model (MLLM) to understand video semantics from a key frame and generate creative audio schemes, which are then utilized as prompts for text-to-audio models, resulting in video-to-audio generation with natural language as an interface. We show the satisfactory performance of SVA through case study and discuss the limitations along with the future research direction. The project page is available at https://huiz-a.github.io/audio4video.github.io/.
Group Feature Learning and Domain Adversarial Neural Network for aMCI Diagnosis System Based on EEG
Apr 28, 2021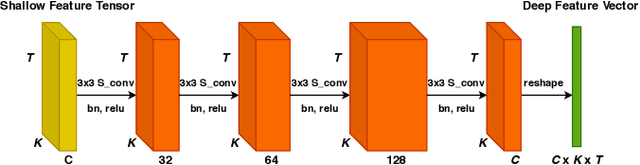
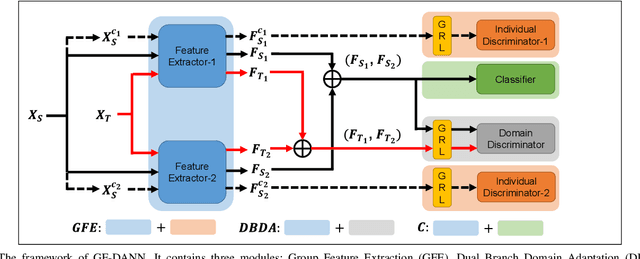
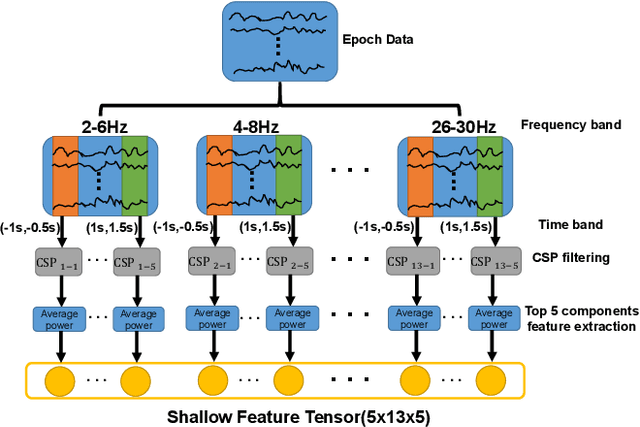
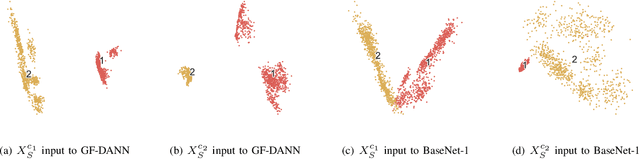
Medical diagnostic robot systems have been paid more and more attention due to its objectivity and accuracy. The diagnosis of mild cognitive impairment (MCI) is considered an effective means to prevent Alzheimer's disease (AD). Doctors diagnose MCI based on various clinical examinations, which are expensive and the diagnosis results rely on the knowledge of doctors. Therefore, it is necessary to develop a robot diagnostic system to eliminate the influence of human factors and obtain a higher accuracy rate. In this paper, we propose a novel Group Feature Domain Adversarial Neural Network (GF-DANN) for amnestic MCI (aMCI) diagnosis, which involves two important modules. A Group Feature Extraction (GFE) module is proposed to reduce individual differences by learning group-level features through adversarial learning. A Dual Branch Domain Adaptation (DBDA) module is carefully designed to reduce the distribution difference between the source and target domain in a domain adaption way. On three types of data set, GF-DANN achieves the best accuracy compared with classic machine learning and deep learning methods. On the DMS data set, GF-DANN has obtained an accuracy rate of 89.47%, and the sensitivity and specificity are 90% and 89%. In addition, by comparing three EEG data collection paradigms, our results demonstrate that the DMS paradigm has the potential to build an aMCI diagnose robot system.
Faster Person Re-Identification
Aug 16, 2020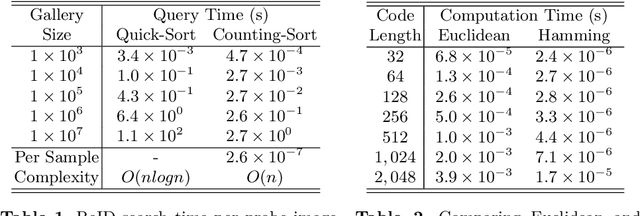
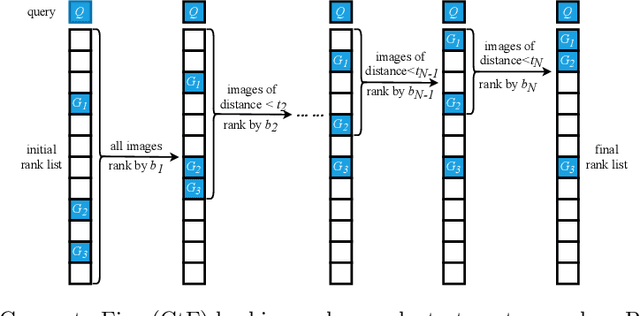
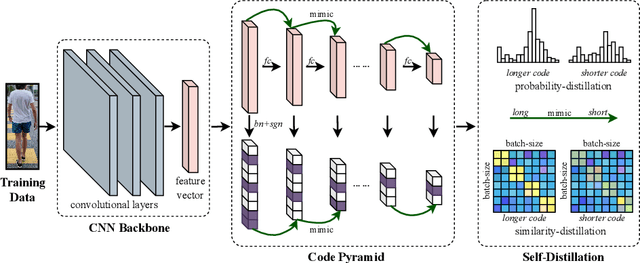
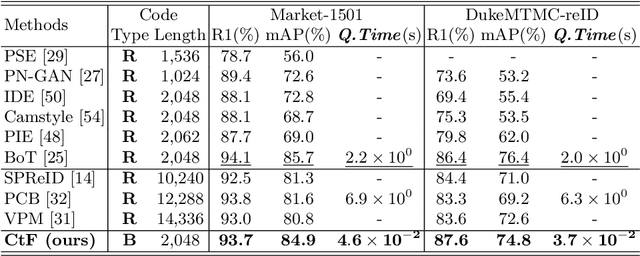
Fast person re-identification (ReID) aims to search person images quickly and accurately. The main idea of recent fast ReID methods is the hashing algorithm, which learns compact binary codes and performs fast Hamming distance and counting sort. However, a very long code is needed for high accuracy (e.g. 2048), which compromises search speed. In this work, we introduce a new solution for fast ReID by formulating a novel Coarse-to-Fine (CtF) hashing code search strategy, which complementarily uses short and long codes, achieving both faster speed and better accuracy. It uses shorter codes to coarsely rank broad matching similarities and longer codes to refine only a few top candidates for more accurate instance ReID. Specifically, we design an All-in-One (AiO) framework together with a Distance Threshold Optimization (DTO) algorithm. In AiO, we simultaneously learn and enhance multiple codes of different lengths in a single model. It learns multiple codes in a pyramid structure, and encourage shorter codes to mimic longer codes by self-distillation. DTO solves a complex threshold search problem by a simple optimization process, and the balance between accuracy and speed is easily controlled by a single parameter. It formulates the optimization target as a $F_{\beta}$ score that can be optimised by Gaussian cumulative distribution functions. Experimental results on 2 datasets show that our proposed method (CtF) is not only 8% more accurate but also 5x faster than contemporary hashing ReID methods. Compared with non-hashing ReID methods, CtF is $50\times$ faster with comparable accuracy. Code is available at https://github.com/wangguanan/light-reid.
High-Order Information Matters: Learning Relation and Topology for Occluded Person Re-Identification
Apr 02, 2020



Occluded person re-identification (ReID) aims to match occluded person images to holistic ones across dis-joint cameras. In this paper, we propose a novel framework by learning high-order relation and topology information for discriminative features and robust alignment. At first, we use a CNN backbone and a key-points estimation model to extract semantic local features. Even so, occluded images still suffer from occlusion and outliers. Then, we view the local features of an image as nodes of a graph and propose an adaptive direction graph convolutional (ADGC)layer to pass relation information between nodes. The proposed ADGC layer can automatically suppress the message-passing of meaningless features by dynamically learning di-rection and degree of linkage. When aligning two groups of local features from two images, we view it as a graph matching problem and propose a cross-graph embedded-alignment (CGEA) layer to jointly learn and embed topology information to local features, and straightly predict similarity score. The proposed CGEA layer not only take full use of alignment learned by graph matching but also re-place sensitive one-to-one matching with a robust soft one. Finally, extensive experiments on occluded, partial, and holistic ReID tasks show the effectiveness of our proposed method. Specifically, our framework significantly outperforms state-of-the-art by6.5%mAP scores on Occluded-Duke dataset.
RGB-Infrared Cross-Modality Person Re-Identification via Joint Pixel and Feature Alignment
Oct 28, 2019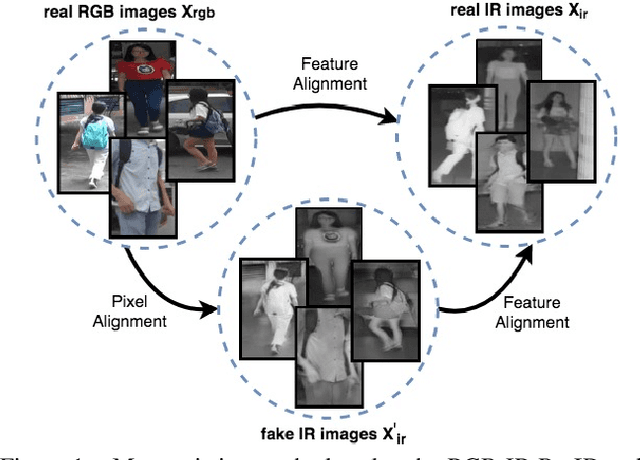
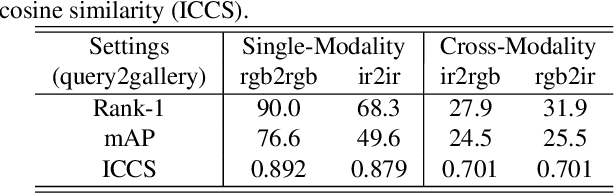
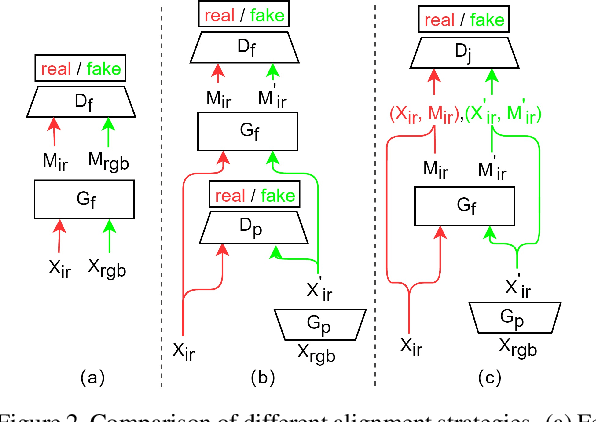
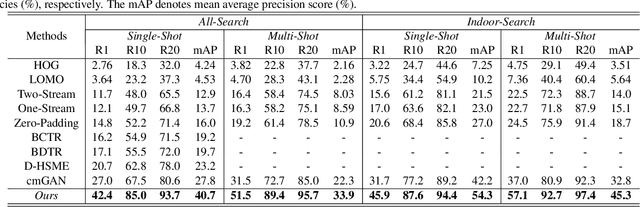
RGB-Infrared (IR) person re-identification is an important and challenging task due to large cross-modality variations between RGB and IR images. Most conventional approaches aim to bridge the cross-modality gap with feature alignment by feature representation learning. Different from existing methods, in this paper, we propose a novel and end-to-end Alignment Generative Adversarial Network (AlignGAN) for the RGB-IR RE-ID task. The proposed model enjoys several merits. First, it can exploit pixel alignment and feature alignment jointly. To the best of our knowledge, this is the first work to model the two alignment strategies jointly for the RGB-IR RE-ID problem. Second, the proposed model consists of a pixel generator, a feature generator, and a joint discriminator. By playing a min-max game among the three components, our model is able to not only alleviate the cross-modality and intra-modality variations but also learn identity-consistent features. Extensive experimental results on two standard benchmarks demonstrate that the proposed model performs favorably against state-of-the-art methods. Especially, on SYSU-MM01 dataset, our model can achieve an absolute gain of 15.4% and 12.9% in terms of Rank-1 and mAP.