 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLEX: Making the Most of the Available Data for Robotic Manipulation Pretraining
Mar 15, 2023



A rich representation is key to general robotic manipulation, but existing model architectures require a lot of data to learn it. Unfortunately, ideal robotic manipulation training data, which comes in the form of expert visuomotor demonstrations for a variety of annotated tasks, is scarce. In this work we propose PLEX, a transformer-based architecture that learns from task-agnostic visuomotor trajectories accompanied by a much larger amount of task-conditioned object manipulation videos -- a type of robotics-relevant data available in quantity. The key insight behind PLEX is that the trajectories with observations and actions help induce a latent feature space and train a robot to execute task-agnostic manipulation routines, while a diverse set of video-only demonstrations can efficiently teach the robot how to plan in this feature space for a wide variety of tasks. In contrast to most works on robotic manipulation pretraining, PLEX learns a generalizable sensorimotor multi-task policy, not just an observational representation. We also show that using relative positional encoding in PLEX's transformers further increases its data efficiency when learning from human-collected demonstrations. Experiments showcase \appr's generalization on Meta-World-v2 benchmark and establish state-of-the-art performance in challenging Robosuite environments.
Safe Reinforcement Learning by Imagining the Near Future
Feb 15, 2022

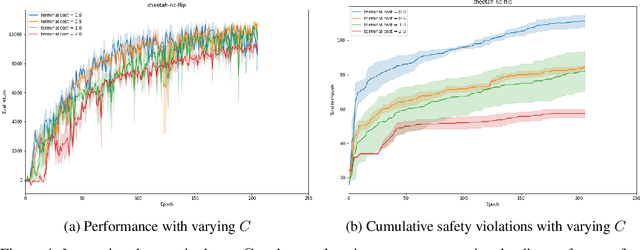
Safe reinforcement learning is a promising path toward applying reinforcement learning algorithms to real-world problems, where suboptimal behaviors may lead to actual negative consequences. In this work, we focus on the setting where unsafe states can be avoided by planning ahead a short time into the future. In this setting, a model-based agent with a sufficiently accurate model can avoid unsafe states. We devise a model-based algorithm that heavily penalizes unsafe trajectories, and derive guarantees that our algorithm can avoid unsafe states under certain assumptions. Experiments demonstrate that our algorithm can achieve competitive rewards with fewer safety violations in several continuous control tasks.
Model-based Adversarial Meta-Reinforcement Learning
Jun 16, 2020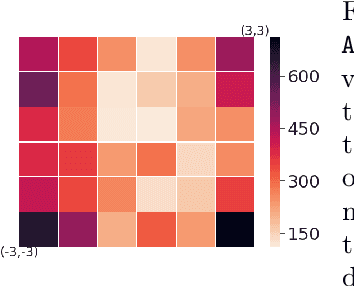
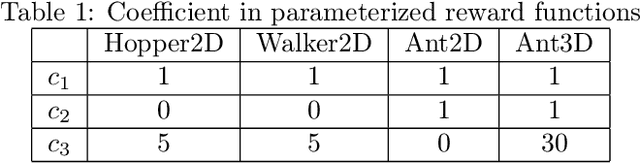
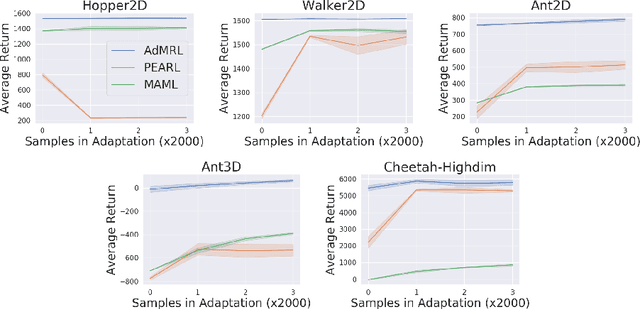
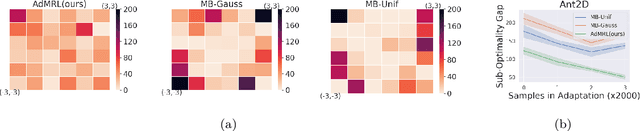
Meta-reinforcement learning (meta-RL) aims to learn from multiple training tasks the ability to adapt efficiently to unseen test tasks. Despite the success, existing meta-RL algorithms are known to be sensitive to the task distribution shift. When the test task distribution is different from the training task distribution, the performance may degrade significantly. To address this issue, this paper proposes Model-based Adversarial Meta-Reinforcement Learning (AdMRL), where we aim to minimize the worst-case sub-optimality gap -- the difference between the optimal return and the return that the algorithm achieves after adaptation -- across all tasks in a family of tasks, with a model-based approach. We propose a minimax objective and optimize it by alternating between learning the dynamics model on a fixed task and finding the adversarial task for the current model -- the task for which the policy induced by the model is maximally suboptimal. Assuming the family of tasks is parameterized, we derive a formula for the gradient of the suboptimality with respect to the task parameters via the implicit function theorem, and show how the gradient estimator can be efficiently implemented by the conjugate gradient method and a novel use of the REINFORCE estimator. We evaluate our approach on several continuous control benchmarks and demonstrate its efficacy in the worst-case performance over all tasks, the generalization power to out-of-distribution tasks, and in training and test time sample efficiency, over existing state-of-the-art meta-RL algorithms.
MOPO: Model-based Offline Policy Optimization
May 27, 2020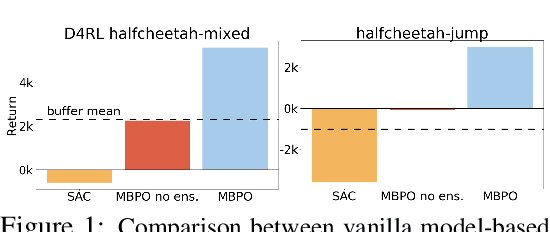
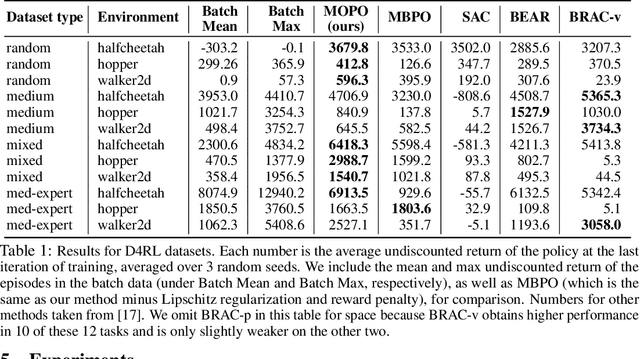
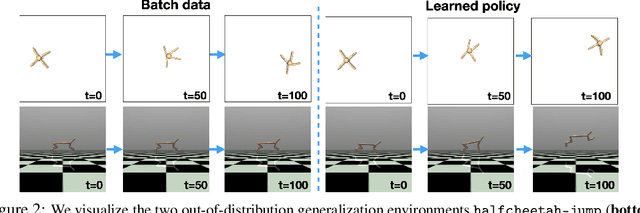

Offline reinforcement learning (RL) refers to the problem of learning policies entirely from a batch of previously collected data. This problem setting is compelling, because it offers the promise of utilizing large, diverse, previously collected datasets to acquire policies without any costly or dangerous active exploration, but it is also exceptionally difficult, due to the distributional shift between the offline training data and the learned policy. While there has been significant progress in model-free offline RL, the most successful prior methods constrain the policy to the support of the data, precluding generalization to new states. In this paper, we observe that an existing model-based RL algorithm on its own already produces significant gains in the offline setting, as compared to model-free approaches, despite not being designed for this setting. However, although many standard model-based RL methods already estimate the uncertainty of their model, they do not by themselves provide a mechanism to avoid the issues associated with distributional shift in the offline setting. We therefore propose to modify existing model-based RL methods to address these issues by casting offline model-based RL into a penalized MDP framework. We theoretically show that, by using this penalized MDP, we are maximizing a lower bound of the return in the true MDP. Based on our theoretical results, we propose a new model-based offline RL algorithm that applies the variance of a Lipschitz-regularized model as a penalty to the reward function. We find that this algorithm outperforms both standard model-based RL methods and existing state-of-the-art model-free offline RL approaches on existing offline RL benchmarks, as well as two challenging continuous control tasks that require generalizing from data collected for a different task.
A Model-based Approach for Sample-efficient Multi-task Reinforcement Learning
Jul 15, 2019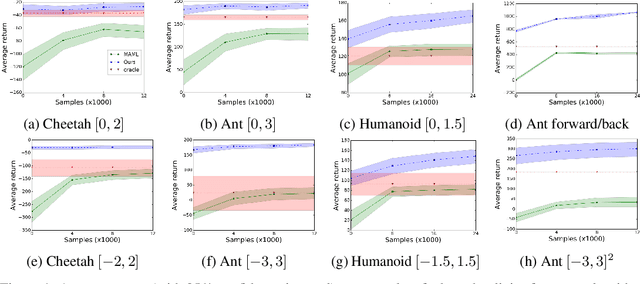
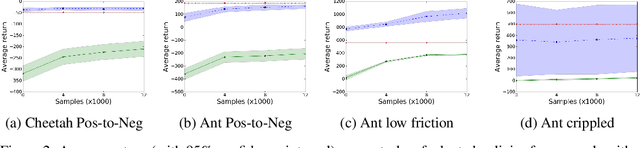
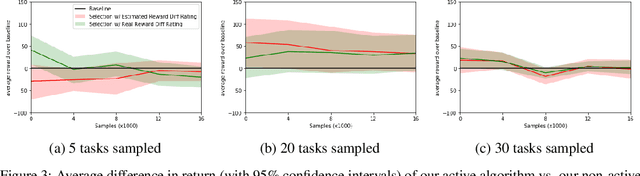
The aim of multi-task reinforcement learning is two-fold: (1) efficiently learn by training against multiple tasks and (2) quickly adapt, using limited samples, to a variety of new tasks. In this work, the tasks correspond to reward functions for environments with the same (or similar) dynamical models. We propose to learn a dynamical model during the training process and use this model to perform sample-efficient adaptation to new tasks at test time. We use significantly fewer samples by performing policy optimization only in a "virtual" environment whose transitions are given by our learned dynamical model. Our algorithm sequentially trains against several tasks. Upon encountering a new task, we first warm-up a policy on our learned dynamical model, which requires no new samples from the environment. We then adapt the dynamical model with samples from this policy in the real environment. We evaluate our approach on several continuous control benchmarks and demonstrate its efficacy over MAML, a state-of-the-art meta-learning algorithm, on these tasks.
Learning Robotic Assembly from CAD
Jul 24, 2018

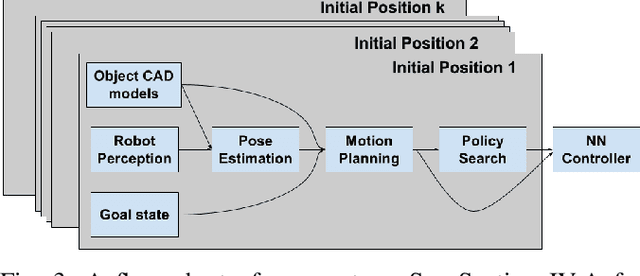

In this work, motivated by recent manufacturing trends, we investigate autonomous robotic assembly. Industrial assembly tasks require contact-rich manipulation skills, which are challenging to acquire using classical control and motion planning approaches. Consequently, robot controllers for assembly domains are presently engineered to solve a particular task, and cannot easily handle variations in the product or environment. Reinforcement learning (RL) is a promising approach for autonomously acquiring robot skills that involve contact-rich dynamics. However, RL relies on random exploration for learning a control policy, which requires many robot executions, and often gets trapped in locally suboptimal solutions. Instead, we posit that prior knowledge, when available, can improve RL performance. We exploit the fact that in modern assembly domains, geometric information about the task is readily available via the CAD design files. We propose to leverage this prior knowledge by guiding RL along a geometric motion plan, calculated using the CAD data. We show that our approach effectively improves over traditional control approaches for tracking the motion plan, and can solve assembly tasks that require high precision, even without accurate state estimation. In addition, we propose a neural network architecture that can learn to track the motion plan, and generalize the assembly controller to changes in the object positions.
Learning from the Hindsight Plan -- Episodic MPC Improvement
Mar 20, 2017
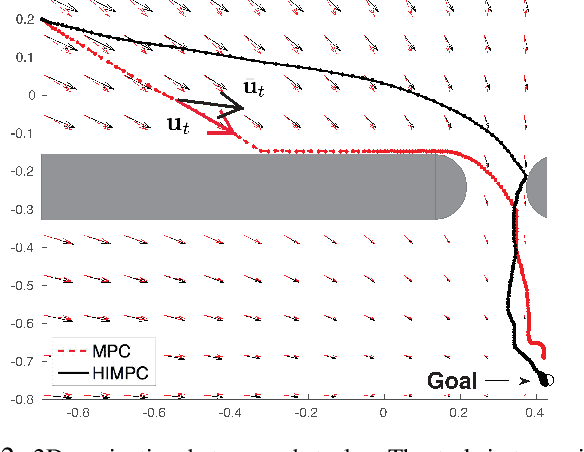
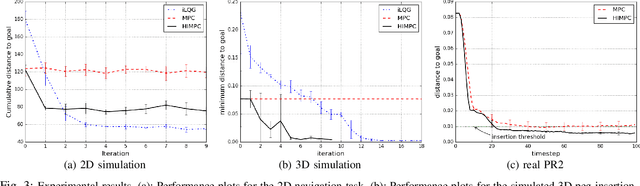

Model predictive control (MPC) is a popular control method that has proved effective for robotics, among other fields. MPC performs re-planning at every time step. Re-planning is done with a limited horizon per computational and real-time constraints and often also for robustness to potential model errors. However, the limited horizon leads to suboptimal performance. In this work, we consider the iterative learning setting, where the same task can be repeated several times, and propose a policy improvement scheme for MPC. The main idea is that between executions we can, offline, run MPC with a longer horizon, resulting in a hindsight plan. To bring the next real-world execution closer to the hindsight plan, our approach learns to re-shape the original cost function with the goal of satisfying the following property: short horizon planning (as realistic during real executions) with respect to the shaped cost should result in mimicking the hindsight plan. This effectively consolidates long-term reasoning into the short-horizon planning. We empirically evaluate our approach in contact-rich manipulation tasks both in simulated and real environments, such as peg insertion by a real PR2 robot.
Value Iteration Networks
Mar 20, 2017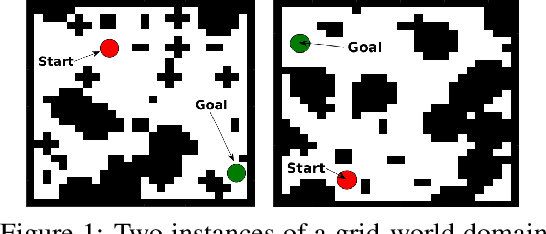
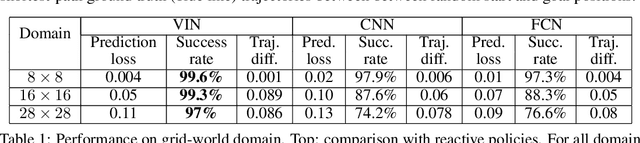
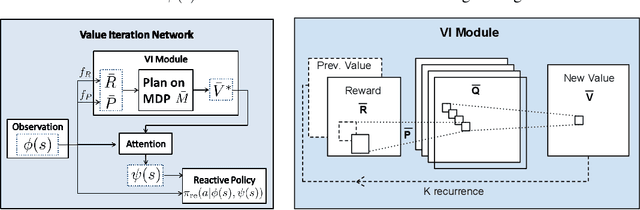
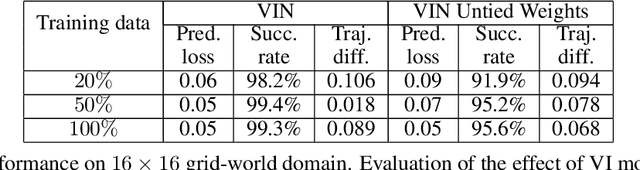
We introduce the value iteration network (VIN): a fully differentiable neural network with a `planning module' embedded within. VINs can learn to plan, and are suitable for predicting outcomes that involve planning-based reasoning, such as policies for reinforcement learning. Key to our approach is a novel differentiable approximation of the value-iteration algorithm, which can be represented as a convolutional neural network, and trained end-to-end using standard backpropagation. We evaluate VIN based policies on discrete and continuous path-planning domains, and on a natural-language based search task. We show that by learning an explicit planning computation, VIN policies generalize better to new, unseen domains.
* Fixed missing table values