Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Reinforcement Learning by Imagining the Near Future
Paper and Code
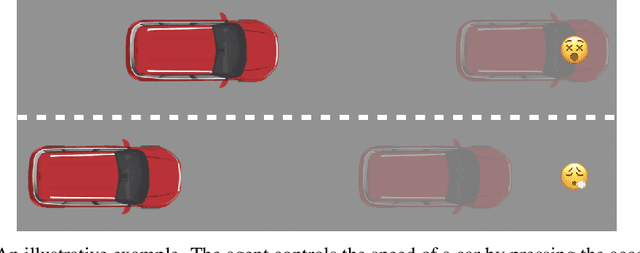
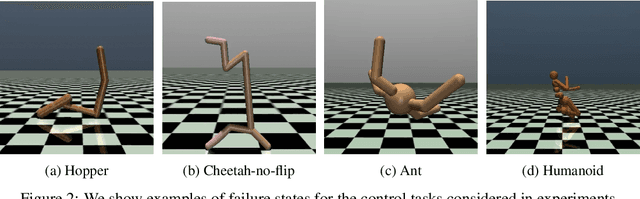

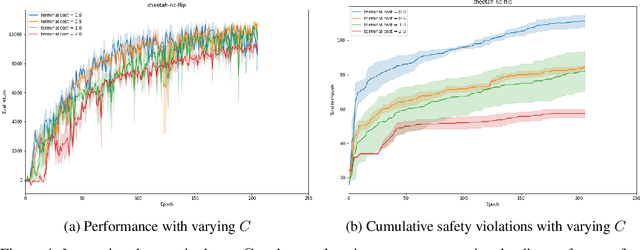
Safe reinforcement learning is a promising path toward applying reinforcement learning algorithms to real-world problems, where suboptimal behaviors may lead to actual negative consequences. In this work, we focus on the setting where unsafe states can be avoided by planning ahead a short time into the future. In this setting, a model-based agent with a sufficiently accurate model can avoid unsafe states. We devise a model-based algorithm that heavily penalizes unsafe trajectories, and derive guarantees that our algorithm can avoid unsafe states under certain assumptions. Experiments demonstrate that our algorithm can achieve competitive rewards with fewer safety violations in several continuous control tasks.
* Accepted at NeurIPS 2021
View paper on
 OpenReview
OpenReview