 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Model-based Approach for Sample-efficient Multi-task Reinforcement Learning
Paper and Code
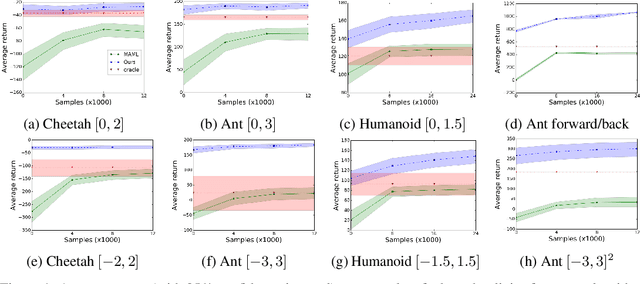
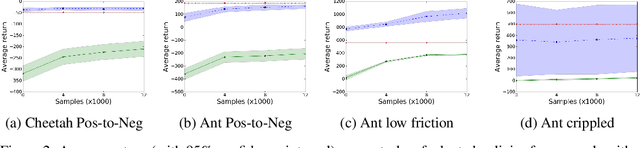
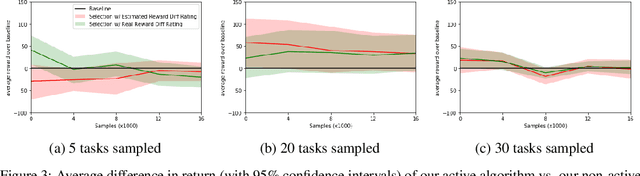
The aim of multi-task reinforcement learning is two-fold: (1) efficiently learn by training against multiple tasks and (2) quickly adapt, using limited samples, to a variety of new tasks. In this work, the tasks correspond to reward functions for environments with the same (or similar) dynamical models. We propose to learn a dynamical model during the training process and use this model to perform sample-efficient adaptation to new tasks at test time. We use significantly fewer samples by performing policy optimization only in a "virtual" environment whose transitions are given by our learned dynamical model. Our algorithm sequentially trains against several tasks. Upon encountering a new task, we first warm-up a policy on our learned dynamical model, which requires no new samples from the environment. We then adapt the dynamical model with samples from this policy in the real environment. We evaluate our approach on several continuous control benchmarks and demonstrate its efficacy over MAML, a state-of-the-art meta-learning algorithm, on these tasks.