 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeoHebbian Synapses to Accelerate Online Training of Neuromorphic Hardware
Nov 27, 2024Neuromorphic systems that employ advanced synaptic learning rules, such as the three-factor learning rule, require synaptic devices of increased complexity. Herein, a novel neoHebbian artificial synapse utilizing ReRAM devices has been proposed and experimentally validated to meet this demand. This synapse features two distinct state variables: a neuron coupling weight and an "eligibility trace" that dictates synaptic weight updates. The coupling weight is encoded in the ReRAM conductance, while the "eligibility trace" is encoded in the local temperature of the ReRAM and is modulated by applying voltage pulses to a physically co-located resistive heating element. The utility of the proposed synapse has been investigated using two representative tasks: first, temporal signal classification using Recurrent Spiking Neural Networks (RSNNs) employing the e-prop algorithm, and second, Reinforcement Learning (RL) for path planning tasks in feedforward networks using a modified version of the same learning rule. System-level simulations, accounting for various device and system-level non-idealities, confirm that these synapses offer a robust solution for the fast, compact, and energy-efficient implementation of advanced learning rules in neuromorphic hardware.
Roadmap to Neuromorphic Computing with Emerging Technologies
Jul 02, 2024



The roadmap is organized into several thematic sections, outlining current computing challenges, discussing the neuromorphic computing approach, analyzing mature and currently utilized technologies, providing an overview of emerging technologies, addressing material challenges, exploring novel computing concepts, and finally examining the maturity level of emerging technologies while determining the next essential steps for their advancement.
Quantized Context Based LIF Neurons for Recurrent Spiking Neural Networks in 45nm
Apr 28, 2024In this study, we propose the first hardware implementation of a context-based recurrent spiking neural network (RSNN) emphasizing on integrating dual information streams within the neocortical pyramidal neurons specifically Context- Dependent Leaky Integrate and Fire (CLIF) neuron models, essential element in RSNN. We present a quantized version of the CLIF neuron (qCLIF), developed through a hardware-software codesign approach utilizing the sparse activity of RSNN. Implemented in a 45nm technology node, the qCLIF is compact (900um^2) and achieves a high accuracy of 90% despite 8 bit quantization on DVS gesture classification dataset. Our analysis spans a network configuration from 10 to 200 qCLIF neurons, supporting up to 82k synapses within a 1.86 mm^2 footprint, demonstrating scalability and efficiency
Applications and Techniques for Fast Machine Learning in Science
Oct 25, 2021
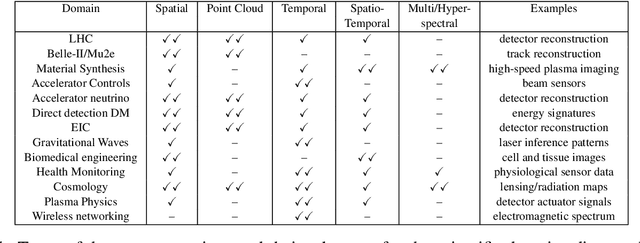
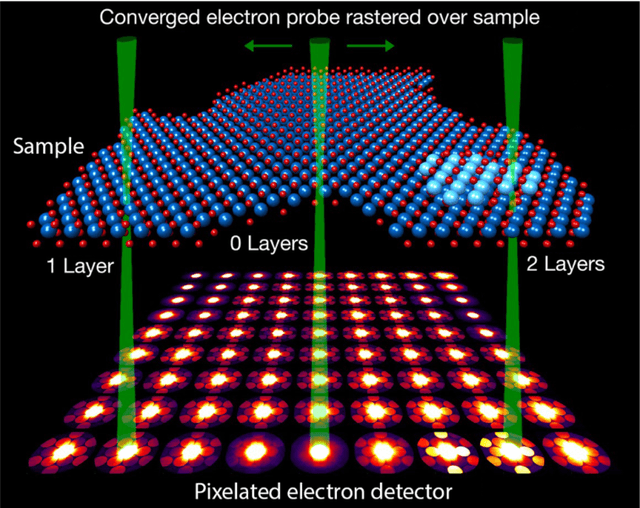
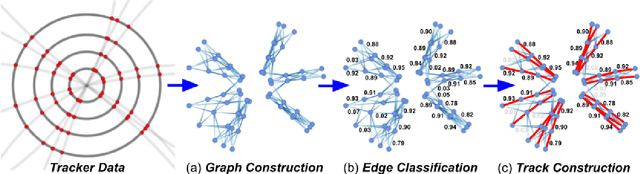
In this community review report, we discuss applications and techniques for fast machine learning (ML) in science -- the concept of integrating power ML methods into the real-time experimental data processing loop to accelerate scientific discovery. The material for the report builds on two workshops held by the Fast ML for Science community and covers three main areas: applications for fast ML across a number of scientific domains; techniques for training and implementing performant and resource-efficient ML algorithms; and computing architectures, platforms, and technologies for deploying these algorithms. We also present overlapping challenges across the multiple scientific domains where common solutions can be found. This community report is intended to give plenty of examples and inspiration for scientific discovery through integrated and accelerated ML solutions. This is followed by a high-level overview and organization of technical advances, including an abundance of pointers to source material, which can enable these breakthroughs.
Memristor Hardware-Friendly Reinforcement Learning
Jan 20, 2020
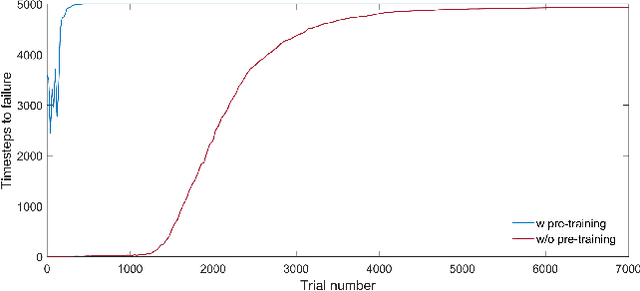

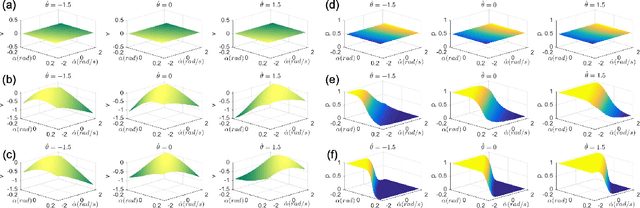
Recently, significant progress has been made in solving sophisticated problems among various domains by using reinforcement learning (RL), which allows machines or agents to learn from interactions with environments rather than explicit supervision. As the end of Moore's law seems to be imminent, emerging technologies that enable high performance neuromorphic hardware systems are attracting increasing attention. Namely, neuromorphic architectures that leverage memristors, the programmable and nonvolatile two-terminal devices, as synaptic weights in hardware neural networks, are candidates of choice to realize such highly energy-efficient and complex nervous systems. However, one of the challenges for memristive hardware with integrated learning capabilities is prohibitively large number of write cycles that might be required during learning process, and this situation is even exacerbated under RL situations. In this work we propose a memristive neuromorphic hardware implementation for the actor-critic algorithm in RL. By introducing a two-fold training procedure (i.e., ex-situ pre-training and in-situ re-training) and several training techniques, the number of weight updates can be significantly reduced and thus it will be suitable for efficient in-situ learning implementations. As a case study, we consider the task of balancing an inverted pendulum, a classical problem in both RL and control theory. We believe that this study shows the promise of using memristor-based hardware neural networks for handling complex tasks through in-situ reinforcement learning.
4K-Memristor Analog-Grade Passive Crossbar Circuit
Jun 27, 2019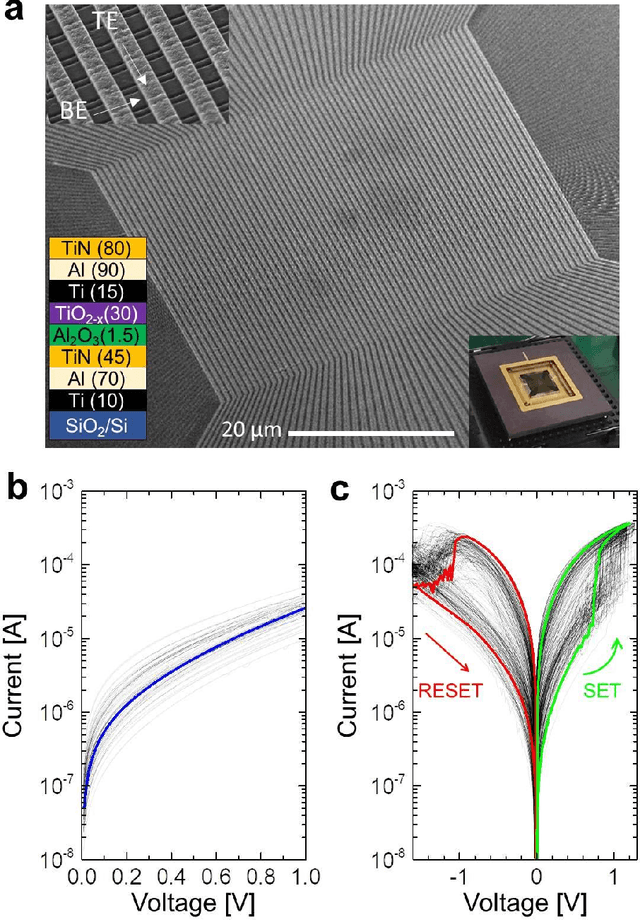
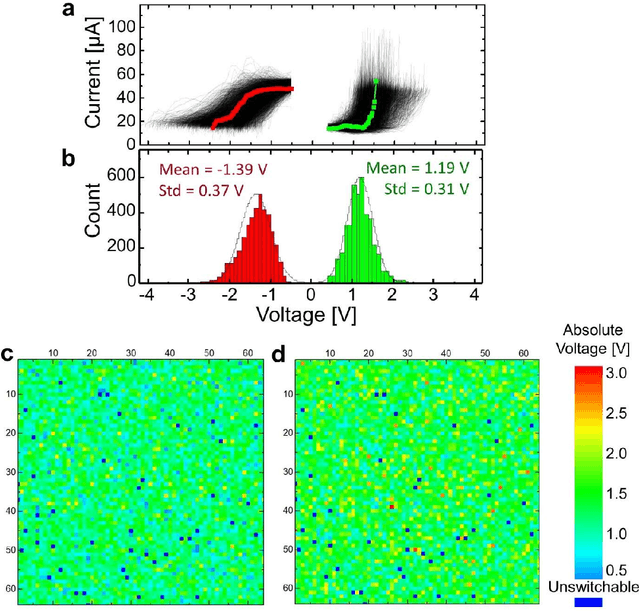
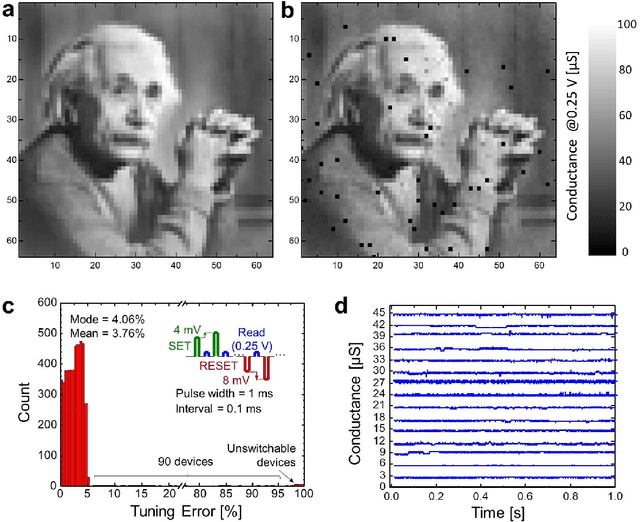
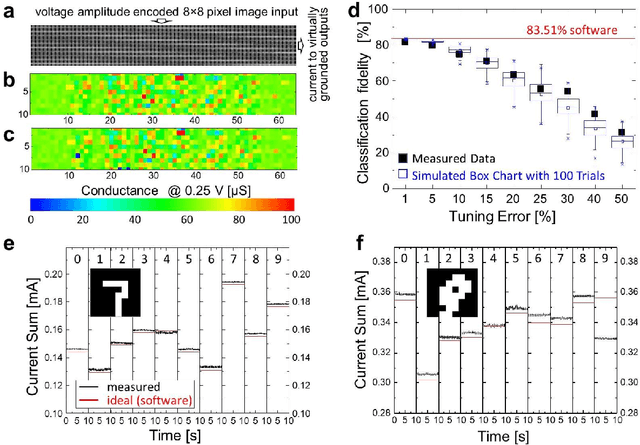
The superior density of passive analog-grade memristive crossbars may enable storing large synaptic weight matrices directly on specialized neuromorphic chips, thus avoiding costly off-chip communication. To ensure efficient use of such crossbars in neuromorphic computing circuits, variations of current-voltage characteristics of crosspoint devices must be substantially lower than those of memory cells with select transistors. Apparently, this requirement explains why there were so few demonstrations of neuromorphic system prototypes using passive crossbars. Here we report a 64x64 passive metal-oxide memristor crossbar circuit with ~99% device yield, based on a foundry-compatible fabrication process featuring etch-down patterning and low-temperature budget, conducive to vertical integration. The achieved ~26% variations of switching voltages of our devices were sufficient for programming 4K-pixel gray-scale patterns with an average tuning error smaller than 4%. The analog properties were further verified by experimentally demonstrating MNIST pattern classification with a fidelity close to the software-modeled limit for a network of this size, with an ~1% average error of import of ex-situ-calculated synaptic weights. We believe that our work is a significant improvement over the state-of-the-art passive crossbar memories in both complexity and analog properties.
Capacity, Fidelity, and Noise Tolerance of Associative Spatial-Temporal Memories Based on Memristive Neuromorphic Network
Jul 12, 2017
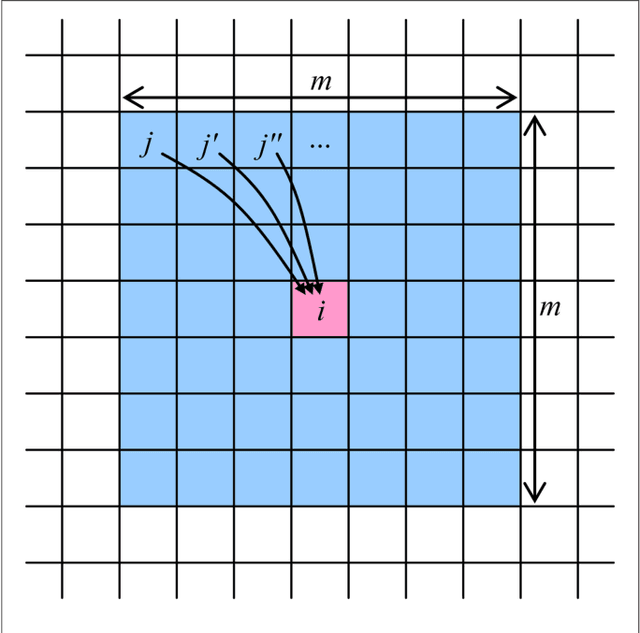
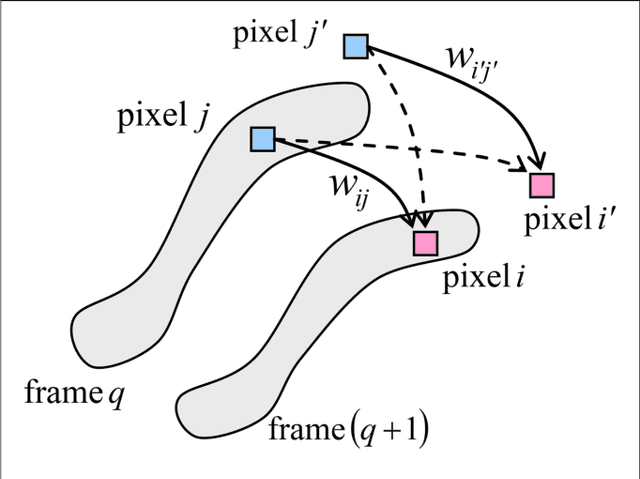

We have calculated the key characteristics of associative (content-addressable) spatial-temporal memories based on neuromorphic networks with restricted connectivity - "CrossNets". Such networks may be naturally implemented in nanoelectronic hardware using hybrid CMOS/memristor circuits, which may feature extremely high energy efficiency, approaching that of biological cortical circuits, at much higher operation speed. Our numerical simulations, in some cases confirmed by analytical calculations, have shown that the characteristics depend substantially on the method of information recording into the memory. Of the four methods we have explored, two look especially promising - one based on the quadratic programming, and the other one being a specific discrete version of the gradient descent. The latter method provides a slightly lower memory capacity (at the same fidelity) then the former one, but it allows local recording, which may be more readily implemented in nanoelectronic hardware. Most importantly, at the synchronous retrieval, both methods provide a capacity higher than that of the well-known Ternary Content-Addressable Memories with the same number of nonvolatile memory cells (e.g., memristors), though the input noise immunity of the CrossNet memories is somewhat lower.