 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeoHebbian Synapses to Accelerate Online Training of Neuromorphic Hardware
Nov 27, 2024Neuromorphic systems that employ advanced synaptic learning rules, such as the three-factor learning rule, require synaptic devices of increased complexity. Herein, a novel neoHebbian artificial synapse utilizing ReRAM devices has been proposed and experimentally validated to meet this demand. This synapse features two distinct state variables: a neuron coupling weight and an "eligibility trace" that dictates synaptic weight updates. The coupling weight is encoded in the ReRAM conductance, while the "eligibility trace" is encoded in the local temperature of the ReRAM and is modulated by applying voltage pulses to a physically co-located resistive heating element. The utility of the proposed synapse has been investigated using two representative tasks: first, temporal signal classification using Recurrent Spiking Neural Networks (RSNNs) employing the e-prop algorithm, and second, Reinforcement Learning (RL) for path planning tasks in feedforward networks using a modified version of the same learning rule. System-level simulations, accounting for various device and system-level non-idealities, confirm that these synapses offer a robust solution for the fast, compact, and energy-efficient implementation of advanced learning rules in neuromorphic hardware.
Quantized Context Based LIF Neurons for Recurrent Spiking Neural Networks in 45nm
Apr 28, 2024In this study, we propose the first hardware implementation of a context-based recurrent spiking neural network (RSNN) emphasizing on integrating dual information streams within the neocortical pyramidal neurons specifically Context- Dependent Leaky Integrate and Fire (CLIF) neuron models, essential element in RSNN. We present a quantized version of the CLIF neuron (qCLIF), developed through a hardware-software codesign approach utilizing the sparse activity of RSNN. Implemented in a 45nm technology node, the qCLIF is compact (900um^2) and achieves a high accuracy of 90% despite 8 bit quantization on DVS gesture classification dataset. Our analysis spans a network configuration from 10 to 200 qCLIF neurons, supporting up to 82k synapses within a 1.86 mm^2 footprint, demonstrating scalability and efficiency
Low Power Neuromorphic EMG Gesture Classification
Jun 04, 2022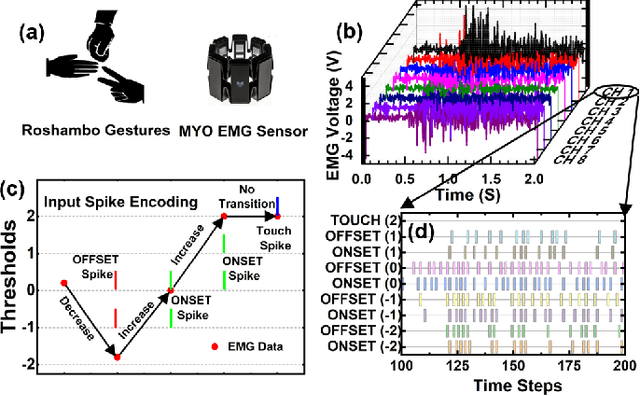
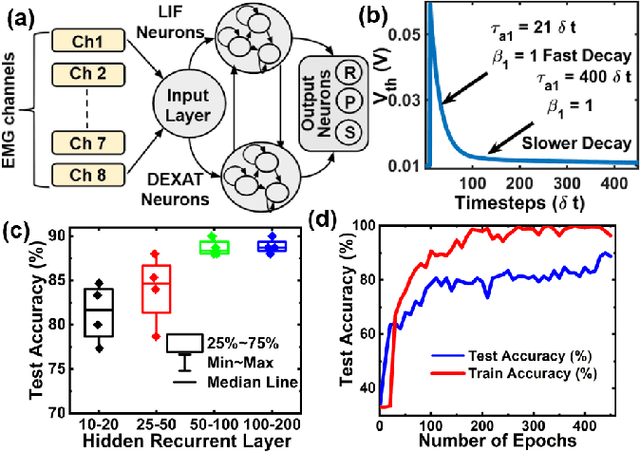
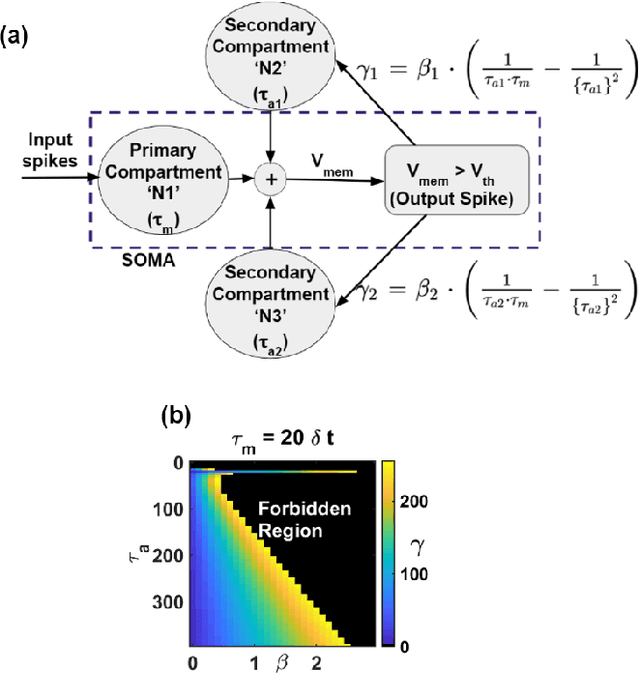
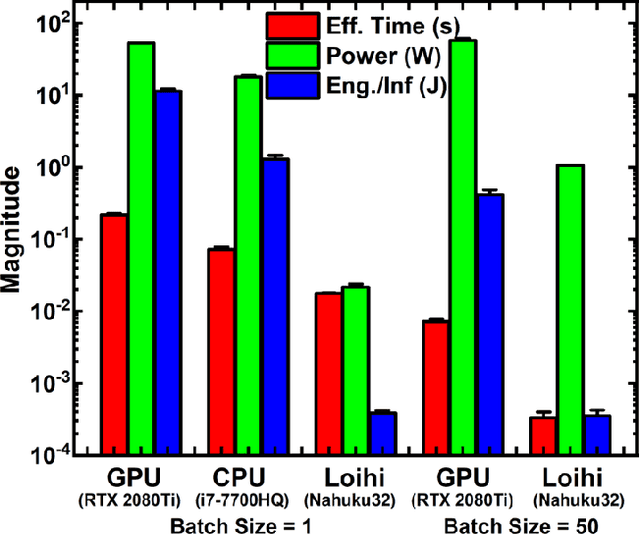
EMG (Electromyograph) signal based gesture recognition can prove vital for applications such as smart wearables and bio-medical neuro-prosthetic control. Spiking Neural Networks (SNNs) are promising for low-power, real-time EMG gesture recognition, owing to their inherent spike/event driven spatio-temporal dynamics. In literature, there are limited demonstrations of neuromorphic hardware implementation (at full chip/board/system scale) for EMG gesture classification. Moreover, most literature attempts exploit primitive SNNs based on LIF (Leaky Integrate and Fire) neurons. In this work, we address the aforementioned gaps with following key contributions: (1) Low-power, high accuracy demonstration of EMG-signal based gesture recognition using neuromorphic Recurrent Spiking Neural Networks (RSNN). In particular, we propose a multi-time scale recurrent neuromorphic system based on special double-exponential adaptive threshold (DEXAT) neurons. Our network achieves state-of-the-art classification accuracy (90%) while using ~53% lesser neurons than best reported prior art on Roshambo EMG dataset. (2) A new multi-channel spike encoder scheme for efficient processing of real-valued EMG data on neuromorphic systems. (3) Unique multi-compartment methodology to implement complex adaptive neurons on Intel's dedicated neuromorphic Loihi chip is shown. (4) RSNN implementation on Loihi (Nahuku 32) achieves significant energy/latency benefits of ~983X/19X compared to GPU for batch size as 50.
Multi-Class Classification of Blood Cells -- End to End Computer Vision based diagnosis case study
Jun 23, 2021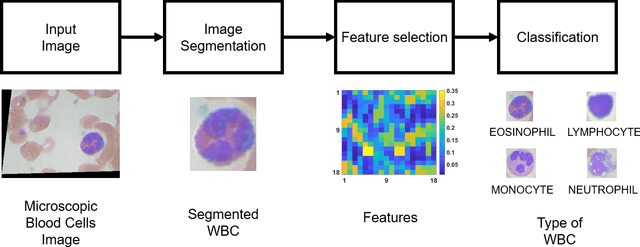
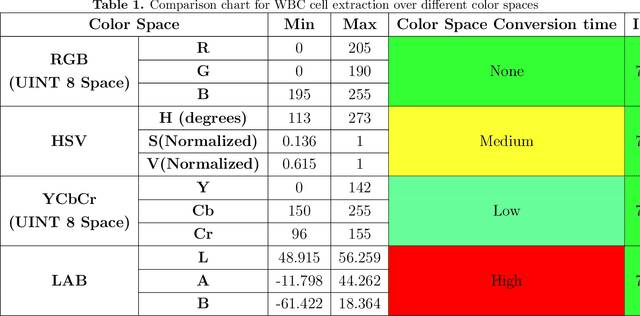
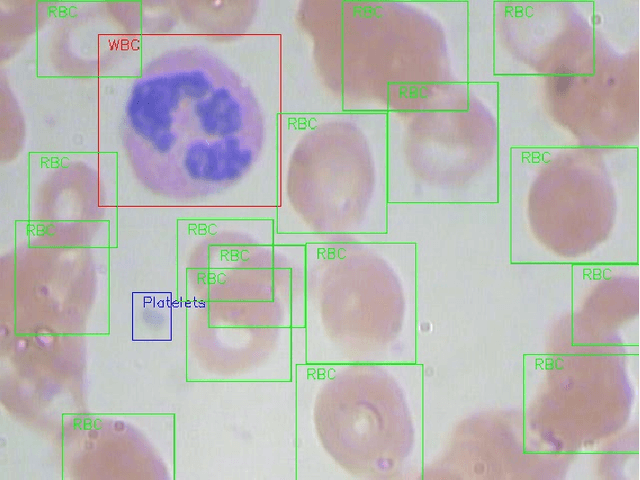
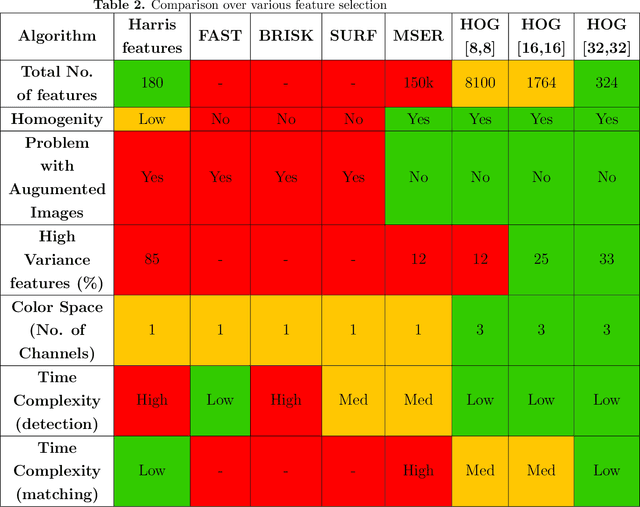
The diagnosis of blood-based diseases often involves identifying and characterizing patient blood samples. Automated methods to detect and classify blood cell subtypes have important medical applications. Automated medical image processing and analysis offers a powerful tool for medical diagnosis. In this work we tackle the problem of white blood cell classification based on the morphological characteristics of their outer contour, color. The work we would explore a set of preprocessing and segmentation (Color-based segmentation, Morphological processing, contouring) algorithms along with a set of features extraction methods (Corner detection algorithms and Histogram of Gradients(HOG)), dimensionality reduction algorithms (Principal Component Analysis(PCA)) that are able to recognize and classify through various Unsupervised(k-nearest neighbors) and Supervised (Support Vector Machine, Decision Trees, Linear Discriminant Analysis, Quadratic Discriminant Analysis, Naive Bayes) algorithms different categories of white blood cells to Eosinophil, Lymphocyte, Monocyte, and Neutrophil. We even take a step forwards to explore various Deep Convolutional Neural network architecture (Sqeezent, MobilenetV1,MobilenetV2, InceptionNet etc.) without preprocessing/segmentation and with preprocessing. We would like to explore many algorithms to identify the robust algorithm with least time complexity and low resource requirement. The outcome of this work can be a cue to selection of algorithms as per requirement for automated blood cell classification.
Efficient Video Summarization Framework using EEG and Eye-tracking Signals
Jan 27, 2021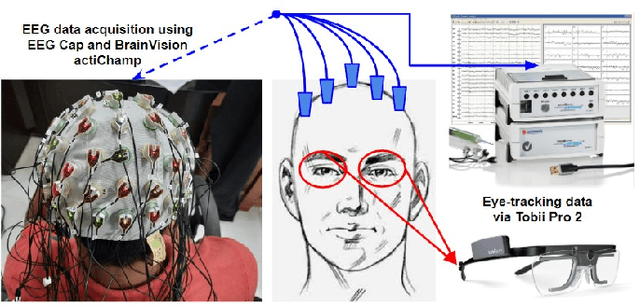

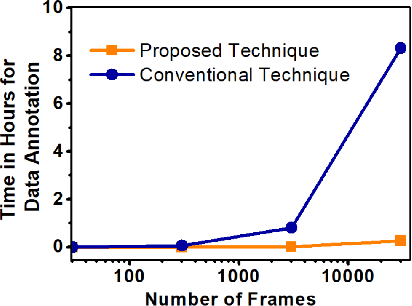
This paper proposes an efficient video summarization framework that will give a gist of the entire video in a few key-frames or video skims. Existing video summarization frameworks are based on algorithms that utilize computer vision low-level feature extraction or high-level domain level extraction. However, being the ultimate user of the summarized video, humans remain the most neglected aspect. Therefore, the proposed paper considers human's role in summarization and introduces human visual attention-based summarization techniques. To understand human attention behavior, we have designed and performed experiments with human participants using electroencephalogram (EEG) and eye-tracking technology. The EEG and eye-tracking data obtained from the experimentation are processed simultaneously and used to segment frames containing useful information from a considerable video volume. Thus, the frame segmentation primarily relies on the cognitive judgments of human beings. Using our approach, a video is summarized by 96.5% while maintaining higher precision and high recall factors. The comparison with the state-of-the-art techniques demonstrates that the proposed approach yields ceiling-level performance with reduced computational cost in summarising the videos.