 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMimicking Human Visual Development for Learning Robust Image Representations
Dec 16, 2025The human visual system is remarkably adept at adapting to changes in the input distribution; a capability modern convolutional neural networks (CNNs) still struggle to match. Drawing inspiration from the developmental trajectory of human vision, we propose a progressive blurring curriculum to improve the generalization and robustness of CNNs. Human infants are born with poor visual acuity, gradually refining their ability to perceive fine details. Mimicking this process, we begin training CNNs on highly blurred images during the initial epochs and progressively reduce the blur as training advances. This approach encourages the network to prioritize global structures over high-frequency artifacts, improving robustness against distribution shifts and noisy inputs. Challenging prior claims that blurring in the initial training epochs imposes a stimulus deficit and irreversibly harms model performance, we reveal that early-stage blurring enhances generalization with minimal impact on in-domain accuracy. Our experiments demonstrate that the proposed curriculum reduces mean corruption error (mCE) by up to 8.30% on CIFAR-10-C and 4.43% on ImageNet-100-C datasets, compared to standard training without blurring. Unlike static blur-based augmentation, which applies blurred images randomly throughout training, our method follows a structured progression, yielding consistent gains across various datasets. Furthermore, our approach complements other augmentation techniques, such as CutMix and MixUp, and enhances both natural and adversarial robustness against common attack methods. Code is available at https://github.com/rajankita/Visual_Acuity_Curriculum.
CrossMed: A Multimodal Cross-Task Benchmark for Compositional Generalization in Medical Imaging
Nov 14, 2025



Recent advances in multimodal large language models have enabled unified processing of visual and textual inputs, offering promising applications in general-purpose medical AI. However, their ability to generalize compositionally across unseen combinations of imaging modality, anatomy, and task type remains underexplored. We introduce CrossMed, a benchmark designed to evaluate compositional generalization (CG) in medical multimodal LLMs using a structured Modality-Anatomy-Task (MAT) schema. CrossMed reformulates four public datasets, CheXpert (X-ray classification), SIIM-ACR (X-ray segmentation), BraTS 2020 (MRI classification and segmentation), and MosMedData (CT classification) into a unified visual question answering (VQA) format, resulting in 20,200 multiple-choice QA instances. We evaluate two open-source multimodal LLMs, LLaVA-Vicuna-7B and Qwen2-VL-7B, on both Related and Unrelated MAT splits, as well as a zero-overlap setting where test triplets share no Modality, Anatomy, or Task with the training data. Models trained on Related splits achieve 83.2 percent classification accuracy and 0.75 segmentation cIoU, while performance drops significantly under Unrelated and zero-overlap conditions, demonstrating the benchmark difficulty. We also show cross-task transfer, where segmentation performance improves by 7 percent cIoU even when trained using classification-only data. Traditional models (ResNet-50 and U-Net) show modest gains, confirming the broad utility of the MAT framework, while multimodal LLMs uniquely excel at compositional generalization. CrossMed provides a rigorous testbed for evaluating zero-shot, cross-task, and modality-agnostic generalization in medical vision-language models.
Brain Age Group Classification Based on Resting State Functional Connectivity Metrics
Mar 27, 2025



This study investigated age-related changes in functional connectivity using resting-state fMRI and explored the efficacy of traditional deep learning for classifying brain developmental stages (BDS). Functional connectivity was assessed using Seed-Based Phase Synchronization (SBPS) and Pearson correlation across 160 ROIs. Clustering was performed using t-SNE, and network topology was analyzed through graph-theoretic metrics. Adaptive learning was implemented to classify the age group by extracting bottleneck features through mobileNetV2. These deep features were embedded and classified using Random Forest and PCA. Results showed a shift in phase synchronization patterns from sensory-driven networks in youth to more distributed networks with aging. t-SNE revealed that SBPS provided the most distinct clustering of BDS. Global efficiency and participation coefficient followed an inverted U-shaped trajectory, while clustering coefficient and modularity exhibited a U-shaped pattern. MobileNet outperformed other models, achieving the highest classification accuracy for BDS. Aging was associated with reduced global integration and increased local connectivity, indicating functional network reorganization. While this study focused solely on functional connectivity from resting-state fMRI and a limited set of connectivity features, deep learning demonstrated superior classification performance, highlighting its potential for characterizing age-related brain changes.
Integrating Human Vision Perception in Vision Transformers for Classifying Waste Items
Dec 20, 2023In this paper, we propose an novel methodology aimed at simulating the learning phenomenon of nystagmus through the application of differential blurring on datasets. Nystagmus is a biological phenomenon that influences human vision throughout life, notably by diminishing head shake from infancy to adulthood. Leveraging this concept, we address the issue of waste classification, a pressing global concern. The proposed framework comprises two modules, with the second module closely resembling the original Vision Transformer, a state-of-the-art model model in classification tasks. The primary motivation behind our approach is to enhance the model's precision and adaptability, mirroring the real-world conditions that the human visual system undergoes. This novel methodology surpasses the standard Vision Transformer model in waste classification tasks, exhibiting an improvement with a margin of 2%. This improvement underscores the potential of our methodology in improving model precision by drawing inspiration from human vision perception. Further research in the proposed methodology could yield greater performance results, and can be extrapolated to other global issues.
Insights into Age-Related Functional Brain Changes during Audiovisual Integration Tasks: A Comprehensive EEG Source-Based Analysis
Nov 27, 2023



The seamless integration of visual and auditory information is a fundamental aspect of human cognition. Although age-related functional changes in Audio-Visual Integration (AVI) have been extensively explored in the past, thorough studies across various age groups remain insufficient. Previous studies have provided valuable insights into agerelated AVI using EEG-based sensor data. However, these studies have been limited in their ability to capture spatial information related to brain source activation and their connectivity. To address these gaps, our study conducted a comprehensive audiovisual integration task with a specific focus on assessing the aging effects in various age groups, particularly middle-aged individuals. We presented visual, auditory, and audio-visual stimuli and recorded EEG data from Young (18-25 years), Transition (26- 33 years), and Middle (34-42 years) age cohort healthy participants. We aimed to understand how aging affects brain activation and functional connectivity among hubs during audio-visual tasks. Our findings revealed delayed brain activation in middleaged individuals, especially for bimodal stimuli. The superior temporal cortex and superior frontal gyrus showed significant changes in neuronal activation with aging. Lower frequency bands (theta and alpha) showed substantial changes with increasing age during AVI. Our findings also revealed that the AVI-associated brain regions can be clustered into five different brain networks using the k-means algorithm. Additionally, we observed increased functional connectivity in middle age, particularly in the frontal, temporal, and occipital regions. These results highlight the compensatory neural mechanisms involved in aging during cognitive tasks.
Brain Connectivity Features-based Age Group Classification using Temporal Asynchrony Audio-Visual Integration Task
May 01, 2023



The process of integration of inputs from several sensory modalities in the human brain is referred to as multisensory integration. Age-related cognitive decline leads to a loss in the ability of the brain to conceive multisensory inputs. There has been considerable work done in the study of such cognitive changes for the old age groups. However, in the case of middle age groups, such analysis is limited. Motivated by this, in the current work, EEG-based functional connectivity during audiovisual temporal asynchrony integration task for middle-aged groups is explored. Investigation has been carried out during different tasks such as: unimodal audio, unimodal visual, and variations of audio-visual stimulus. A correlation-based functional connectivity analysis is done, and the changes among different age groups including: young (18-25 years), transition from young to middle age (25-33 years), and medium (33-41 years), are observed. Furthermore, features extracted from the connectivity graphs have been used to classify among the different age groups. Classification accuracies of $89.4\%$ and $88.4\%$ are obtained for the Audio and Audio-50-Visual stimuli cases with a Random Forest based classifier, thereby validating the efficacy of the proposed method.
Reorganization of resting state brain network functional connectivity across human brain developmental stages
Jun 16, 2022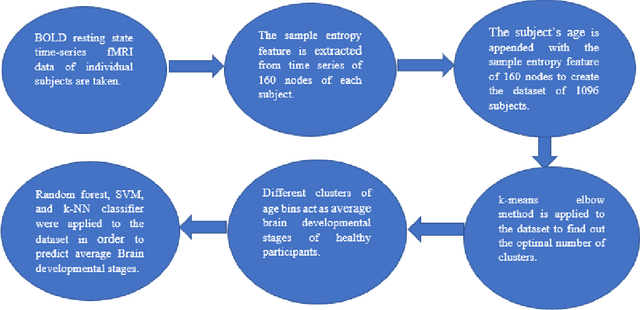

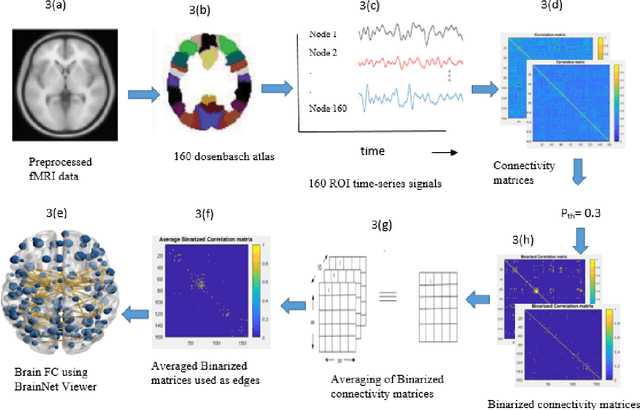
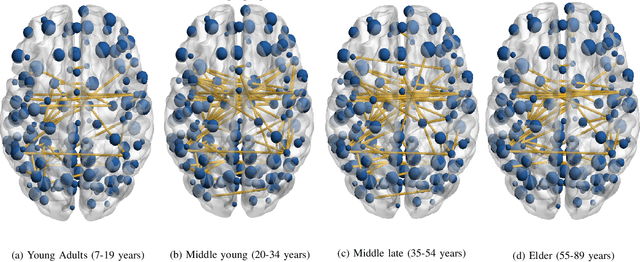
The human brain is liable to undergo substantial alterations, anatomically and functionally with aging. Cognitive brain aging can either be healthy or degenerative in nature. Such degeneration of cognitive ability can lead to disorders such as Alzheimer's disease, dementia, schizophrenia, and multiple sclerosis. Furthermore, the brain network goes through various changes during healthy aging, and it is an active area of research. In this study, we have investigated the rs-functional connectivity of participants (in the age group of 7-89 years) using a publicly available HCP dataset. We have also explored how different brain networks are clustered using K-means clustering methods which have been further validated by the t-SNE algorithm. The changes in overall resting-state brain functional connectivity with changes in brain developmental stages have also been explored using BrainNet Viewer. Then, specifically within-cluster network and between-cluster network changes with increasing age have been studied using linear regression which ultimately shows a pattern of increase/decrease in the mean segregation of brain networks with healthy aging. Brain networks like Default Mode Network, Cingulo opercular Network, Sensory Motor Network, and Cerebellum Network have shown decreased segregation whereas Frontal Parietal Network and Occipital Network show increased segregation with healthy aging. Our results strongly suggest that the brain has four brain developmental stages and brain networks reorganize their functional connectivity during these brain developmental stages.
Understanding Character Recognition using Visual Explanations Derived from the Human Visual System and Deep Networks
Aug 29, 2021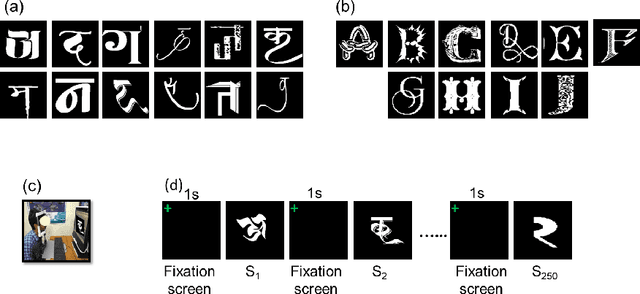
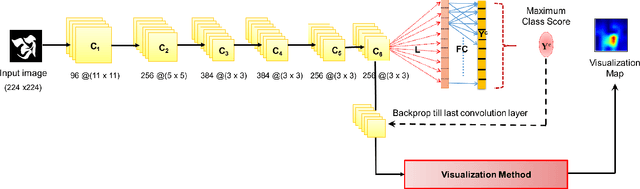
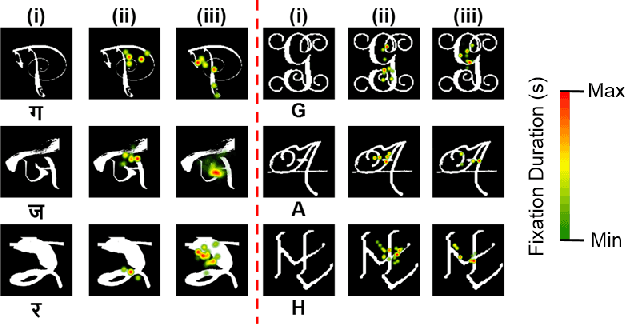
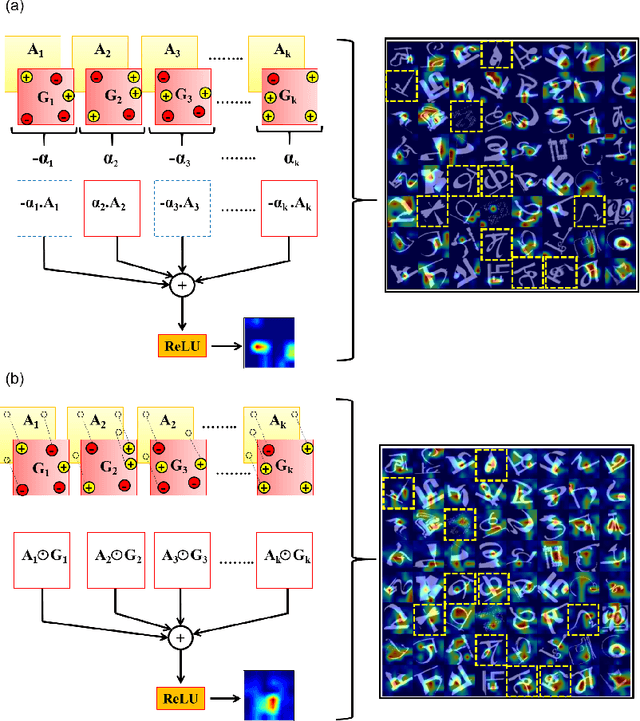
Human observers engage in selective information uptake when classifying visual patterns. The same is true of deep neural networks, which currently constitute the best performing artificial vision systems. Our goal is to examine the congruence, or lack thereof, in the information-gathering strategies of the two systems. We have operationalized our investigation as a character recognition task. We have used eye-tracking to assay the spatial distribution of information hotspots for humans via fixation maps and an activation mapping technique for obtaining analogous distributions for deep networks through visualization maps. Qualitative comparison between visualization maps and fixation maps reveals an interesting correlate of congruence. The deep learning model considered similar regions in character, which humans have fixated in the case of correctly classified characters. On the other hand, when the focused regions are different for humans and deep nets, the characters are typically misclassified by the latter. Hence, we propose to use the visual fixation maps obtained from the eye-tracking experiment as a supervisory input to align the model's focus on relevant character regions. We find that such supervision improves the model's performance significantly and does not require any additional parameters. This approach has the potential to find applications in diverse domains such as medical analysis and surveillance in which explainability helps to determine system fidelity.
Efficient Video Summarization Framework using EEG and Eye-tracking Signals
Jan 27, 2021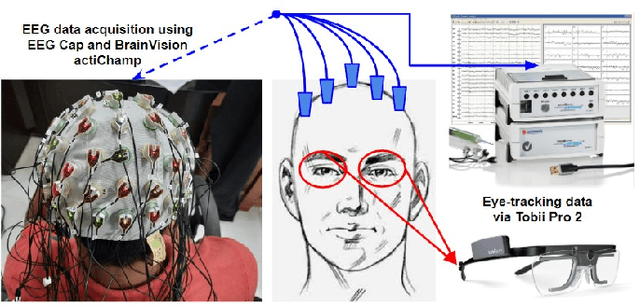

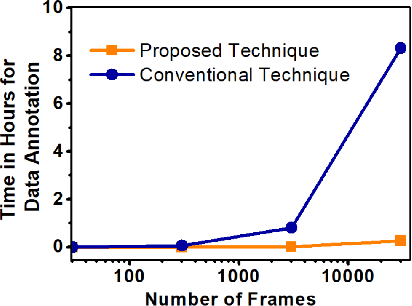
This paper proposes an efficient video summarization framework that will give a gist of the entire video in a few key-frames or video skims. Existing video summarization frameworks are based on algorithms that utilize computer vision low-level feature extraction or high-level domain level extraction. However, being the ultimate user of the summarized video, humans remain the most neglected aspect. Therefore, the proposed paper considers human's role in summarization and introduces human visual attention-based summarization techniques. To understand human attention behavior, we have designed and performed experiments with human participants using electroencephalogram (EEG) and eye-tracking technology. The EEG and eye-tracking data obtained from the experimentation are processed simultaneously and used to segment frames containing useful information from a considerable video volume. Thus, the frame segmentation primarily relies on the cognitive judgments of human beings. Using our approach, a video is summarized by 96.5% while maintaining higher precision and high recall factors. The comparison with the state-of-the-art techniques demonstrates that the proposed approach yields ceiling-level performance with reduced computational cost in summarising the videos.