 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Contrastive Learning Framework for Electroencephalography-based Air-writing Recognition
Mar 20, 2026Electroencephalography (EEG) - based air-writing recognition offers a human-computer interaction paradigm by decoding neural activity associated with handwriting movements. Despite its potential, reliable EEG-based air-writing recognition remains challenging due to low signal-to-noise ratio and pronounced inter-subject variability. In this study, we examine the use of supervised contrastive learning to improve representation learning for EEG-based air-writing recognition. The analysis is conducted on preprocessed EEG signals and independent component analysis (ICA)-derived neural components obtained from five participants, with trials segmented from -1 to 2 s relative to movement on-set. EEGNet and DeepConvNet architectures are evaluated under both conventional cross-entropy training and a supervised contrastive learning framework using a subject-dependent five-fold cross-validation scheme. The results indicate that supervised contrastive learning consistently improves classification accuracy across architectures and feature representations. For preprocessed EEG signals, the mean accuracy increases from 33.45% to 43.77% and from 29.14% to 38.06% with EEGNet and DeepConvNet, respectively. Using ICA components, higher mean accuracies of 49.21% and 43.32% are achieved with EEGNet and DeepConvNet, respectively. These results suggest that the supervised contrastive learning framework offers an efficient extension to existing EEG-based air-writing recognition approaches.
Insights into Age-Related Functional Brain Changes during Audiovisual Integration Tasks: A Comprehensive EEG Source-Based Analysis
Nov 27, 2023



The seamless integration of visual and auditory information is a fundamental aspect of human cognition. Although age-related functional changes in Audio-Visual Integration (AVI) have been extensively explored in the past, thorough studies across various age groups remain insufficient. Previous studies have provided valuable insights into agerelated AVI using EEG-based sensor data. However, these studies have been limited in their ability to capture spatial information related to brain source activation and their connectivity. To address these gaps, our study conducted a comprehensive audiovisual integration task with a specific focus on assessing the aging effects in various age groups, particularly middle-aged individuals. We presented visual, auditory, and audio-visual stimuli and recorded EEG data from Young (18-25 years), Transition (26- 33 years), and Middle (34-42 years) age cohort healthy participants. We aimed to understand how aging affects brain activation and functional connectivity among hubs during audio-visual tasks. Our findings revealed delayed brain activation in middleaged individuals, especially for bimodal stimuli. The superior temporal cortex and superior frontal gyrus showed significant changes in neuronal activation with aging. Lower frequency bands (theta and alpha) showed substantial changes with increasing age during AVI. Our findings also revealed that the AVI-associated brain regions can be clustered into five different brain networks using the k-means algorithm. Additionally, we observed increased functional connectivity in middle age, particularly in the frontal, temporal, and occipital regions. These results highlight the compensatory neural mechanisms involved in aging during cognitive tasks.
Brain Connectivity Features-based Age Group Classification using Temporal Asynchrony Audio-Visual Integration Task
May 01, 2023



The process of integration of inputs from several sensory modalities in the human brain is referred to as multisensory integration. Age-related cognitive decline leads to a loss in the ability of the brain to conceive multisensory inputs. There has been considerable work done in the study of such cognitive changes for the old age groups. However, in the case of middle age groups, such analysis is limited. Motivated by this, in the current work, EEG-based functional connectivity during audiovisual temporal asynchrony integration task for middle-aged groups is explored. Investigation has been carried out during different tasks such as: unimodal audio, unimodal visual, and variations of audio-visual stimulus. A correlation-based functional connectivity analysis is done, and the changes among different age groups including: young (18-25 years), transition from young to middle age (25-33 years), and medium (33-41 years), are observed. Furthermore, features extracted from the connectivity graphs have been used to classify among the different age groups. Classification accuracies of $89.4\%$ and $88.4\%$ are obtained for the Audio and Audio-50-Visual stimuli cases with a Random Forest based classifier, thereby validating the efficacy of the proposed method.
Analysis of EEG frequency bands for Envisioned Speech Recognition
Mar 29, 2022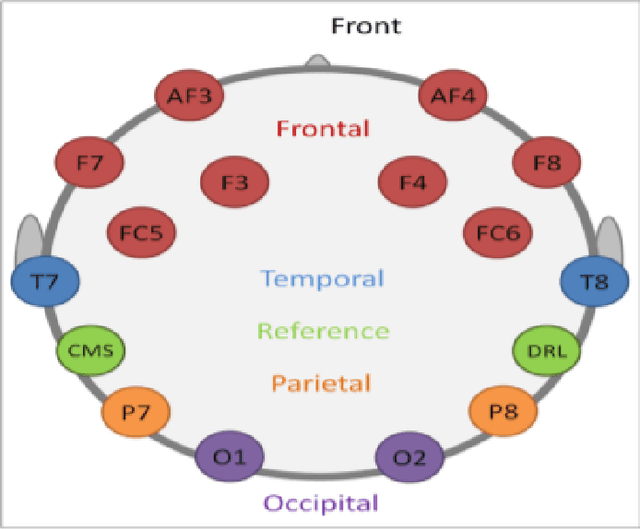
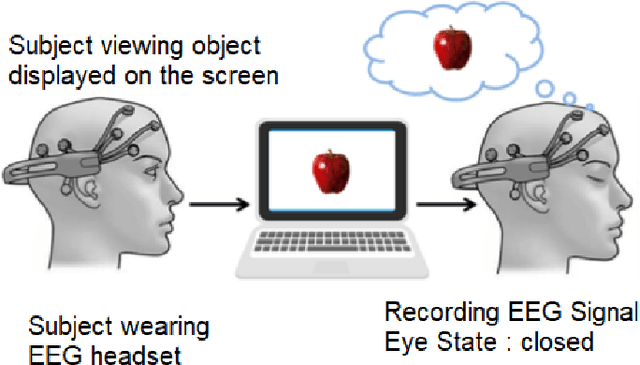
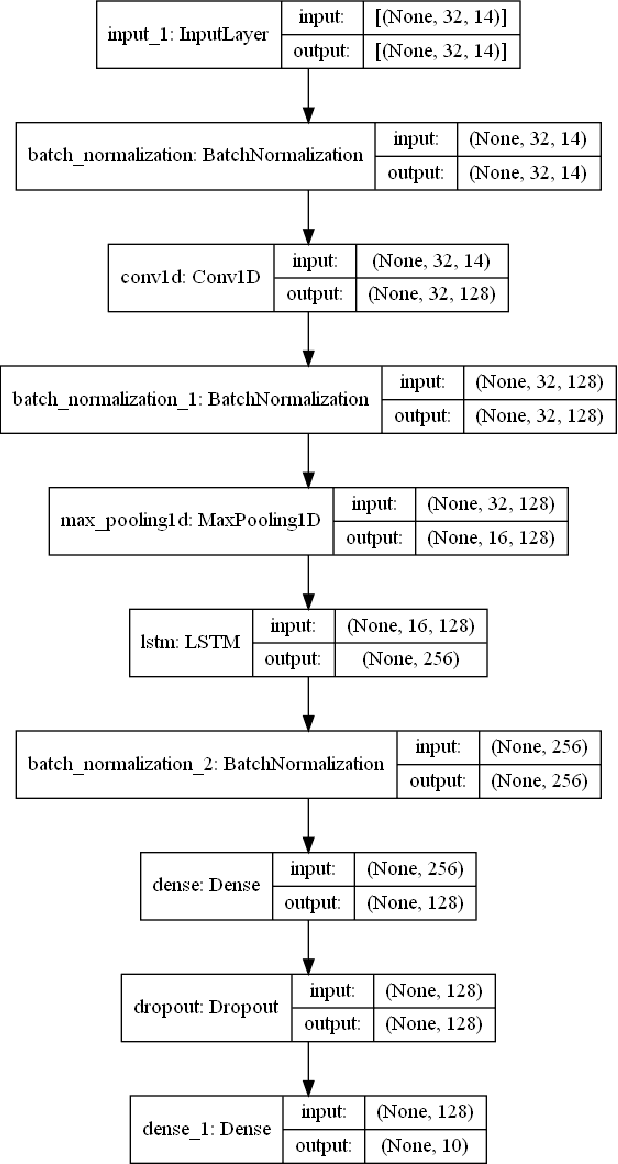
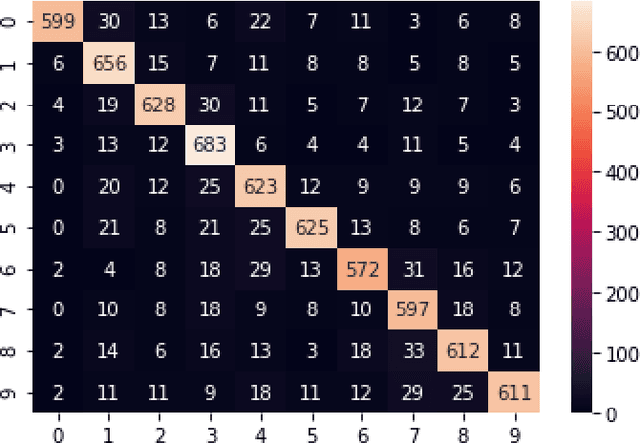
The use of Automatic speech recognition (ASR) interfaces have become increasingly popular in daily life for use in interaction and control of electronic devices. The interfaces currently being used are not feasible for a variety of users such as those suffering from a speech disorder, locked-in syndrome, paralysis or people with utmost privacy requirements. In such cases, an interface that can identify envisioned speech using electroencephalogram (EEG) signals can be of great benefit. Various works targeting this problem have been done in the past. However, there has been limited work in identifying the frequency bands ($\delta, \theta, \alpha, \beta, \gamma$) of the EEG signal that contribute towards envisioned speech recognition. Therefore, in this work, we aim to analyze the significance of different EEG frequency bands and signals obtained from different lobes of the brain and their contribution towards recognizing envisioned speech. Signals obtained from different lobes and bandpass filtered for different frequency bands are fed to a spatio-temporal deep learning architecture with Convolutional Neural Network (CNN) and Long Short-Term Memory (LSTM). The performance is evaluated on a publicly available dataset comprising of three classification tasks - digit, character and images. We obtain a classification accuracy of $85.93\%$, $87.27\%$ and $87.51\%$ for the three tasks respectively. The code for the implementation has been made available at https://github.com/ayushayt/ImaginedSpeechRecognition.
A Novel Adaptive Minority Oversampling Technique for Improved Classification in Data Imbalanced Scenarios
Mar 26, 2021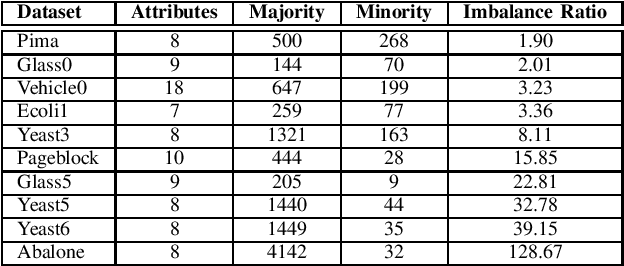
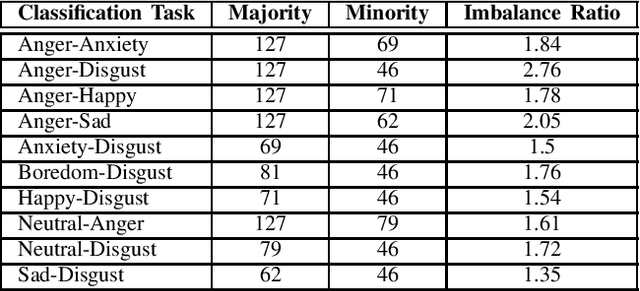
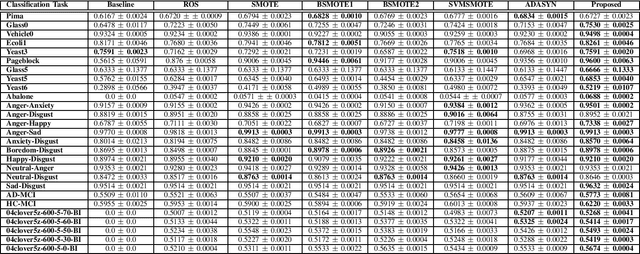
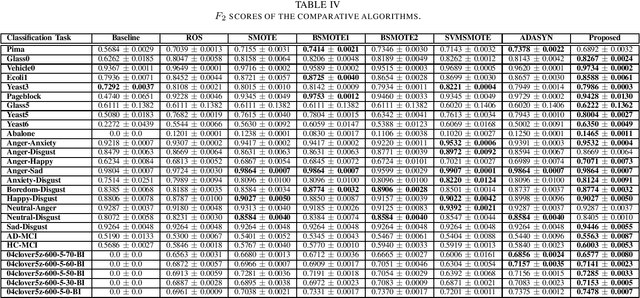
Imbalance in the proportion of training samples belonging to different classes often poses performance degradation of conventional classifiers. This is primarily due to the tendency of the classifier to be biased towards the majority classes in the imbalanced dataset. In this paper, we propose a novel three step technique to address imbalanced data. As a first step we significantly oversample the minority class distribution by employing the traditional Synthetic Minority OverSampling Technique (SMOTE) algorithm using the neighborhood of the minority class samples and in the next step we partition the generated samples using a Gaussian-Mixture Model based clustering algorithm. In the final step synthetic data samples are chosen based on the weight associated with the cluster, the weight itself being determined by the distribution of the majority class samples. Extensive experiments on several standard datasets from diverse domains shows the usefulness of the proposed technique in comparison with the original SMOTE and its state-of-the-art variants algorithms.
* 8 pages
Automatic Speaker Independent Dysarthric Speech Intelligibility Assessment System
Mar 10, 2021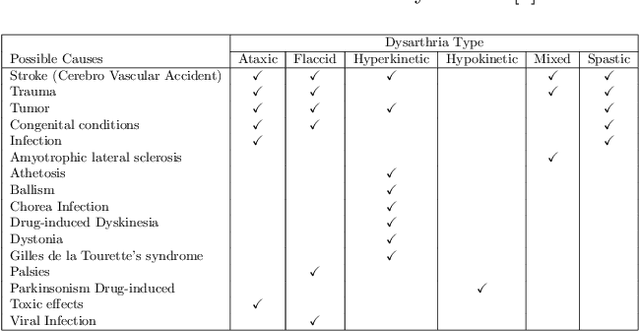
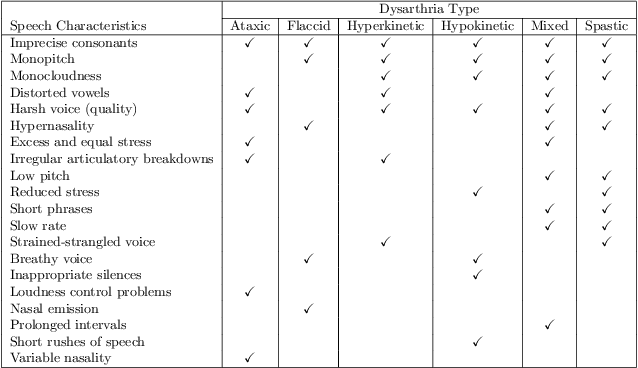
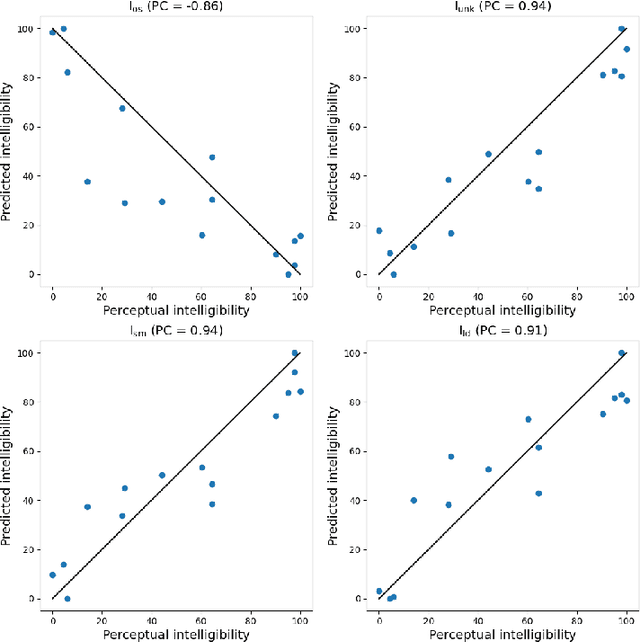
Dysarthria is a condition which hampers the ability of an individual to control the muscles that play a major role in speech delivery. The loss of fine control over muscles that assist the movement of lips, vocal chords, tongue and diaphragm results in abnormal speech delivery. One can assess the severity level of dysarthria by analyzing the intelligibility of speech spoken by an individual. Continuous intelligibility assessment helps speech language pathologists not only study the impact of medication but also allows them to plan personalized therapy. It helps the clinicians immensely if the intelligibility assessment system is reliable, automatic, simple for (a) patients to undergo and (b) clinicians to interpret. Lack of availability of dysarthric data has resulted in development of speaker dependent automatic intelligibility assessment systems which requires patients to speak a large number of utterances. In this paper, we propose (a) a cost minimization procedure to select an optimal (small) number of utterances that need to be spoken by the dysarthric patient, (b) four different speaker independent intelligibility assessment systems which require the patient to speak a small number of words, and (c) the assessment score is close to the perceptual score that the Speech Language Pathologist (SLP) can relate to. The need for small number of utterances to be spoken by the patient and the score being relatable to the SLP benefits both the dysarthric patient and the clinician from usability perspective.