 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of EEG frequency bands for Envisioned Speech Recognition
Paper and Code
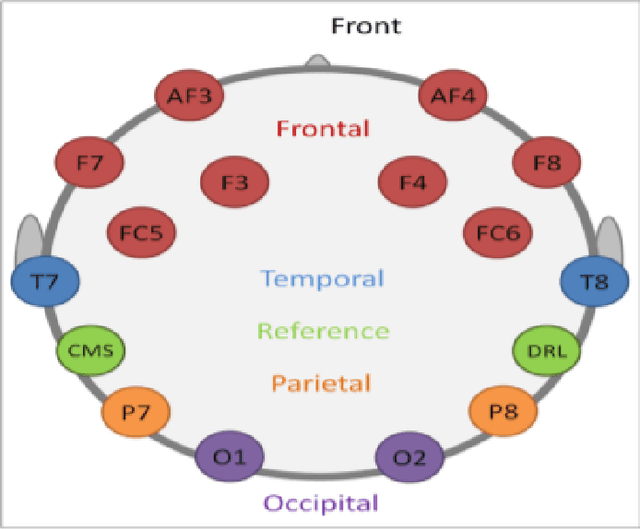
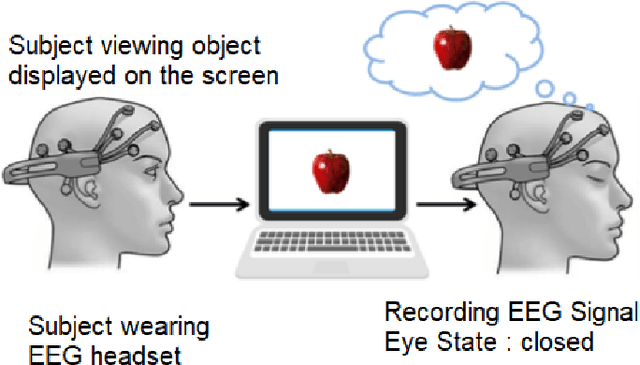
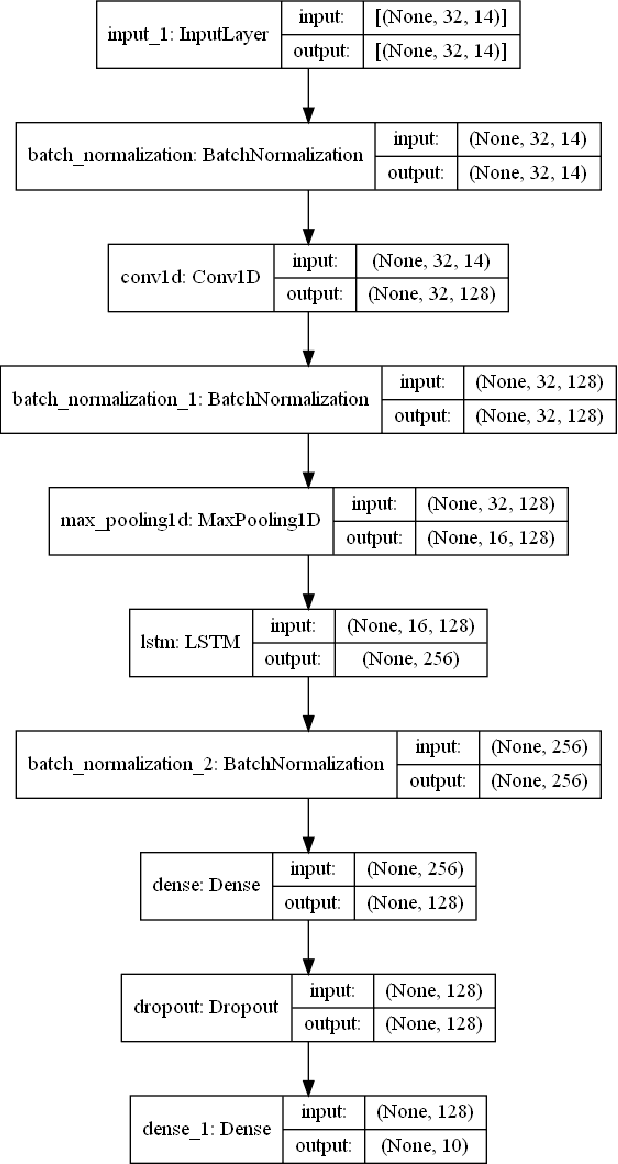
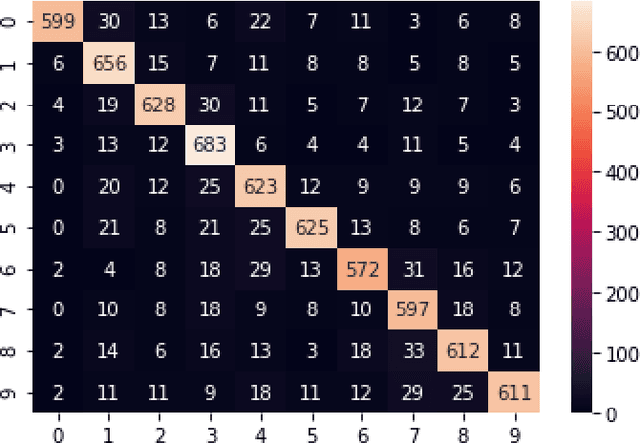
The use of Automatic speech recognition (ASR) interfaces have become increasingly popular in daily life for use in interaction and control of electronic devices. The interfaces currently being used are not feasible for a variety of users such as those suffering from a speech disorder, locked-in syndrome, paralysis or people with utmost privacy requirements. In such cases, an interface that can identify envisioned speech using electroencephalogram (EEG) signals can be of great benefit. Various works targeting this problem have been done in the past. However, there has been limited work in identifying the frequency bands ($\delta, \theta, \alpha, \beta, \gamma$) of the EEG signal that contribute towards envisioned speech recognition. Therefore, in this work, we aim to analyze the significance of different EEG frequency bands and signals obtained from different lobes of the brain and their contribution towards recognizing envisioned speech. Signals obtained from different lobes and bandpass filtered for different frequency bands are fed to a spatio-temporal deep learning architecture with Convolutional Neural Network (CNN) and Long Short-Term Memory (LSTM). The performance is evaluated on a publicly available dataset comprising of three classification tasks - digit, character and images. We obtain a classification accuracy of $85.93\%$, $87.27\%$ and $87.51\%$ for the three tasks respectively. The code for the implementation has been made available at https://github.com/ayushayt/ImaginedSpeechRecognition.