 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Character Recognition using Visual Explanations Derived from the Human Visual System and Deep Networks
Aug 29, 2021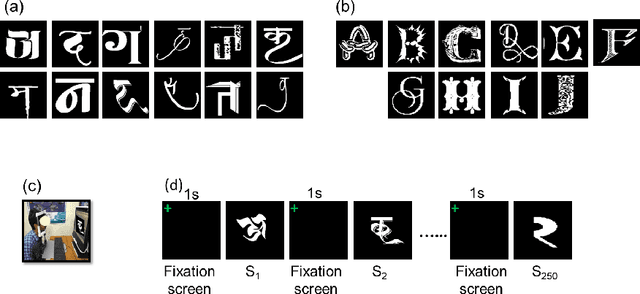
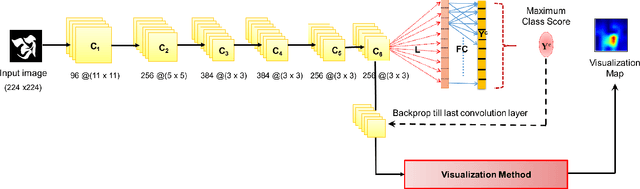
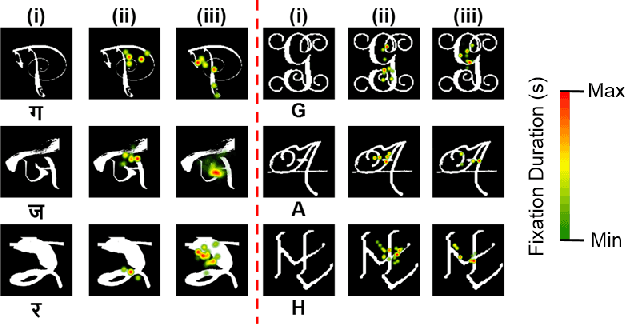
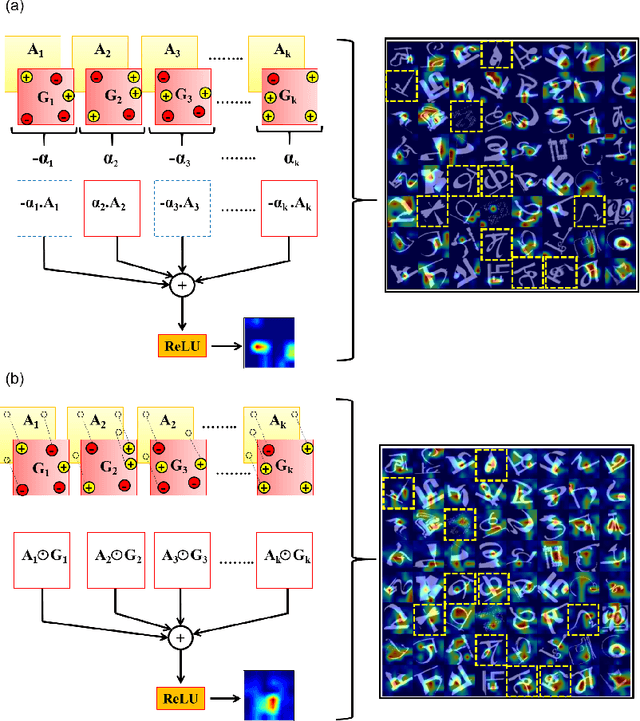
Human observers engage in selective information uptake when classifying visual patterns. The same is true of deep neural networks, which currently constitute the best performing artificial vision systems. Our goal is to examine the congruence, or lack thereof, in the information-gathering strategies of the two systems. We have operationalized our investigation as a character recognition task. We have used eye-tracking to assay the spatial distribution of information hotspots for humans via fixation maps and an activation mapping technique for obtaining analogous distributions for deep networks through visualization maps. Qualitative comparison between visualization maps and fixation maps reveals an interesting correlate of congruence. The deep learning model considered similar regions in character, which humans have fixated in the case of correctly classified characters. On the other hand, when the focused regions are different for humans and deep nets, the characters are typically misclassified by the latter. Hence, we propose to use the visual fixation maps obtained from the eye-tracking experiment as a supervisory input to align the model's focus on relevant character regions. We find that such supervision improves the model's performance significantly and does not require any additional parameters. This approach has the potential to find applications in diverse domains such as medical analysis and surveillance in which explainability helps to determine system fidelity.
Efficient Video Summarization Framework using EEG and Eye-tracking Signals
Jan 27, 2021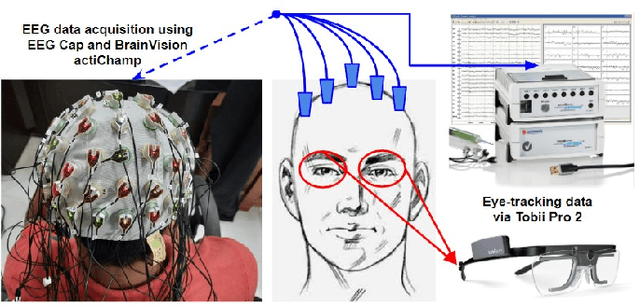

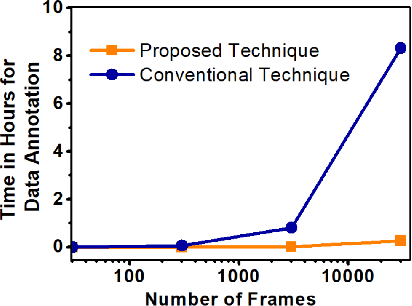
This paper proposes an efficient video summarization framework that will give a gist of the entire video in a few key-frames or video skims. Existing video summarization frameworks are based on algorithms that utilize computer vision low-level feature extraction or high-level domain level extraction. However, being the ultimate user of the summarized video, humans remain the most neglected aspect. Therefore, the proposed paper considers human's role in summarization and introduces human visual attention-based summarization techniques. To understand human attention behavior, we have designed and performed experiments with human participants using electroencephalogram (EEG) and eye-tracking technology. The EEG and eye-tracking data obtained from the experimentation are processed simultaneously and used to segment frames containing useful information from a considerable video volume. Thus, the frame segmentation primarily relies on the cognitive judgments of human beings. Using our approach, a video is summarized by 96.5% while maintaining higher precision and high recall factors. The comparison with the state-of-the-art techniques demonstrates that the proposed approach yields ceiling-level performance with reduced computational cost in summarising the videos.