 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentiment Analysis on the young people's perception about the mobile Internet costs in Senegal
Apr 17, 2025Internet penetration rates in Africa are rising steadily, and mobile Internet is getting an even bigger boost with the availability of smartphones. Young people are increasingly using the Internet, especially social networks, and Senegal is no exception to this revolution. Social networks have become the main means of expression for young people. Despite this evolution in Internet access, there are few operators on the market, which limits the alternatives available in terms of value for money. In this paper, we will look at how young people feel about the price of mobile Internet in Senegal, in relation to the perceived quality of the service, through their comments on social networks. We scanned a set of Twitter and Facebook comments related to the subject and applied a sentiment analysis model to gather their general feelings.
Task-Oriented Dialog Systems for the Senegalese Wolof Language
Dec 15, 2024In recent years, we are seeing considerable interest in conversational agents with the rise of large language models (LLMs). Although they offer considerable advantages, LLMs also present significant risks, such as hallucination, which hinder their widespread deployment in industry. Moreover, low-resource languages such as African ones are still underrepresented in these systems limiting their performance in these languages. In this paper, we illustrate a more classical approach based on modular architectures of Task-oriented Dialog Systems (ToDS) offering better control over outputs. We propose a chatbot generation engine based on the Rasa framework and a robust methodology for projecting annotations onto the Wolof language using an in-house machine translation system. After evaluating a generated chatbot trained on the Amazon Massive dataset, our Wolof Intent Classifier performs similarly to the one obtained for French, which is a resource-rich language. We also show that this approach is extensible to other low-resource languages, thanks to the intent classifier's language-agnostic pipeline, simplifying the design of chatbots in these languages.
MasakhaPOS: Part-of-Speech Tagging for Typologically Diverse African Languages
May 23, 2023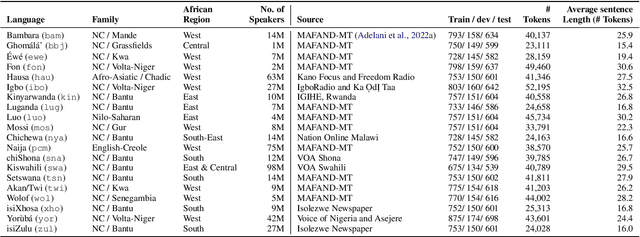
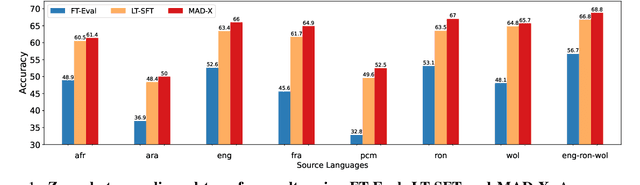
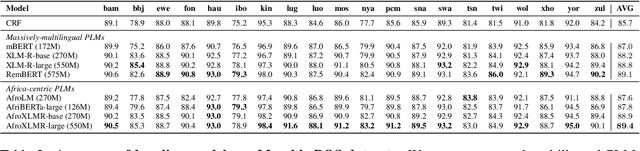
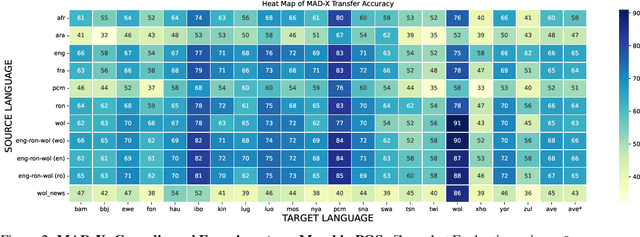
In this paper, we present MasakhaPOS, the largest part-of-speech (POS) dataset for 20 typologically diverse African languages. We discuss the challenges in annotating POS for these languages using the UD (universal dependencies) guidelines. We conducted extensive POS baseline experiments using conditional random field and several multilingual pre-trained language models. We applied various cross-lingual transfer models trained with data available in UD. Evaluating on the MasakhaPOS dataset, we show that choosing the best transfer language(s) in both single-source and multi-source setups greatly improves the POS tagging performance of the target languages, in particular when combined with cross-lingual parameter-efficient fine-tuning methods. Crucially, transferring knowledge from a language that matches the language family and morphosyntactic properties seems more effective for POS tagging in unseen languages.
Beqi: Revitalize the Senegalese Wolof Language with a Robust Spelling Corrector
May 15, 2023



The progress of Natural Language Processing (NLP), although fast in recent years, is not at the same pace for all languages. African languages in particular are still behind and lack automatic processing tools. Some of these tools are very important for the development of these languages but also have an important role in many NLP applications. This is particularly the case for automatic spell checkers. Several approaches have been studied to address this task and the one modeling spelling correction as a translation task from misspelled (noisy) text to well-spelled (correct) text shows promising results. However, this approach requires a parallel corpus of noisy data on the one hand and correct data on the other hand, whereas Wolof is a low-resource language and does not have such a corpus. In this paper, we present a way to address the constraint related to the lack of data by generating synthetic data and we present sequence-to-sequence models using Deep Learning for spelling correction in Wolof. We evaluated these models in three different scenarios depending on the subwording method applied to the data and showed that the latter had a significant impact on the performance of the models, which opens the way for future research in Wolof spelling correction.
Low-Resourced Machine Translation for Senegalese Wolof Language
May 01, 2023Natural Language Processing (NLP) research has made great advancements in recent years with major breakthroughs that have established new benchmarks. However, these advances have mainly benefited a certain group of languages commonly referred to as resource-rich such as English and French. Majority of other languages with weaker resources are then left behind which is the case for most African languages including Wolof. In this work, we present a parallel Wolof/French corpus of 123,000 sentences on which we conducted experiments on machine translation models based on Recurrent Neural Networks (RNN) in different data configurations. We noted performance gains with the models trained on subworded data as well as those trained on the French-English language pair compared to those trained on the French-Wolof pair under the same experimental conditions.
A Few Thousand Translations Go a Long Way! Leveraging Pre-trained Models for African News Translation
May 04, 2022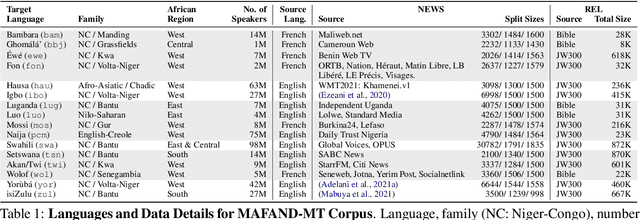
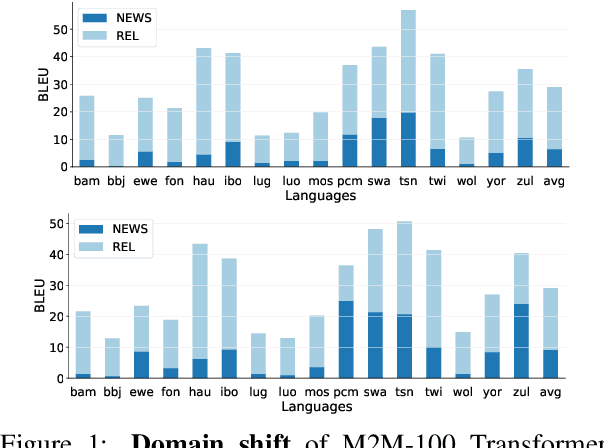

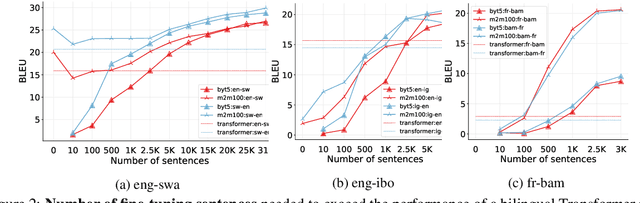
Recent advances in the pre-training of language models leverage large-scale datasets to create multilingual models. However, low-resource languages are mostly left out in these datasets. This is primarily because many widely spoken languages are not well represented on the web and therefore excluded from the large-scale crawls used to create datasets. Furthermore, downstream users of these models are restricted to the selection of languages originally chosen for pre-training. This work investigates how to optimally leverage existing pre-trained models to create low-resource translation systems for 16 African languages. We focus on two questions: 1) How can pre-trained models be used for languages not included in the initial pre-training? and 2) How can the resulting translation models effectively transfer to new domains? To answer these questions, we create a new African news corpus covering 16 languages, of which eight languages are not part of any existing evaluation dataset. We demonstrate that the most effective strategy for transferring both to additional languages and to additional domains is to fine-tune large pre-trained models on small quantities of high-quality translation data.
MasakhaNER: Named Entity Recognition for African Languages
Mar 22, 2021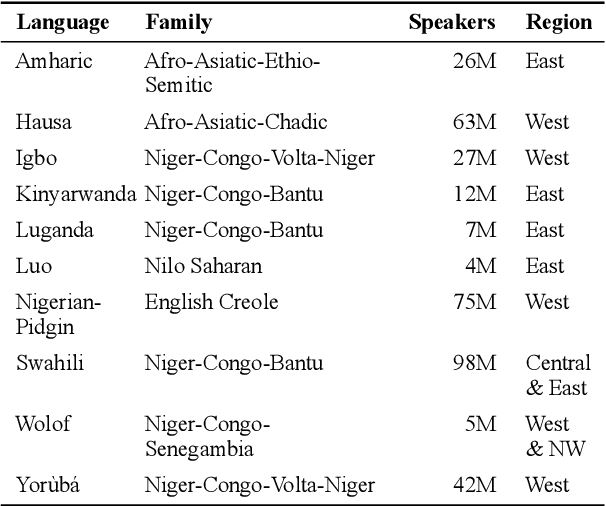

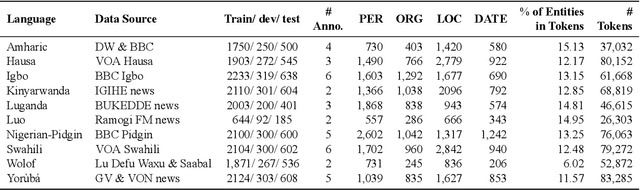
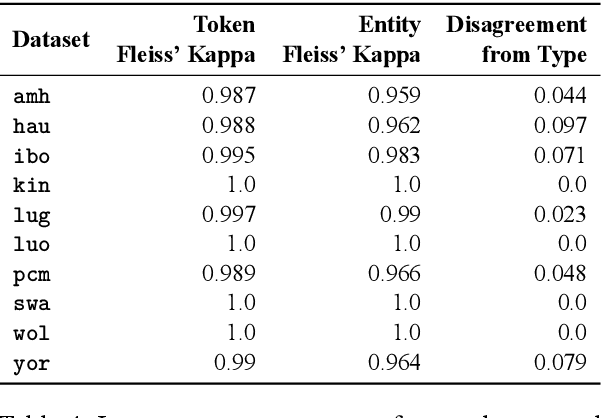
We take a step towards addressing the under-representation of the African continent in NLP research by creating the first large publicly available high-quality dataset for named entity recognition (NER) in ten African languages, bringing together a variety of stakeholders. We detail characteristics of the languages to help researchers understand the challenges that these languages pose for NER. We analyze our datasets and conduct an extensive empirical evaluation of state-of-the-art methods across both supervised and transfer learning settings. We release the data, code, and models in order to inspire future research on African NLP.