 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAS-Prompt: Large Language Models as Numerical Optimizers for Robot Self-Improvement
Apr 29, 2025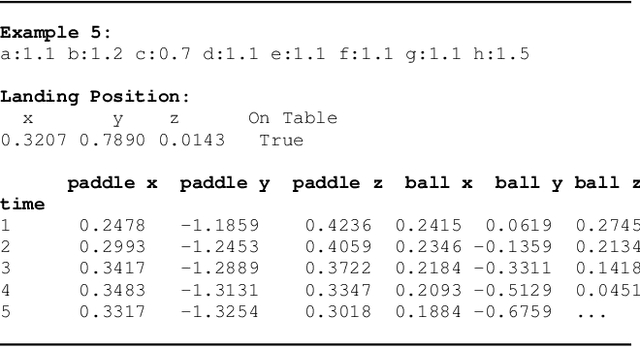

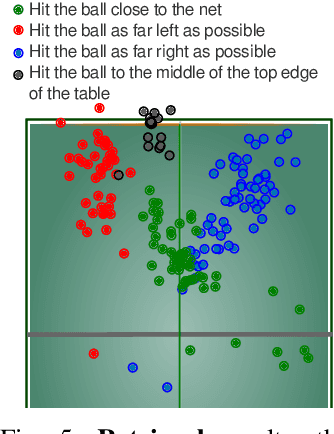

We demonstrate the ability of large language models (LLMs) to perform iterative self-improvement of robot policies. An important insight of this paper is that LLMs have a built-in ability to perform (stochastic) numerical optimization and that this property can be leveraged for explainable robot policy search. Based on this insight, we introduce the SAS Prompt (Summarize, Analyze, Synthesize) -- a single prompt that enables iterative learning and adaptation of robot behavior by combining the LLM's ability to retrieve, reason and optimize over previous robot traces in order to synthesize new, unseen behavior. Our approach can be regarded as an early example of a new family of explainable policy search methods that are entirely implemented within an LLM. We evaluate our approach both in simulation and on a real-robot table tennis task. Project website: sites.google.com/asu.edu/sas-llm/
Gemini Robotics: Bringing AI into the Physical World
Mar 25, 2025Recent advancements in large multimodal models have led to the emergence of remarkable generalist capabilities in digital domains, yet their translation to physical agents such as robots remains a significant challenge. This report introduces a new family of AI models purposefully designed for robotics and built upon the foundation of Gemini 2.0. We present Gemini Robotics, an advanced Vision-Language-Action (VLA) generalist model capable of directly controlling robots. Gemini Robotics executes smooth and reactive movements to tackle a wide range of complex manipulation tasks while also being robust to variations in object types and positions, handling unseen environments as well as following diverse, open vocabulary instructions. We show that with additional fine-tuning, Gemini Robotics can be specialized to new capabilities including solving long-horizon, highly dexterous tasks, learning new short-horizon tasks from as few as 100 demonstrations and adapting to completely novel robot embodiments. This is made possible because Gemini Robotics builds on top of the Gemini Robotics-ER model, the second model we introduce in this work. Gemini Robotics-ER (Embodied Reasoning) extends Gemini's multimodal reasoning capabilities into the physical world, with enhanced spatial and temporal understanding. This enables capabilities relevant to robotics including object detection, pointing, trajectory and grasp prediction, as well as multi-view correspondence and 3D bounding box predictions. We show how this novel combination can support a variety of robotics applications. We also discuss and address important safety considerations related to this new class of robotics foundation models. The Gemini Robotics family marks a substantial step towards developing general-purpose robots that realizes AI's potential in the physical world.
Agile Catching with Whole-Body MPC and Blackbox Policy Learning
Jun 14, 2023


We address a benchmark task in agile robotics: catching objects thrown at high-speed. This is a challenging task that involves tracking, intercepting, and cradling a thrown object with access only to visual observations of the object and the proprioceptive state of the robot, all within a fraction of a second. We present the relative merits of two fundamentally different solution strategies: (i) Model Predictive Control using accelerated constrained trajectory optimization, and (ii) Reinforcement Learning using zeroth-order optimization. We provide insights into various performance trade-offs including sample efficiency, sim-to-real transfer, robustness to distribution shifts, and whole-body multimodality via extensive on-hardware experiments. We conclude with proposals on fusing "classical" and "learning-based" techniques for agile robot control. Videos of our experiments may be found at https://sites.google.com/view/agile-catching
SPIN: A High Speed, High Resolution Vision Dataset for Tracking and Action Recognition in Ping Pong
Dec 13, 2019

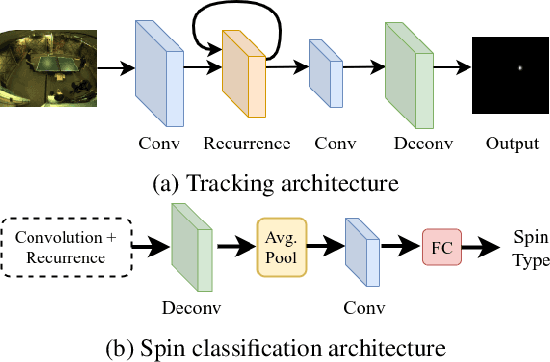
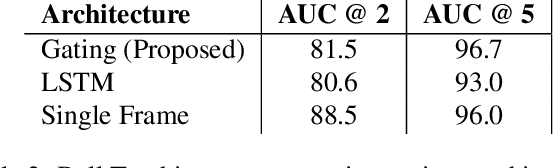
We introduce a new high resolution, high frame rate stereo video dataset, which we call SPIN, for tracking and action recognition in the game of ping pong. The corpus consists of ping pong play with three main annotation streams that can be used to learn tracking and action recognition models -- tracking of the ping pong ball and poses of humans in the videos and the spin of the ball being hit by humans. The training corpus consists of 53 hours of data with labels derived from previous models in a semi-supervised method. The testing corpus contains 1 hour of data with the same information, except that crowd compute was used to obtain human annotations of the ball position, from which ball spin has been derived. Along with the dataset we introduce several baseline models that were trained on this data. The models were specifically chosen to be able to perform inference at the same rate as the images are generated -- specifically 150 fps. We explore the advantages of multi-task training on this data, and also show interesting properties of ping pong ball trajectories that are derived from our observational data, rather than from prior physics models. To our knowledge this is the first large scale dataset of ping pong; we offer it to the community as a rich dataset that can be used for a large variety of machine learning and vision tasks such as tracking, pose estimation, semi-supervised and unsupervised learning and generative modeling.