 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral-Purpose vs. Domain-Adapted Large Language Models for Extraction of Data from Thoracic Radiology Reports
Dec 01, 2023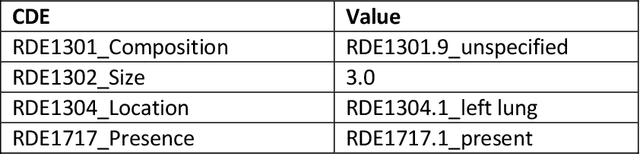
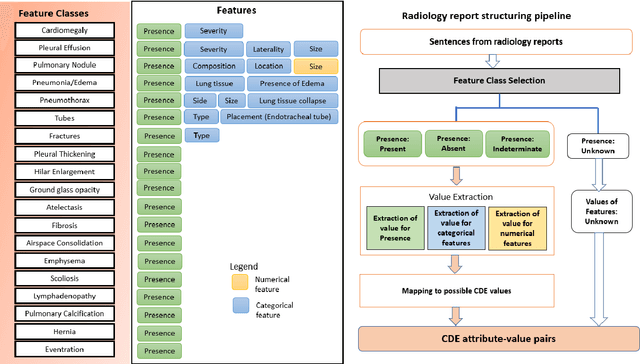
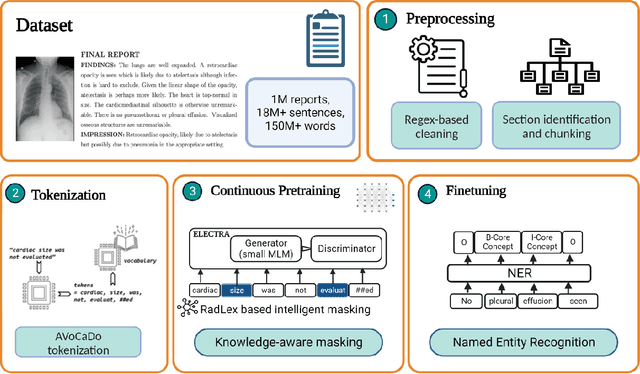
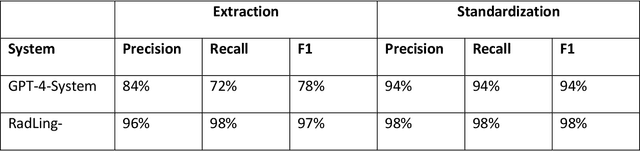
Radiologists produce unstructured data that could be valuable for clinical care when consumed by information systems. However, variability in style limits usage. Study compares performance of system using domain-adapted language model (RadLing) and general-purpose large language model (GPT-4) in extracting common data elements (CDE) from thoracic radiology reports. Three radiologists annotated a retrospective dataset of 1300 thoracic reports (900 training, 400 test) and mapped to 21 pre-selected relevant CDEs. RadLing was used to generate embeddings for sentences and identify CDEs using cosine-similarity, which were mapped to values using light-weight mapper. GPT-4 system used OpenAI's general-purpose embeddings to identify relevant CDEs and used GPT-4 to map to values. The output CDE:value pairs were compared to the reference standard; an identical match was considered true positive. Precision (positive predictive value) was 96% (2700/2824) for RadLing and 99% (2034/2047) for GPT-4. Recall (sensitivity) was 94% (2700/2876) for RadLing and 70% (2034/2887) for GPT-4; the difference was statistically significant (P<.001). RadLing's domain-adapted embeddings were more sensitive in CDE identification (95% vs 71%) and its light-weight mapper had comparable precision in value assignment (95.4% vs 95.0%). RadLing system exhibited higher performance than GPT-4 system in extracting CDEs from radiology reports. RadLing system's domain-adapted embeddings outperform general-purpose embeddings from OpenAI in CDE identification and its light-weight value mapper achieves comparable precision to large GPT-4. RadLing system offers operational advantages including local deployment and reduced runtime costs. Domain-adapted RadLing system surpasses GPT-4 system in extracting common data elements from radiology reports, while providing benefits of local deployment and lower costs.
Understanding metric-related pitfalls in image analysis validation
Feb 09, 2023Validation metrics are key for the reliable tracking of scientific progress and for bridging the current chasm between artificial intelligence (AI) research and its translation into practice. However, increasing evidence shows that particularly in image analysis, metrics are often chosen inadequately in relation to the underlying research problem. This could be attributed to a lack of accessibility of metric-related knowledge: While taking into account the individual strengths, weaknesses, and limitations of validation metrics is a critical prerequisite to making educated choices, the relevant knowledge is currently scattered and poorly accessible to individual researchers. Based on a multi-stage Delphi process conducted by a multidisciplinary expert consortium as well as extensive community feedback, the present work provides the first reliable and comprehensive common point of access to information on pitfalls related to validation metrics in image analysis. Focusing on biomedical image analysis but with the potential of transfer to other fields, the addressed pitfalls generalize across application domains and are categorized according to a newly created, domain-agnostic taxonomy. To facilitate comprehension, illustrations and specific examples accompany each pitfall. As a structured body of information accessible to researchers of all levels of expertise, this work enhances global comprehension of a key topic in image analysis validation.
Metrics reloaded: Pitfalls and recommendations for image analysis validation
Jun 03, 2022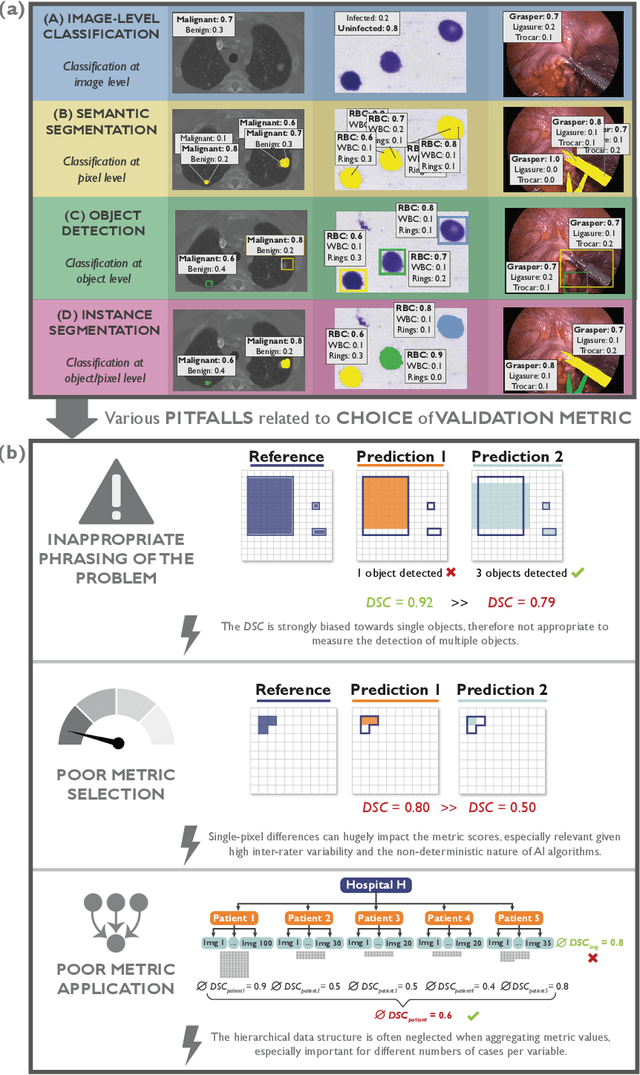
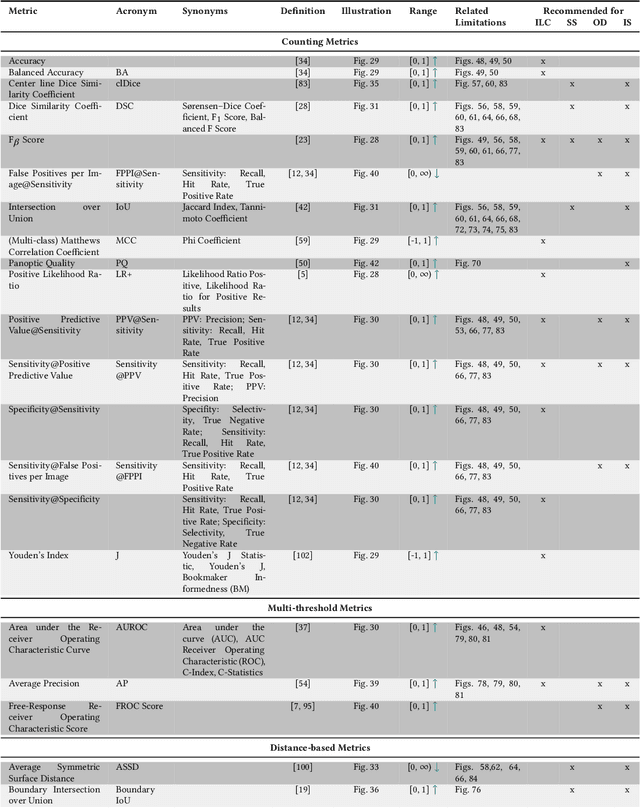
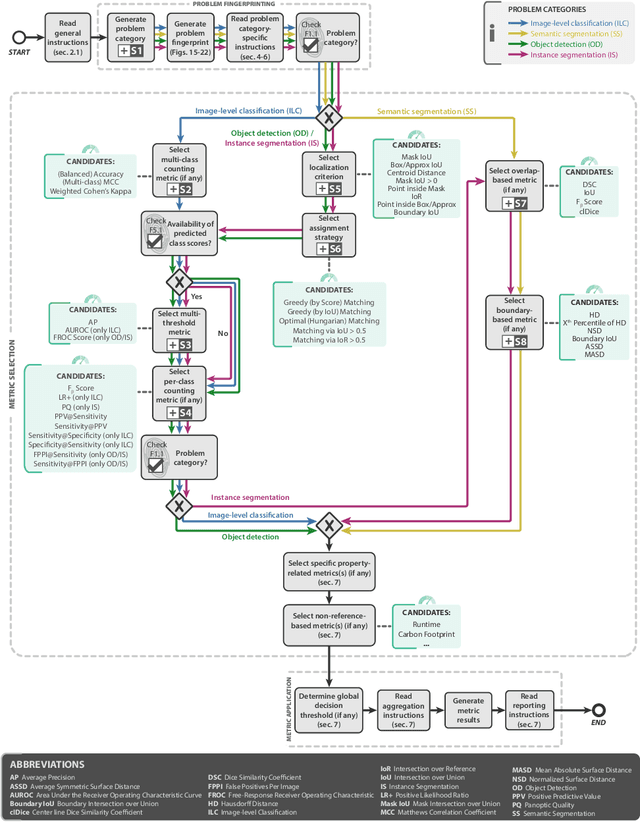
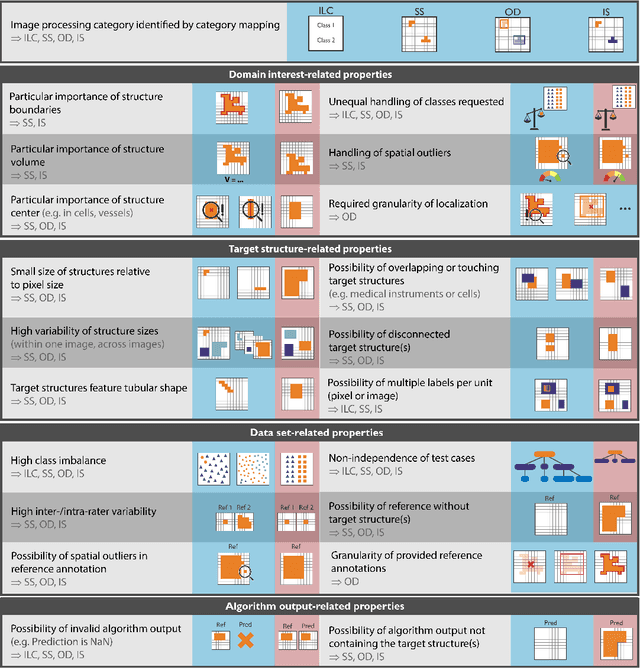
The field of automatic biomedical image analysis crucially depends on robust and meaningful performance metrics for algorithm validation. Current metric usage, however, is often ill-informed and does not reflect the underlying domain interest. Here, we present a comprehensive framework that guides researchers towards choosing performance metrics in a problem-aware manner. Specifically, we focus on biomedical image analysis problems that can be interpreted as a classification task at image, object or pixel level. The framework first compiles domain interest-, target structure-, data set- and algorithm output-related properties of a given problem into a problem fingerprint, while also mapping it to the appropriate problem category, namely image-level classification, semantic segmentation, instance segmentation, or object detection. It then guides users through the process of selecting and applying a set of appropriate validation metrics while making them aware of potential pitfalls related to individual choices. In this paper, we describe the current status of the Metrics Reloaded recommendation framework, with the goal of obtaining constructive feedback from the image analysis community. The current version has been developed within an international consortium of more than 60 image analysis experts and will be made openly available as a user-friendly toolkit after community-driven optimization.
Common Limitations of Image Processing Metrics: A Picture Story
Apr 13, 2021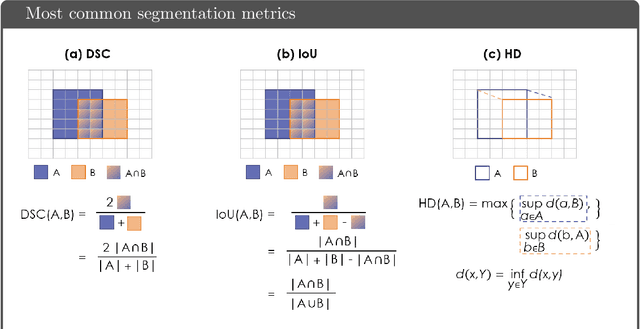
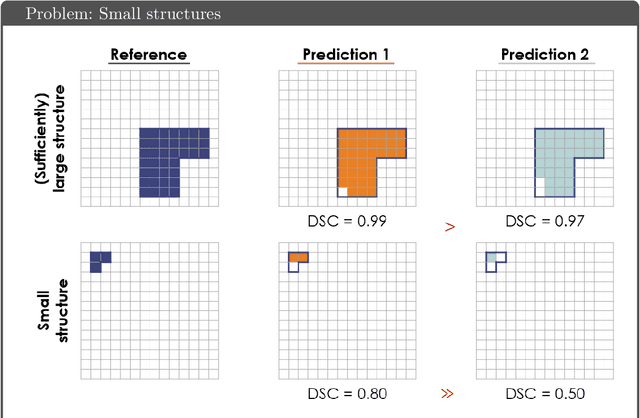
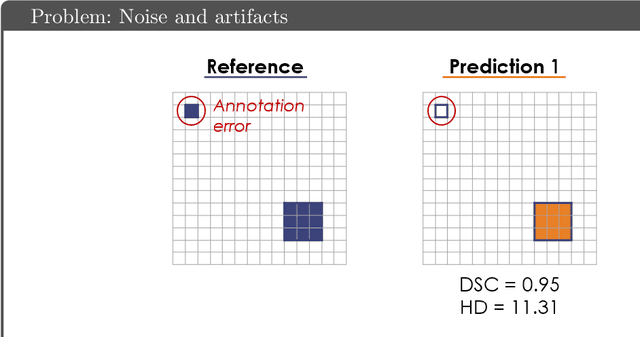
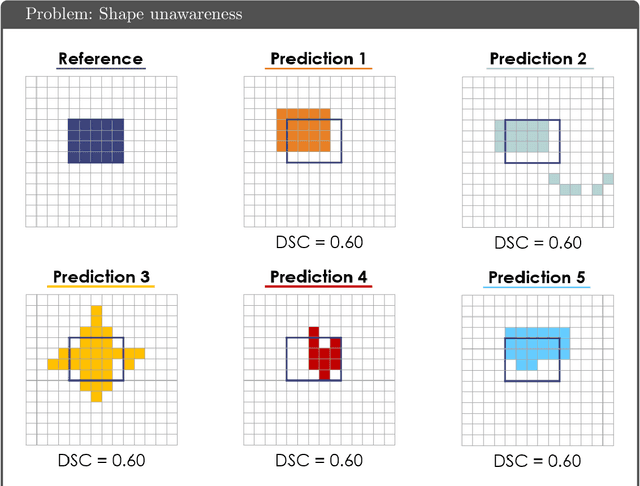
While the importance of automatic image analysis is increasing at an enormous pace, recent meta-research revealed major flaws with respect to algorithm validation. Specifically, performance metrics are key for objective, transparent and comparative performance assessment, but relatively little attention has been given to the practical pitfalls when using specific metrics for a given image analysis task. A common mission of several international initiatives is therefore to provide researchers with guidelines and tools to choose the performance metrics in a problem-aware manner. This dynamically updated document has the purpose to illustrate important limitations of performance metrics commonly applied in the field of image analysis. The current version is based on a Delphi process on metrics conducted by an international consortium of image analysis experts.