 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral-Purpose vs. Domain-Adapted Large Language Models for Extraction of Data from Thoracic Radiology Reports
Paper and Code
Dec 01, 2023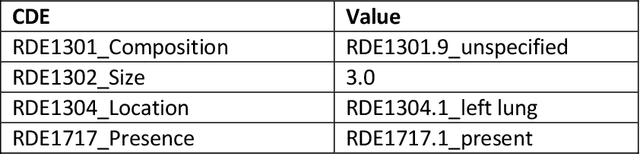
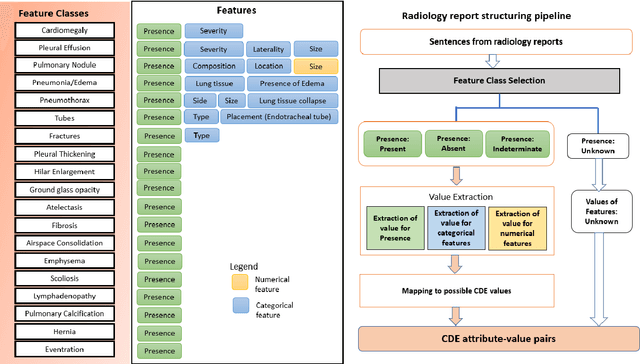
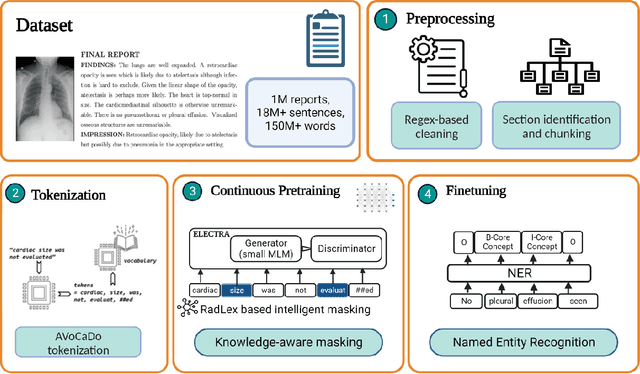
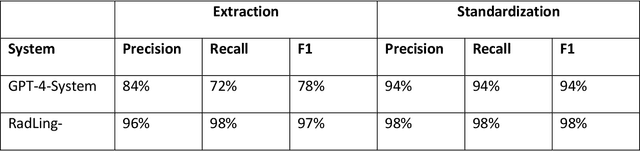
Radiologists produce unstructured data that could be valuable for clinical care when consumed by information systems. However, variability in style limits usage. Study compares performance of system using domain-adapted language model (RadLing) and general-purpose large language model (GPT-4) in extracting common data elements (CDE) from thoracic radiology reports. Three radiologists annotated a retrospective dataset of 1300 thoracic reports (900 training, 400 test) and mapped to 21 pre-selected relevant CDEs. RadLing was used to generate embeddings for sentences and identify CDEs using cosine-similarity, which were mapped to values using light-weight mapper. GPT-4 system used OpenAI's general-purpose embeddings to identify relevant CDEs and used GPT-4 to map to values. The output CDE:value pairs were compared to the reference standard; an identical match was considered true positive. Precision (positive predictive value) was 96% (2700/2824) for RadLing and 99% (2034/2047) for GPT-4. Recall (sensitivity) was 94% (2700/2876) for RadLing and 70% (2034/2887) for GPT-4; the difference was statistically significant (P<.001). RadLing's domain-adapted embeddings were more sensitive in CDE identification (95% vs 71%) and its light-weight mapper had comparable precision in value assignment (95.4% vs 95.0%). RadLing system exhibited higher performance than GPT-4 system in extracting CDEs from radiology reports. RadLing system's domain-adapted embeddings outperform general-purpose embeddings from OpenAI in CDE identification and its light-weight value mapper achieves comparable precision to large GPT-4. RadLing system offers operational advantages including local deployment and reduced runtime costs. Domain-adapted RadLing system surpasses GPT-4 system in extracting common data elements from radiology reports, while providing benefits of local deployment and lower costs.