 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReThinker: Scientific Reasoning by Rethinking with Guided Reflection and Confidence Control
Feb 04, 2026Expert-level scientific reasoning remains challenging for large language models, particularly on benchmarks such as Humanity's Last Exam (HLE), where rigid tool pipelines, brittle multi-agent coordination, and inefficient test-time scaling often limit performance. We introduce ReThinker, a confidence-aware agentic framework that orchestrates retrieval, tool use, and multi-agent reasoning through a stage-wise Solver-Critic-Selector architecture. Rather than following a fixed pipeline, ReThinker dynamically allocates computation based on model confidence, enabling adaptive tool invocation, guided multi-dimensional reflection, and robust confidence-weighted selection. To support scalable training without human annotation, we further propose a reverse data synthesis pipeline and an adaptive trajectory recycling strategy that transform successful reasoning traces into high-quality supervision. Experiments on HLE, GAIA, and XBench demonstrate that ReThinker consistently outperforms state-of-the-art foundation models with tools and existing deep research systems, achieving state-of-the-art results on expert-level reasoning tasks.
PyTSK: A Python Toolbox for TSK Fuzzy Systems
Jun 07, 2022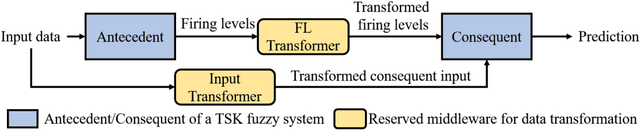
This paper presents PyTSK, a Python toolbox for developing Takagi-Sugeno-Kang (TSK) fuzzy systems. Based on scikit-learn and PyTorch, PyTSK allows users to optimize TSK fuzzy systems using fuzzy clustering or mini-batch gradient descent (MBGD) based algorithms. Several state-of-the-art MBGD-based optimization algorithms are implemented in the toolbox, which can improve the generalization performance of TSK fuzzy systems, especially for big data applications. PyTSK can also be easily extended and customized for more complicated algorithms, such as modifying the structure of TSK fuzzy systems, developing more sophisticated training algorithms, and combining TSK fuzzy systems with neural networks. The code of PyTSK can be found at https://github.com/YuqiCui/pytsk.
Curse of Dimensionality for TSK Fuzzy Neural Networks: Explanation and Solutions
Feb 08, 2021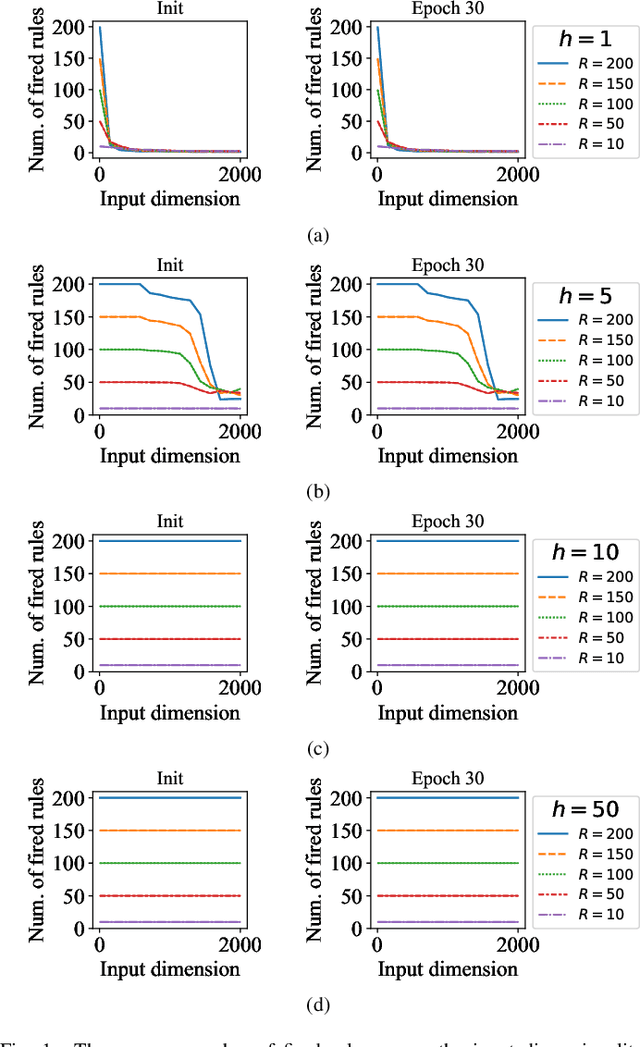
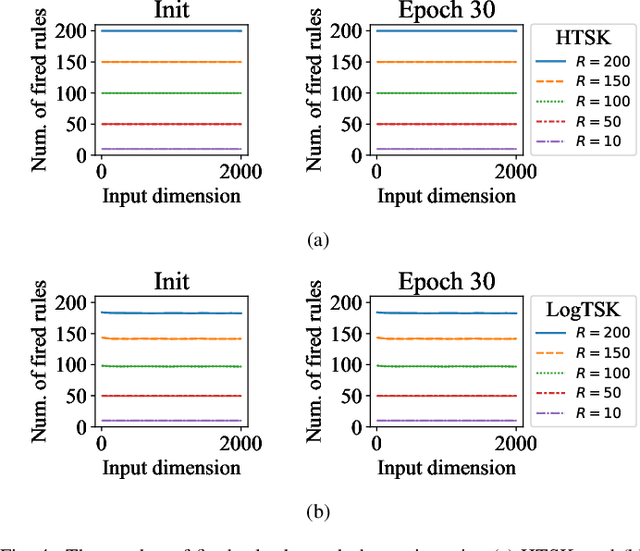
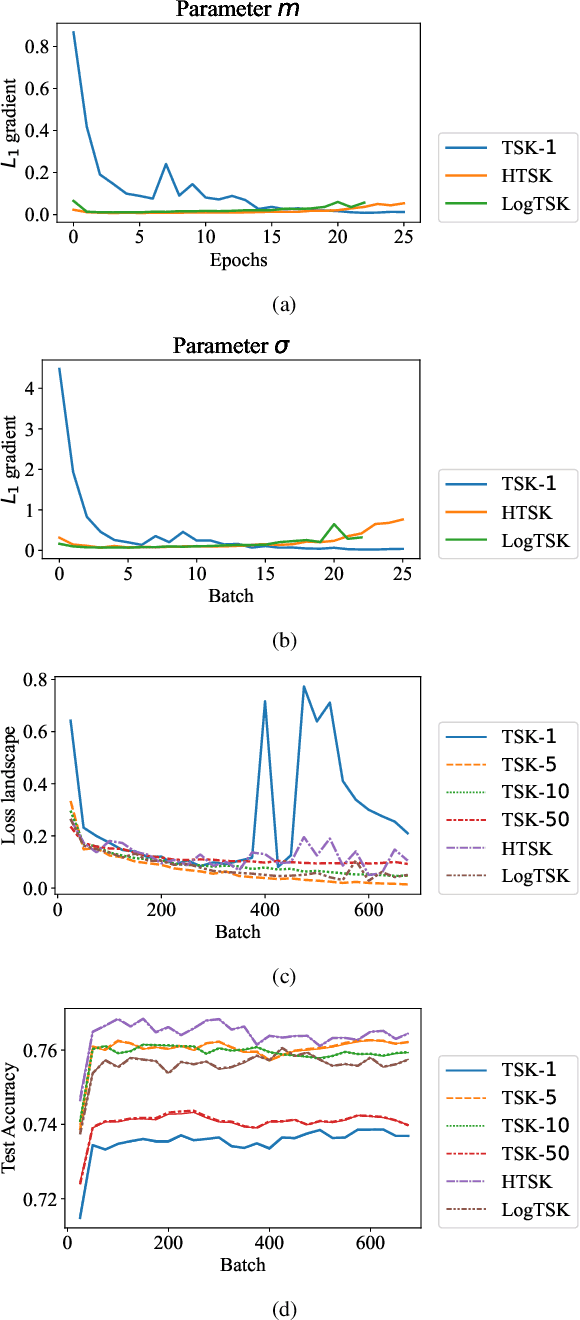
Takagi-Sugeno-Kang (TSK) fuzzy system with Gaussian membership functions (MFs) is one of the most widely used fuzzy systems in machine learning. However, it usually has difficulty handling high-dimensional datasets. This paper explores why TSK fuzzy systems with Gaussian MFs may fail on high-dimensional inputs. After transforming defuzzification to an equivalent form of softmax function, we find that the poor performance is due to the saturation of softmax. We show that two defuzzification operations, LogTSK and HTSK, the latter of which is first proposed in this paper, can avoid the saturation. Experimental results on datasets with various dimensionalities validated our analysis and demonstrated the effectiveness of LogTSK and HTSK.
FCM-RDpA: TSK Fuzzy Regression Model Construction Using Fuzzy C-Means Clustering, Regularization, DropRule, and Powerball AdaBelief
Nov 30, 2020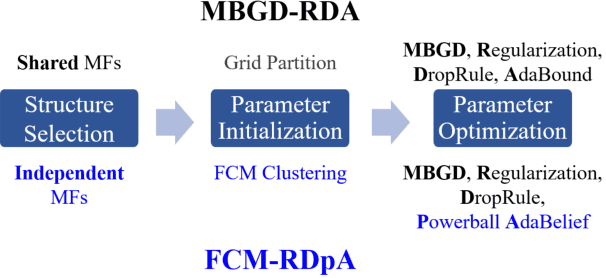
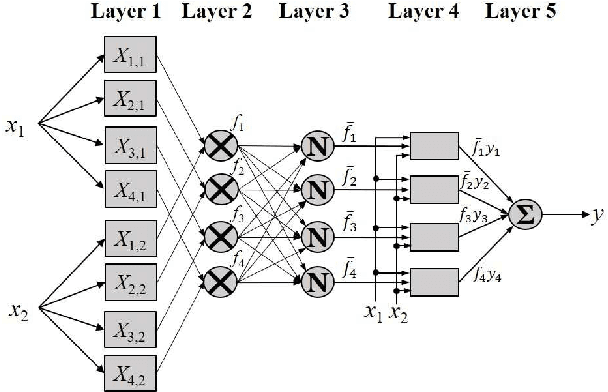
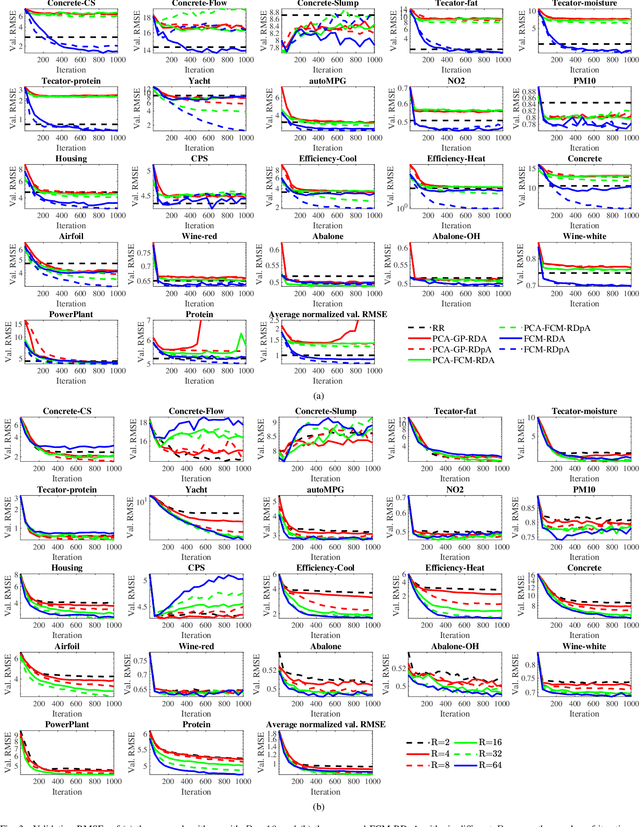
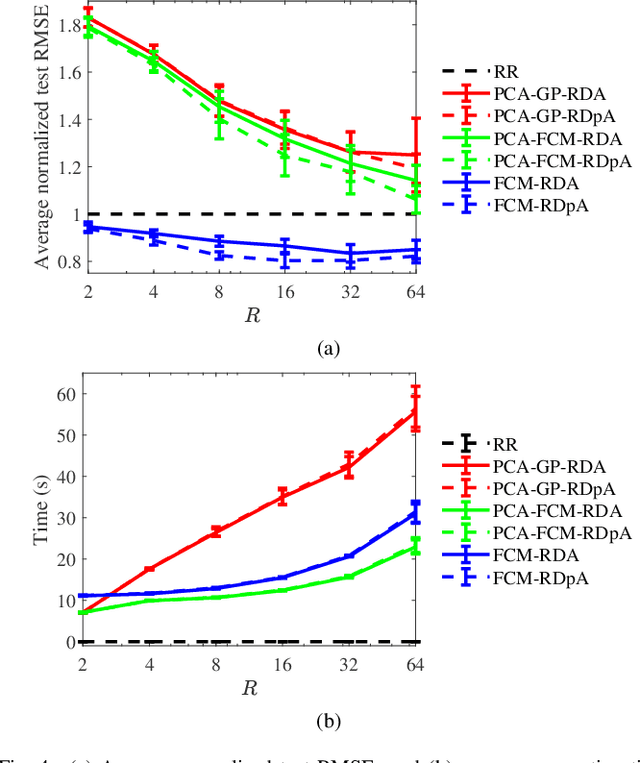
To effectively optimize Takagi-Sugeno-Kang (TSK) fuzzy systems for regression problems, a mini-batch gradient descent with regularization, DropRule, and AdaBound (MBGD-RDA) algorithm was recently proposed. This paper further proposes FCM-RDpA, which improves MBGD-RDA by replacing the grid partition approach in rule initialization by fuzzy c-means clustering, and AdaBound by Powerball AdaBelief, which integrates recently proposed Powerball gradient and AdaBelief to further expedite and stabilize parameter optimization. Extensive experiments on 22 regression datasets with various sizes and dimensionalities validated the superiority of FCM-RDpA over MBGD-RDA, especially when the feature dimensionality is higher. We also propose an additional approach, FCM-RDpAx, that further improves FCM-RDpA by using augmented features in both the antecedents and consequents of the rules.
Supervised Enhanced Soft Subspace Clustering (SESSC) for TSK Fuzzy Classifiers
Feb 27, 2020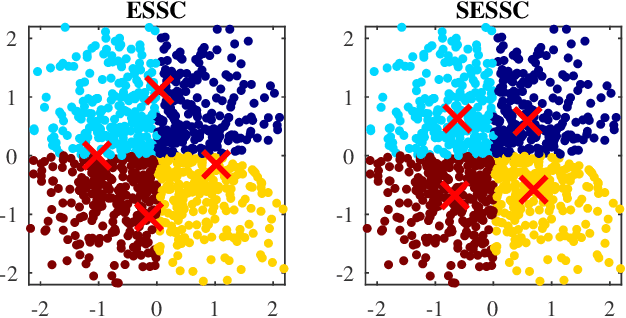
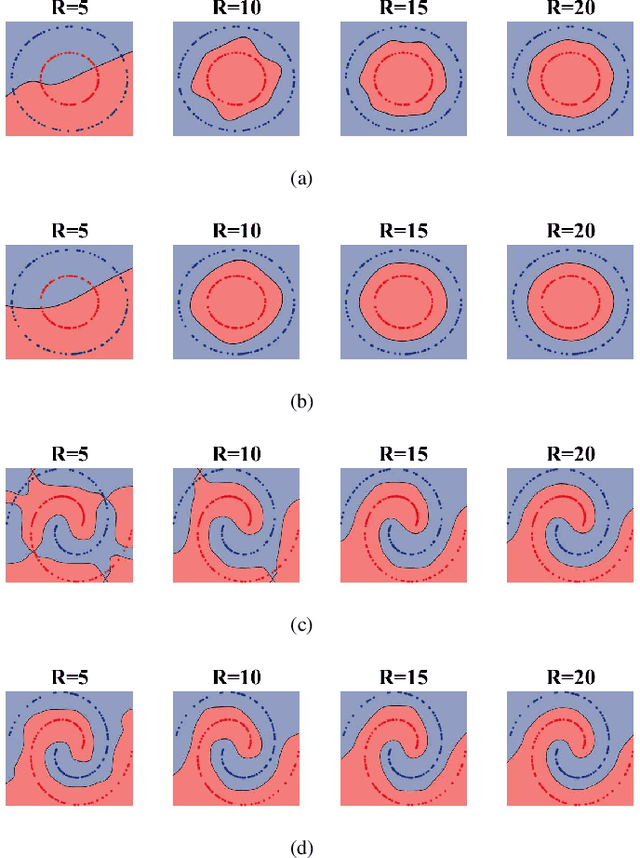
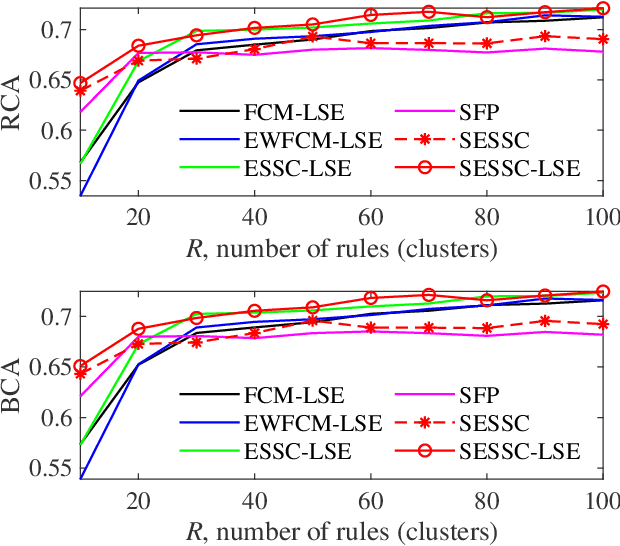
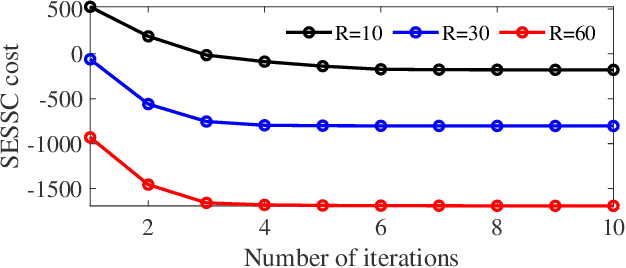
Fuzzy c-means based clustering algorithms are frequently used for Takagi-Sugeno-Kang (TSK) fuzzy classifier antecedent parameter estimation. One rule is initialized from each cluster. However, most of these clustering algorithms are unsupervised, which waste valuable label information in the training data. This paper proposes a supervised enhanced soft subspace clustering (SESSC) algorithm, which considers simultaneously the within-cluster compactness, between-cluster separation, and label information in clustering. It can effectively deal with high-dimensional data, be used as a classifier alone, or be integrated into a TSK fuzzy classifier to further improve its performance. Experiments on nine UCI datasets from various application domains demonstrated that SESSC based initialization outperformed other clustering approaches, especially when the number of rules is small.
In Vitro Fertilization (IVF) Cumulative Pregnancy Rate Prediction from Basic Patient Characteristics
Nov 10, 2019
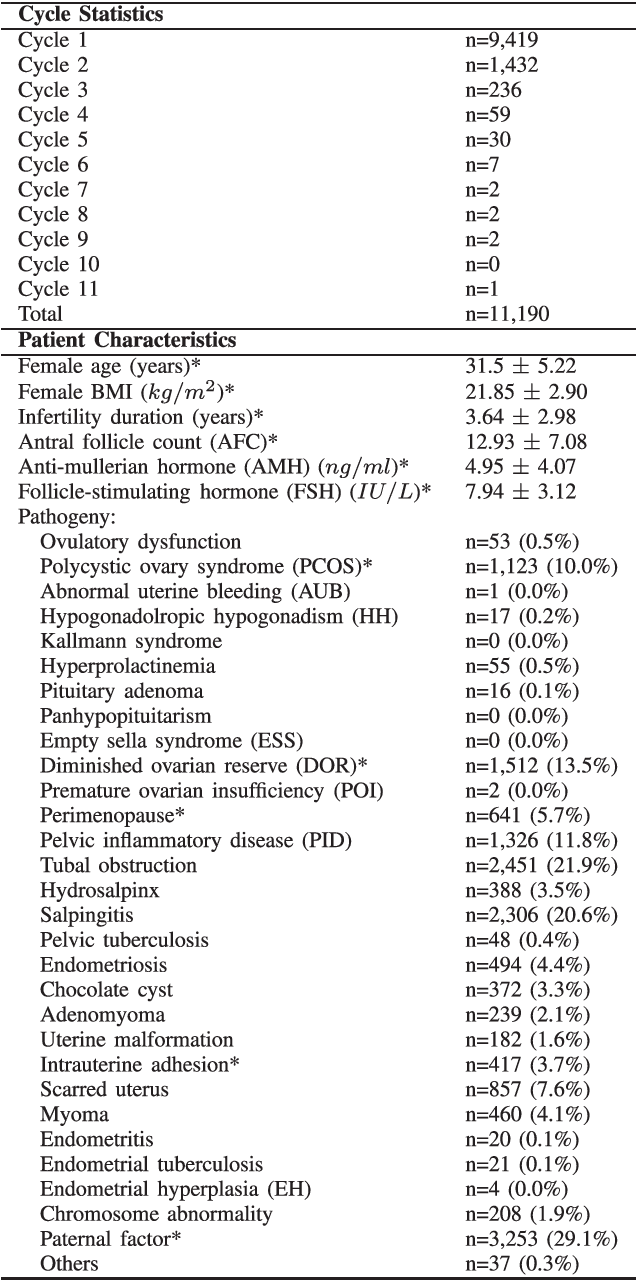
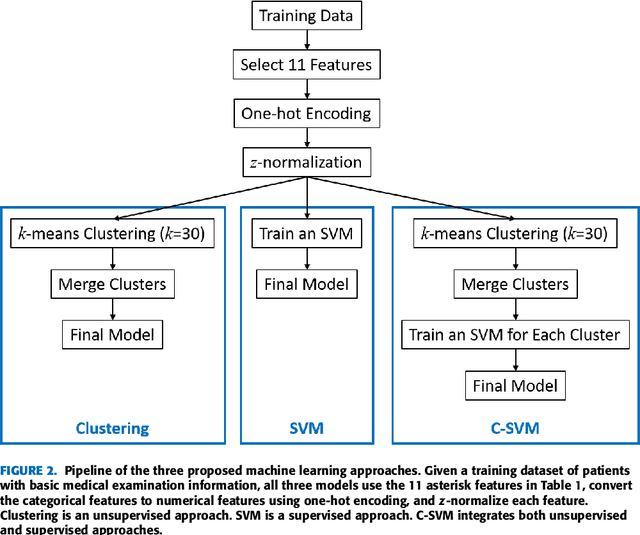

Tens of millions of women suffer from infertility worldwide each year. In vitro fertilization (IVF) is the best choice for many such patients. However, IVF is expensive, time-consuming, and both physically and emotionally demanding. The first question that a patient usually asks before the IVF is how likely she will conceive, given her basic medical examination information. This paper proposes three approaches to predict the cumulative pregnancy rate after multiple oocyte pickup cycles. Experiments on 11,190 patients showed that first clustering the patients into different groups and then building a support vector machine model for each group can achieve the best overall performance. Our model could be a quick and economic approach for reliably estimating the cumulative pregnancy rate for a patient, given only her basic medical examination information, well before starting the actual IVF procedure. The predictions can help the patient make optimal decisions on whether to use her own oocyte or donor oocyte, how many oocyte pickup cycles she may need, whether to use embryo frozen, etc. They will also reduce the patient's cost and time to pregnancy, and improve her quality of life.
Multi-Task Deep Learning with Dynamic Programming for Embryo Early Development Stage Classification from Time-Lapse Videos
Aug 22, 2019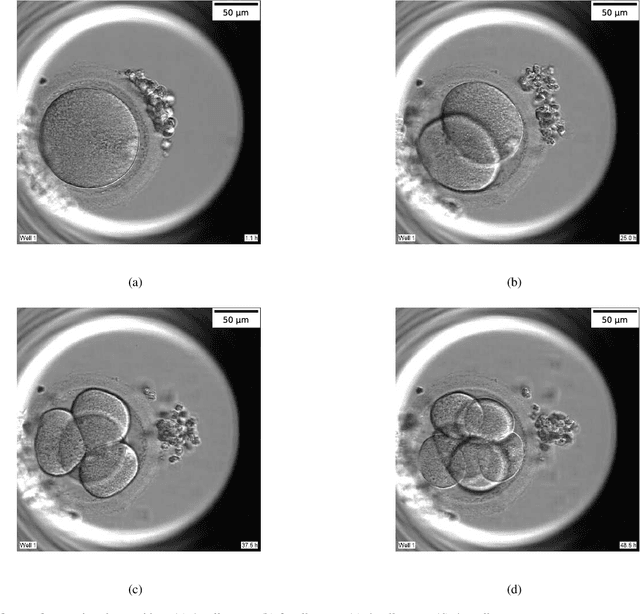
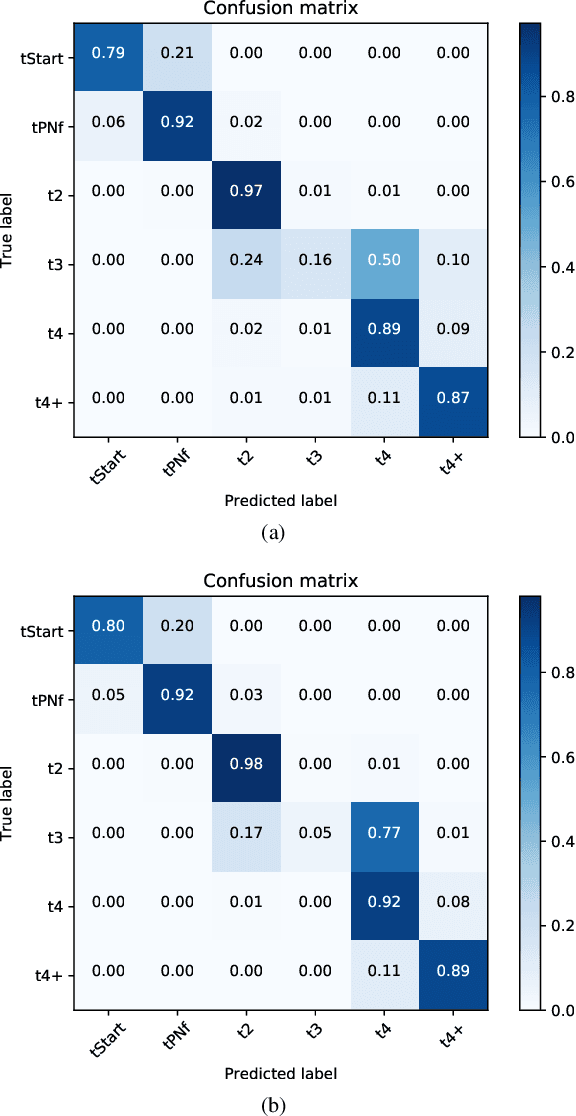
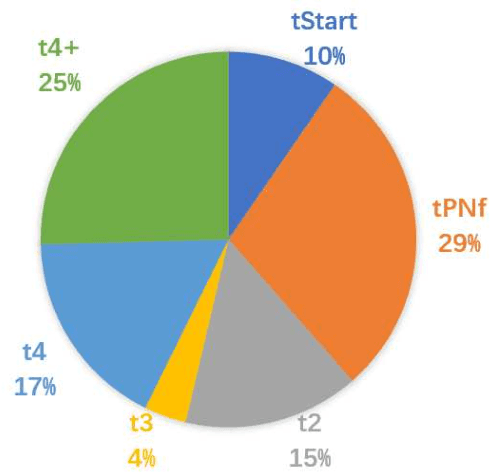
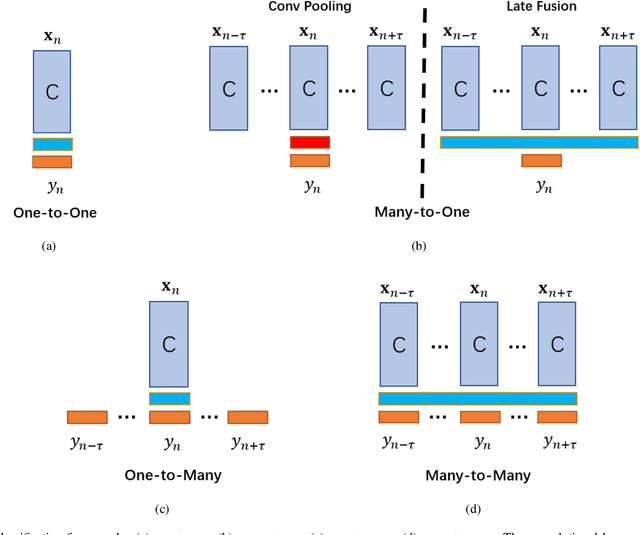
Time-lapse is a technology used to record the development of embryos during in-vitro fertilization (IVF). Accurate classification of embryo early development stages can provide embryologists valuable information for assessing the embryo quality, and hence is critical to the success of IVF. This paper proposes a multi-task deep learning with dynamic programming (MTDL-DP) approach for this purpose. It first uses MTDL to pre-classify each frame in the time-lapse video to an embryo development stage, and then DP to optimize the stage sequence so that the stage number is monotonically non-decreasing, which usually holds in practice. Different MTDL frameworks, e.g., one-to-many, many-to-one, and many-to-many, are investigated. It is shown that the one-to-many MTDL framework achieved the best compromise between performance and computational cost. To our knowledge, this is the first study that applies MTDL to embryo early development stage classification from time-lapse videos.
Optimize TSK Fuzzy Systems for Big Data Classification Problems: Bag of Tricks
Aug 01, 2019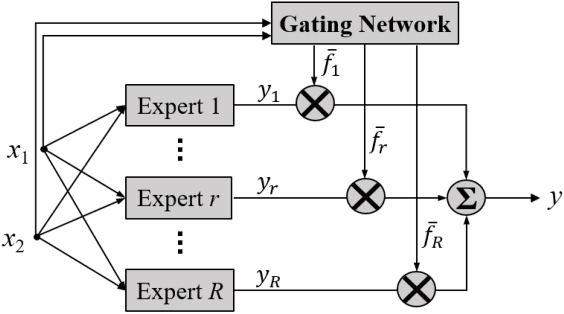
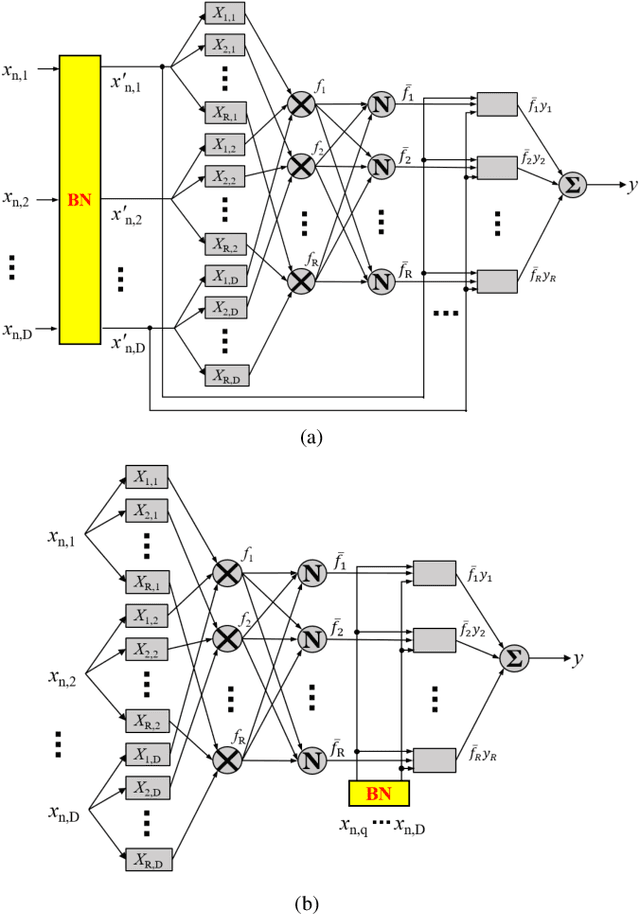
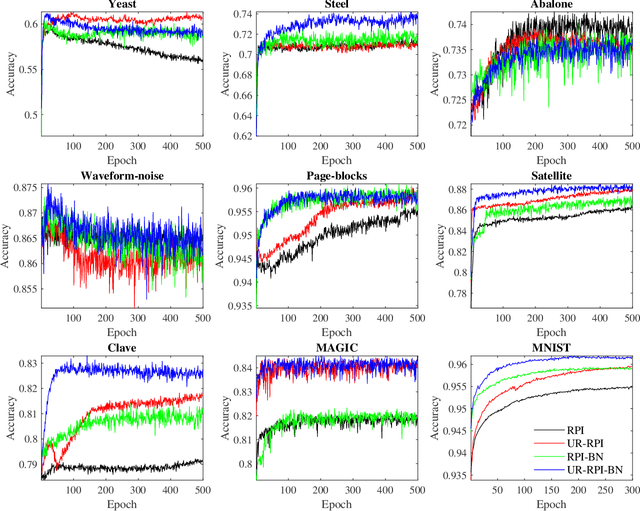
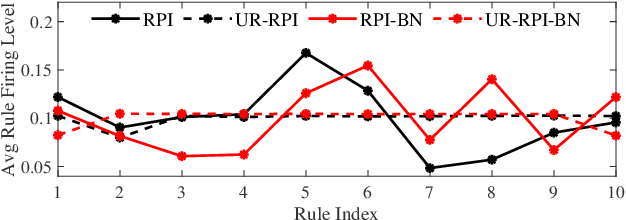
Takagi-Sugeno-Kang (TSK) fuzzy systems are flexible and interpretable machine learning models; however, they may not be easily applicable to big data problems, especially when the size and the dimensionality of the data are both large. This paper proposes a mini-batch gradient descent (MBGD) based algorithm to efficiently and effectively train TSK fuzzy systems for big data classification problems. It integrates three novel techniques: 1) uniform regularization (UR), which is a regularization term added to the loss function to make sure the rules have similar average firing levels, and hence better generalization performance; 2) random percentile initialization (RPI), which initializes the membership function parameters efficiently and reliably; and, 3) batch normalization (BN), which extends BN from deep neural networks to TSK fuzzy systems to speedup the convergence and improve generalization. Experiments on nine datasets from various application domains, with varying size and feature dimensionality, demonstrated that each of UR, RPI and BN has its own unique advantages, and integrating all three together can achieve the best classification performance.
EEG-Based Driver Drowsiness Estimation Using Convolutional Neural Networks
Aug 08, 2018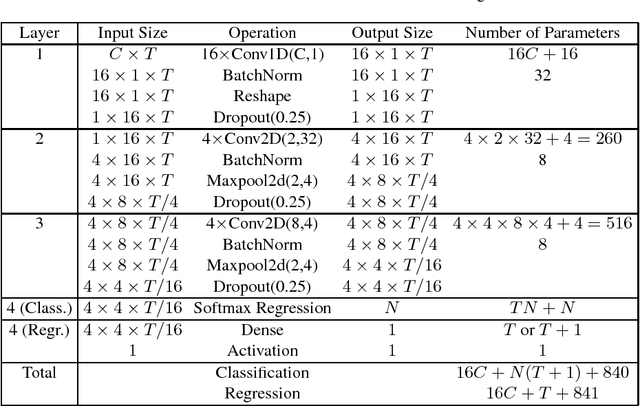
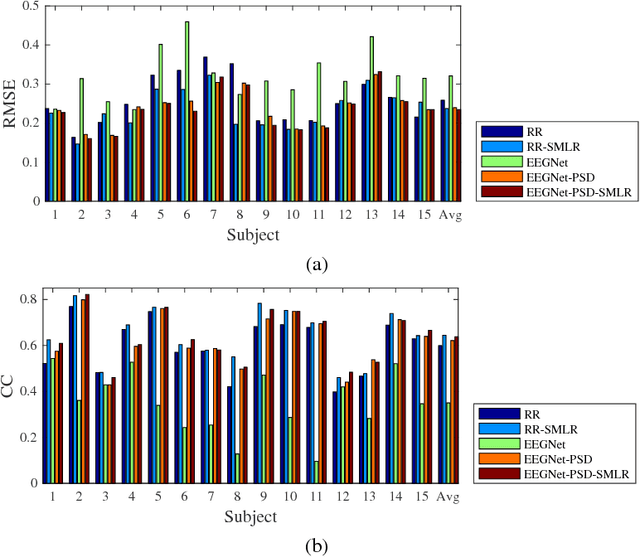

Deep learning, including convolutional neural networks (CNNs), has started finding applications in brain-computer interfaces (BCIs). However, so far most such approaches focused on BCI classification problems. This paper extends EEGNet, a 3-layer CNN model for BCI classification, to BCI regression, and also utilizes a novel spectral meta-learner for regression (SMLR) approach to aggregate multiple EEGNets for improved performance. Our model uses the power spectral density (PSD) of EEG signals as the input. Compared with raw EEG inputs, the PSD inputs can reduce the computational cost significantly, yet achieve much better regression performance. Experiments on driver drowsiness estimation from EEG signals demonstrate the outstanding performance of our approach.
OMG - Emotion Challenge Solution
Apr 30, 2018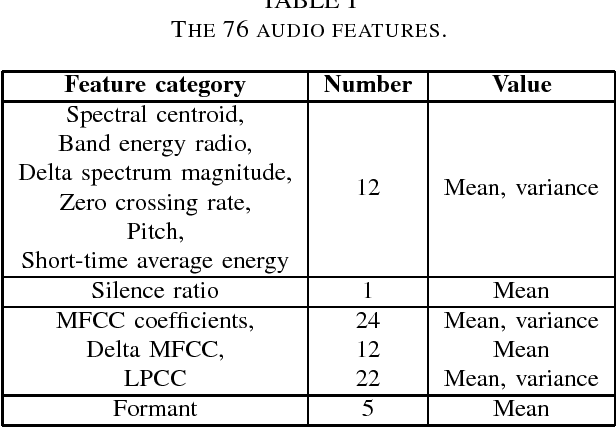
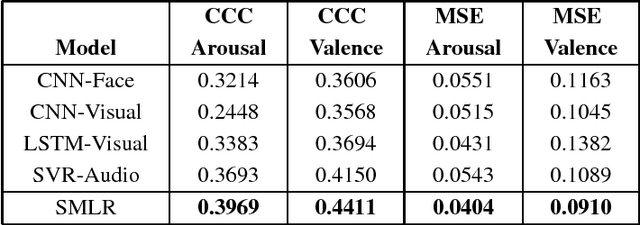
This short paper describes our solution to the 2018 IEEE World Congress on Computational Intelligence One-Minute Gradual-Emotional Behavior Challenge, whose goal was to estimate continuous arousal and valence values from short videos. We designed four base regression models using visual and audio features, and then used a spectral approach to fuse them to obtain improved performance.