 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimize TSK Fuzzy Systems for Big Data Classification Problems: Bag of Tricks
Paper and Code
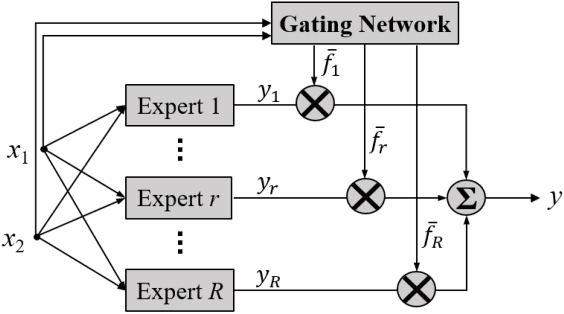
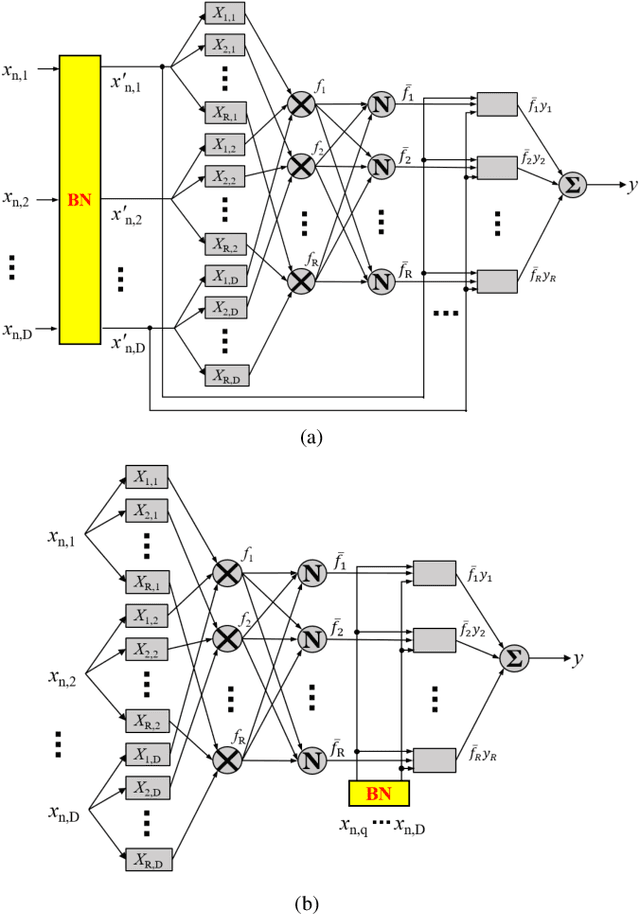
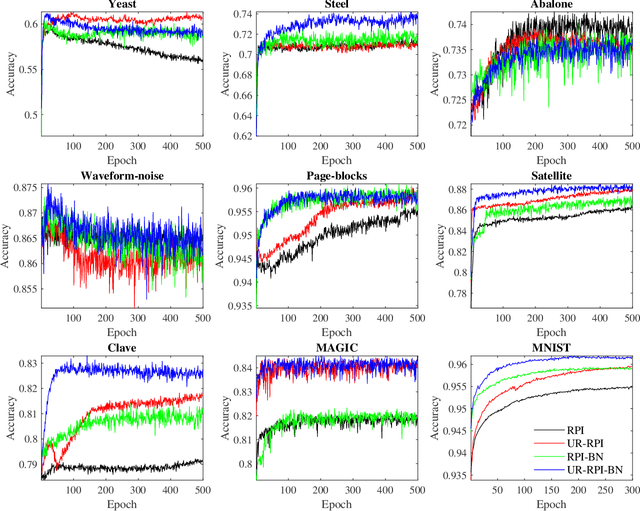
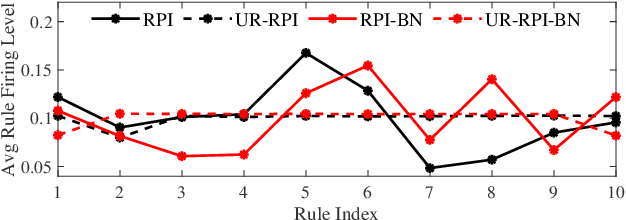
Takagi-Sugeno-Kang (TSK) fuzzy systems are flexible and interpretable machine learning models; however, they may not be easily applicable to big data problems, especially when the size and the dimensionality of the data are both large. This paper proposes a mini-batch gradient descent (MBGD) based algorithm to efficiently and effectively train TSK fuzzy systems for big data classification problems. It integrates three novel techniques: 1) uniform regularization (UR), which is a regularization term added to the loss function to make sure the rules have similar average firing levels, and hence better generalization performance; 2) random percentile initialization (RPI), which initializes the membership function parameters efficiently and reliably; and, 3) batch normalization (BN), which extends BN from deep neural networks to TSK fuzzy systems to speedup the convergence and improve generalization. Experiments on nine datasets from various application domains, with varying size and feature dimensionality, demonstrated that each of UR, RPI and BN has its own unique advantages, and integrating all three together can achieve the best classification performance.