 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaceController: Controllable Attribute Editing for Face in the Wild
Feb 23, 2021
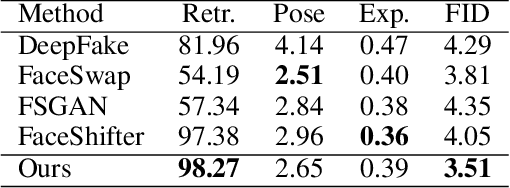

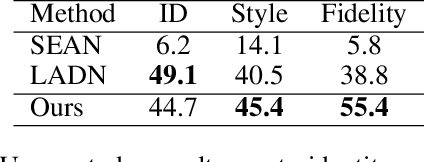
Face attribute editing aims to generate faces with one or multiple desired face attributes manipulated while other details are preserved. Unlike prior works such as GAN inversion, which has an expensive reverse mapping process, we propose a simple feed-forward network to generate high-fidelity manipulated faces. By simply employing some existing and easy-obtainable prior information, our method can control, transfer, and edit diverse attributes of faces in the wild. The proposed method can consequently be applied to various applications such as face swapping, face relighting, and makeup transfer. In our method, we decouple identity, expression, pose, and illumination using 3D priors; separate texture and colors by using region-wise style codes. All the information is embedded into adversarial learning by our identity-style normalization module. Disentanglement losses are proposed to enhance the generator to extract information independently from each attribute. Comprehensive quantitative and qualitative evaluations have been conducted. In a single framework, our method achieves the best or competitive scores on a variety of face applications.
NTIRE 2020 Challenge on Real Image Denoising: Dataset, Methods and Results
May 08, 2020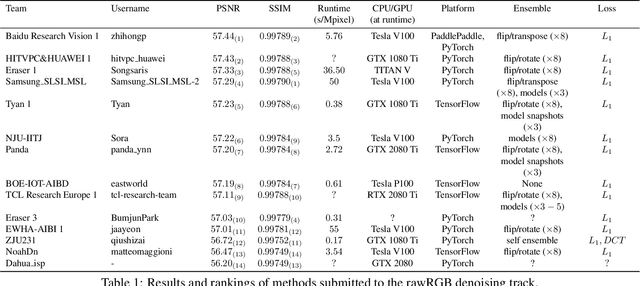
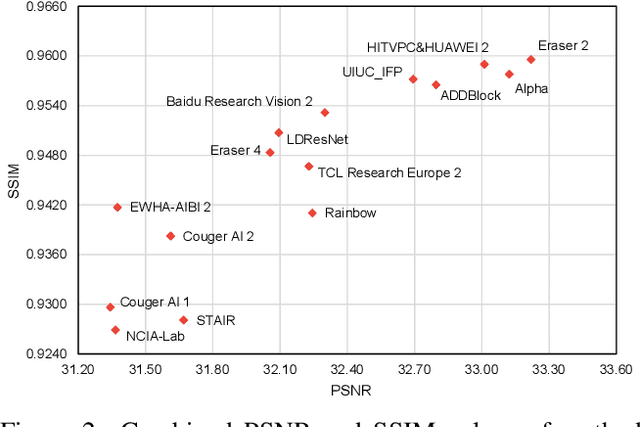
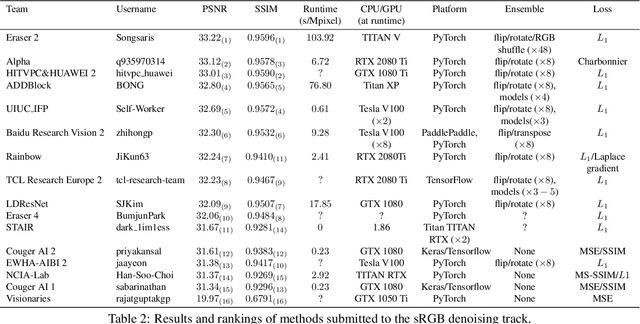
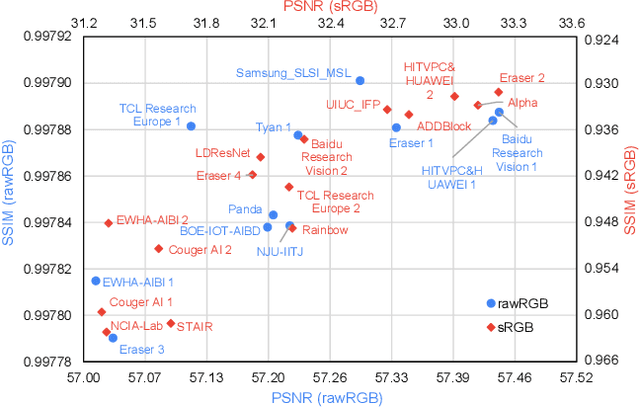
This paper reviews the NTIRE 2020 challenge on real image denoising with focus on the newly introduced dataset, the proposed methods and their results. The challenge is a new version of the previous NTIRE 2019 challenge on real image denoising that was based on the SIDD benchmark. This challenge is based on a newly collected validation and testing image datasets, and hence, named SIDD+. This challenge has two tracks for quantitatively evaluating image denoising performance in (1) the Bayer-pattern rawRGB and (2) the standard RGB (sRGB) color spaces. Each track ~250 registered participants. A total of 22 teams, proposing 24 methods, competed in the final phase of the challenge. The proposed methods by the participating teams represent the current state-of-the-art performance in image denoising targeting real noisy images. The newly collected SIDD+ datasets are publicly available at: https://bit.ly/siddplus_data.
Transfer Learning with Label Noise
Aug 08, 2018
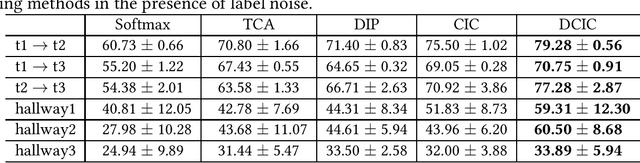
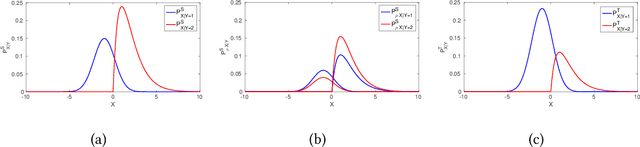
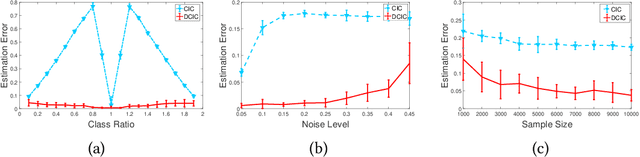
Transfer learning aims to improve learning in target domain by borrowing knowledge from a related but different source domain. To reduce the distribution shift between source and target domains, recent methods have focused on exploring invariant representations that have similar distributions across domains. However, when learning this invariant knowledge, existing methods assume that the labels in source domain are uncontaminated, while in reality, we often have access to source data with noisy labels. In this paper, we first show how label noise adversely affect the learning of invariant representations and the correcting of label shift in various transfer learning scenarios. To reduce the adverse effects, we propose a novel Denoising Conditional Invariant Component (DCIC) framework, which provably ensures (1) extracting invariant representations given examples with noisy labels in source domain and unlabeled examples in target domain; (2) estimating the label distribution in target domain with no bias. Experimental results on both synthetic and real-world data verify the effectiveness of the proposed method.
Learning with Biased Complementary Labels
Aug 08, 2018


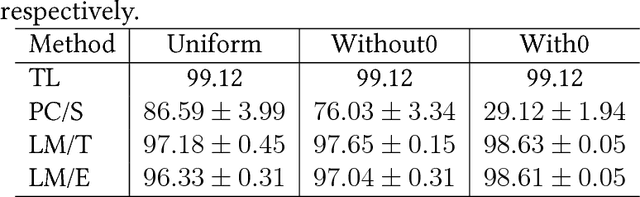
In this paper, we study the classification problem in which we have access to easily obtainable surrogate for true labels, namely complementary labels, which specify classes that observations do \textbf{not} belong to. Let $Y$ and $\bar{Y}$ be the true and complementary labels, respectively. We first model the annotation of complementary labels via transition probabilities $P(\bar{Y}=i|Y=j), i\neq j\in\{1,\cdots,c\}$, where $c$ is the number of classes. Previous methods implicitly assume that $P(\bar{Y}=i|Y=j), \forall i\neq j$, are identical, which is not true in practice because humans are biased toward their own experience. For example, as shown in Figure 1, if an annotator is more familiar with monkeys than prairie dogs when providing complementary labels for meerkats, she is more likely to employ "monkey" as a complementary label. We therefore reason that the transition probabilities will be different. In this paper, we propose a framework that contributes three main innovations to learning with \textbf{biased} complementary labels: (1) It estimates transition probabilities with no bias. (2) It provides a general method to modify traditional loss functions and extends standard deep neural network classifiers to learn with biased complementary labels. (3) It theoretically ensures that the classifier learned with complementary labels converges to the optimal one learned with true labels. Comprehensive experiments on several benchmark datasets validate the superiority of our method to current state-of-the-art methods.
Variance-Reduced Proximal Stochastic Gradient Descent for Non-convex Composite optimization
Sep 11, 2016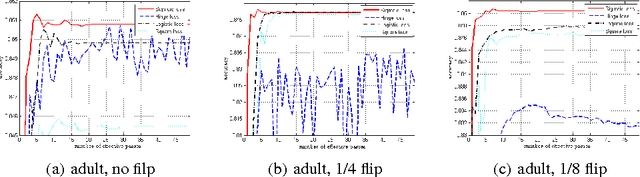
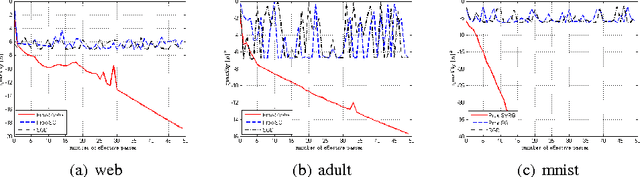
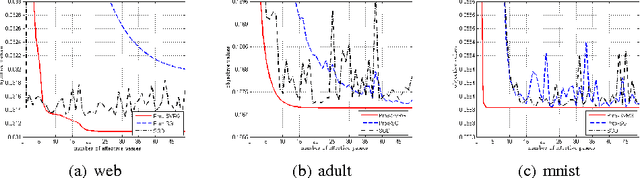
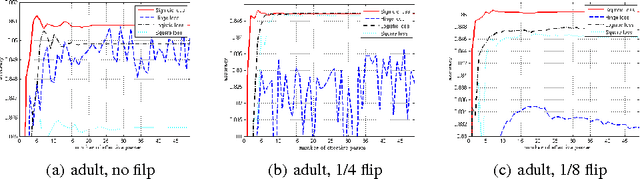
Here we study non-convex composite optimization: first, a finite-sum of smooth but non-convex functions, and second, a general function that admits a simple proximal mapping. Most research on stochastic methods for composite optimization assumes convexity or strong convexity of each function. In this paper, we extend this problem into the non-convex setting using variance reduction techniques, such as prox-SVRG and prox-SAGA. We prove that, with a constant step size, both prox-SVRG and prox-SAGA are suitable for non-convex composite optimization, and help the problem converge to a stationary point within $O(1/\epsilon)$ iterations. That is similar to the convergence rate seen with the state-of-the-art RSAG method and faster than stochastic gradient descent. Our analysis is also extended into the min-batch setting, which linearly accelerates the convergence. To the best of our knowledge, this is the first analysis of convergence rate of variance-reduced proximal stochastic gradient for non-convex composite optimization.