 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Biased Complementary Labels
Paper and Code



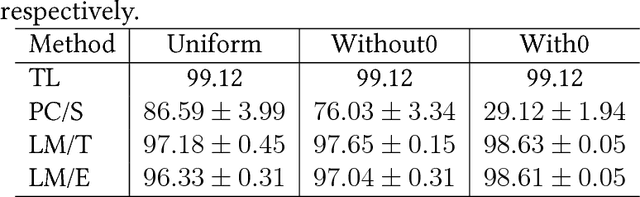
In this paper, we study the classification problem in which we have access to easily obtainable surrogate for true labels, namely complementary labels, which specify classes that observations do \textbf{not} belong to. Let $Y$ and $\bar{Y}$ be the true and complementary labels, respectively. We first model the annotation of complementary labels via transition probabilities $P(\bar{Y}=i|Y=j), i\neq j\in\{1,\cdots,c\}$, where $c$ is the number of classes. Previous methods implicitly assume that $P(\bar{Y}=i|Y=j), \forall i\neq j$, are identical, which is not true in practice because humans are biased toward their own experience. For example, as shown in Figure 1, if an annotator is more familiar with monkeys than prairie dogs when providing complementary labels for meerkats, she is more likely to employ "monkey" as a complementary label. We therefore reason that the transition probabilities will be different. In this paper, we propose a framework that contributes three main innovations to learning with \textbf{biased} complementary labels: (1) It estimates transition probabilities with no bias. (2) It provides a general method to modify traditional loss functions and extends standard deep neural network classifiers to learn with biased complementary labels. (3) It theoretically ensures that the classifier learned with complementary labels converges to the optimal one learned with true labels. Comprehensive experiments on several benchmark datasets validate the superiority of our method to current state-of-the-art methods.