 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGetting aligned on representational alignment
Nov 02, 2023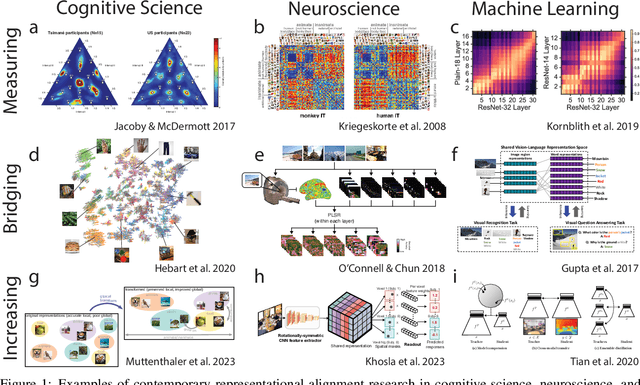
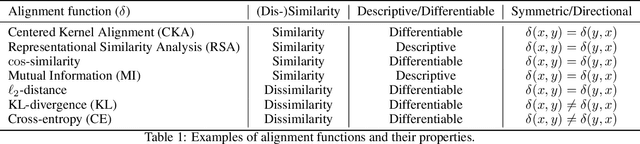
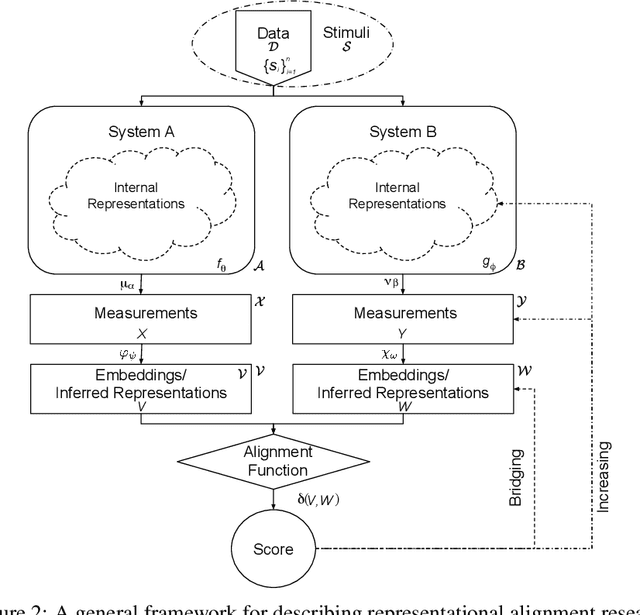
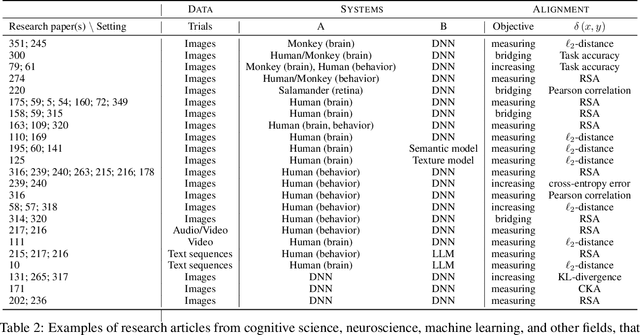
Biological and artificial information processing systems form representations that they can use to categorize, reason, plan, navigate, and make decisions. How can we measure the extent to which the representations formed by these diverse systems agree? Do similarities in representations then translate into similar behavior? How can a system's representations be modified to better match those of another system? These questions pertaining to the study of representational alignment are at the heart of some of the most active research areas in cognitive science, neuroscience, and machine learning. For example, cognitive scientists measure the representational alignment of multiple individuals to identify shared cognitive priors, neuroscientists align fMRI responses from multiple individuals into a shared representational space for group-level analyses, and ML researchers distill knowledge from teacher models into student models by increasing their alignment. Unfortunately, there is limited knowledge transfer between research communities interested in representational alignment, so progress in one field often ends up being rediscovered independently in another. Thus, greater cross-field communication would be advantageous. To improve communication between these fields, we propose a unifying framework that can serve as a common language between researchers studying representational alignment. We survey the literature from all three fields and demonstrate how prior work fits into this framework. Finally, we lay out open problems in representational alignment where progress can benefit all three of these fields. We hope that our work can catalyze cross-disciplinary collaboration and accelerate progress for all communities studying and developing information processing systems. We note that this is a working paper and encourage readers to reach out with their suggestions for future revisions.
Approaching human 3D shape perception with neurally mappable models
Sep 07, 2023Humans effortlessly infer the 3D shape of objects. What computations underlie this ability? Although various computational models have been proposed, none of them capture the human ability to match object shape across viewpoints. Here, we ask whether and how this gap might be closed. We begin with a relatively novel class of computational models, 3D neural fields, which encapsulate the basic principles of classic analysis-by-synthesis in a deep neural network (DNN). First, we find that a 3D Light Field Network (3D-LFN) supports 3D matching judgments well aligned to humans for within-category comparisons, adversarially-defined comparisons that accentuate the 3D failure cases of standard DNN models, and adversarially-defined comparisons for algorithmically generated shapes with no category structure. We then investigate the source of the 3D-LFN's ability to achieve human-aligned performance through a series of computational experiments. Exposure to multiple viewpoints of objects during training and a multi-view learning objective are the primary factors behind model-human alignment; even conventional DNN architectures come much closer to human behavior when trained with multi-view objectives. Finally, we find that while the models trained with multi-view learning objectives are able to partially generalize to new object categories, they fall short of human alignment. This work provides a foundation for understanding human shape inferences within neurally mappable computational architectures.
Beyond Flatland: Pre-training with a Strong 3D Inductive Bias
Nov 30, 2021
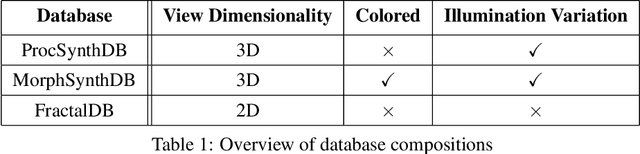

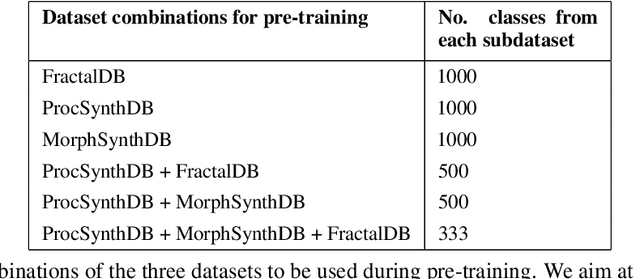
Pre-training on large-scale databases consisting of natural images and then fine-tuning them to fit the application at hand, or transfer-learning, is a popular strategy in computer vision. However, Kataoka et al., 2020 introduced a technique to eliminate the need for natural images in supervised deep learning by proposing a novel synthetic, formula-based method to generate 2D fractals as training corpus. Using one synthetically generated fractal for each class, they achieved transfer learning results comparable to models pre-trained on natural images. In this project, we take inspiration from their work and build on this idea -- using 3D procedural object renders. Since the image formation process in the natural world is based on its 3D structure, we expect pre-training with 3D mesh renders to provide an implicit bias leading to better generalization capabilities in a transfer learning setting and that invariances to 3D rotation and illumination are easier to be learned based on 3D data. Similar to the previous work, our training corpus will be fully synthetic and derived from simple procedural strategies; we will go beyond classic data augmentation and also vary illumination and pose which are controllable in our setting and study their effect on transfer learning capabilities in context to prior work. In addition, we will compare the 2D fractal and 3D procedural object networks to human and non-human primate brain data to learn more about the 2D vs. 3D nature of biological vision.