 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNyquist Signaling Modulation (NSM): An FTN-Inspired Paradigm Shift in Modulation Design for 6G and Beyond
Nov 11, 2025
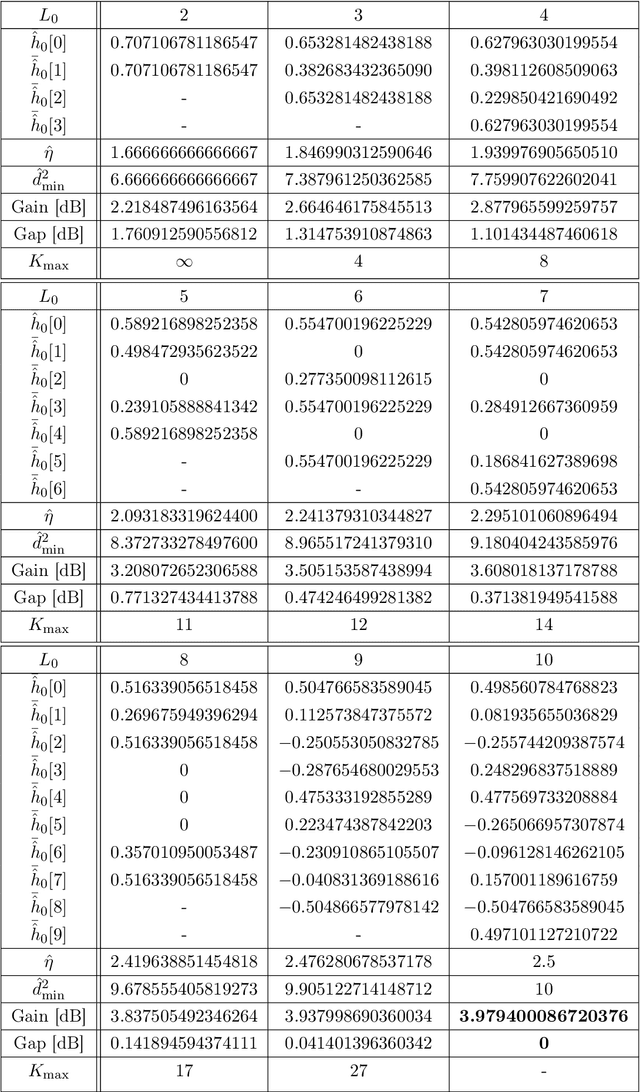
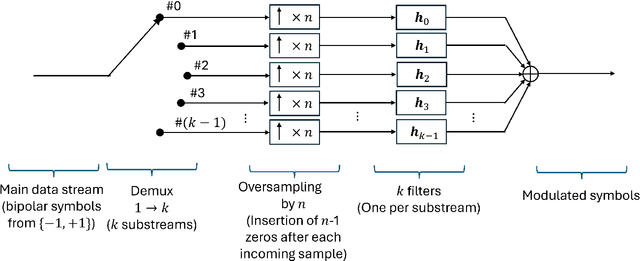

Nyquist Signaling Modulations (NSMs) are a new signaling paradigm inspired by faster-than-Nyquist principles but based on a distinct approach that enables controlled inter-symbol interference through carefully designed finite-impulse-response filters. NSMs can operate in any number of dimensions, including mixed-dimensional configurations, offering wide flexibility in filter design, optional energy balancing, and preservation of the 2-ASK minimum squared Euclidean distance (MSED). Both real and rational tapped filters are investigated, and closed-form expressions are derived for the optimal real-tap filters in the one-dimensional case (MS-PRS), providing analytical insight and strong agreement with simulated bit-error behavior across wide SNR ranges. The paradigm is conceptually expanded through an analog Low-Density Generator Matrix (LDGM) formulation, which broadens the NSM family and unifies modulation and coding within a single, structurally coherent framework. When combined with LDPC coding, it enables efficient and naturally synergistic interaction between the analog modulation and the digital LDPC code. Alternatively, when analog LDGM is employed for both source coding and modulation, a simple and harmonious joint source-channel-modulation structure emerges. In both configurations, the constituent blocks exhibit dual graph-based architectures suited to message passing, achieving high flexibility and complexity-efficient operation. Collectively, these results establish promising physical-layer directions for future 6G communication systems.
Radio-PPG: photoplethysmogram digital twin synthesis using deep neural representation of 6G/WiFi ISAC signals
Sep 26, 2025
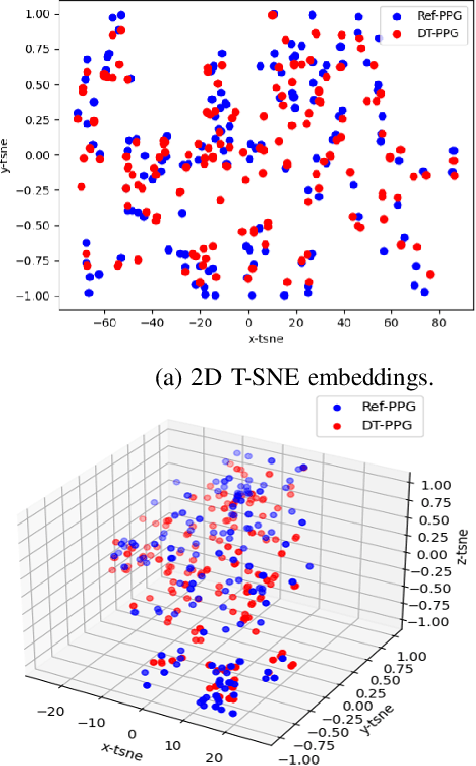
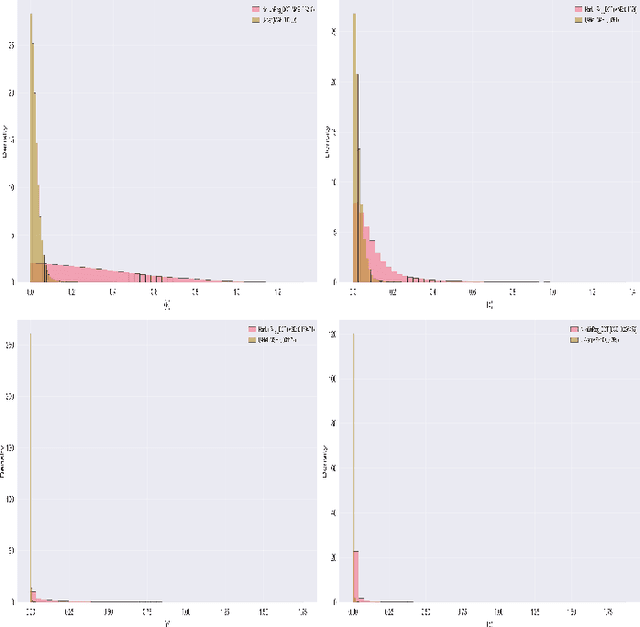
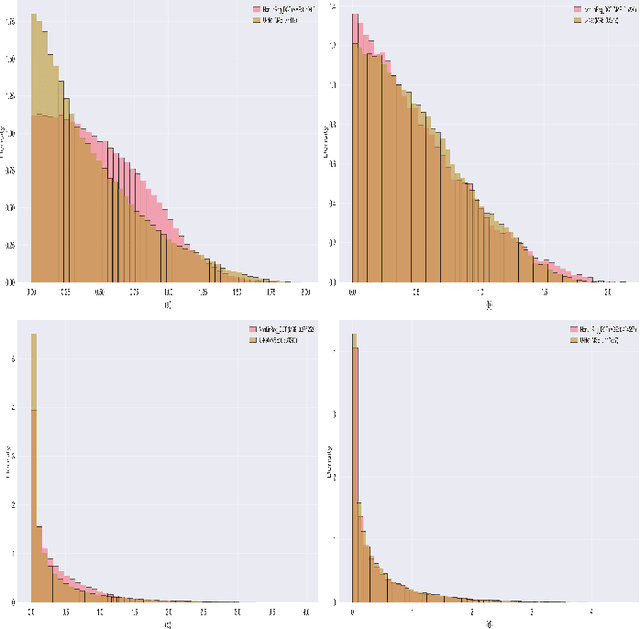
Digital twins for 1D bio-signals enable real-time monitoring of physiological processes of a person, which enables early disease diagnosis and personalized treatment. This work introduces a novel non-contact method for digital twin (DT) photoplethysmogram (PPG) signal synthesis under the umbrella of 6G/WiFi integrated sensing and communication (ISAC) systems. We employ a software-defined radio (SDR) operating at 5.23 GHz that illuminates the chest of a nearby person with a wideband 6G/WiFi signal and collects the reflected signals. This allows us to acquire Radio-PPG dataset that consists of 300 minutes worth of near synchronous 64-channel radio data, PPG data, along with the labels (three body vitals) of 30 healthy subjects. With this, we test two artificial intelligence (AI) models for DT-PPG signal synthesis: i) discrete cosine transform followed by a multi-layer perceptron, ii) two U-NET models (Approximation network, Refinement network) in cascade, along with a custom loss function. Experimental results indicate that U-NET model achieves an impressive relative mean absolute error of 0.194 with a small ISAC sensing overhead of 15.62%, for DT-PPG synthesis. Furthermore, we performed quality assessment of the synthetic DT-PPG by computing the accuracy of DT-PPG-based vitals estimation and feature extraction, which turned out to be at par with that of reference PPG-based vitals estimation and feature extraction. This work highlights the potential of generative AI and 6G/WiFi ISAC technologies and serves as a foundational step towards the development of non-contact screening tools for covid-19, cardiovascular diseases and well-being assessment of people with special needs.
Indoor Position and Attitude Tracking with SO(3) Manifold
Jan 02, 2025



Driven by technological breakthroughs, indoor tracking and localization have gained importance in various applications including the Internet of Things (IoT), robotics, and unmanned aerial vehicles (UAVs). To tackle some of the challenges associated with indoor tracking, this study explores the potential benefits of incorporating the SO(3) manifold structure of the rotation matrix. The goal is to enhance the 3D tracking performance of the extended Kalman filter (EKF) and unscented Kalman filter (UKF) of a moving target within an indoor environment. Our results demonstrate that the proposed extended Kalman filter with Riemannian (EKFRie) and unscented Kalman filter with Riemannian (UKFRie) algorithms consistently outperform the conventional EKF and UKF in terms of position and orientation accuracy. While the conventional EKF and UKF achieved root mean square error (RMSE) of 0.36m and 0.43m, respectively, for a long stair path, the proposed EKFRie and UKFRie algorithms achieved a lower RMSE of 0.21m and 0.10m. Our results show also the outperforming of the proposed algorithms over the EKF and UKF algorithms with the Isosceles triangle manifold. While the latter achieved RMSE of 7.26cm and 7.27cm, respectively, our proposed algorithms achieved RMSE of 6.73cm and 6.16cm. These results demonstrate the enhanced performance of the proposed algorithms.
Non-Contact Acquisition of PPG Signal using Chest Movement-Modulated Radio Signals
Feb 22, 2024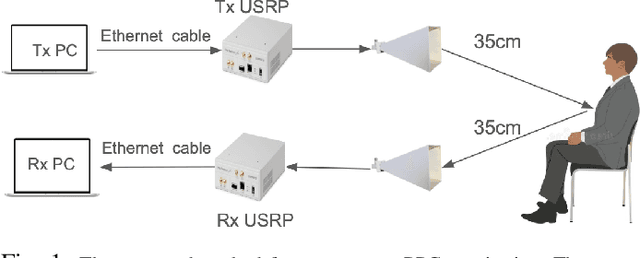
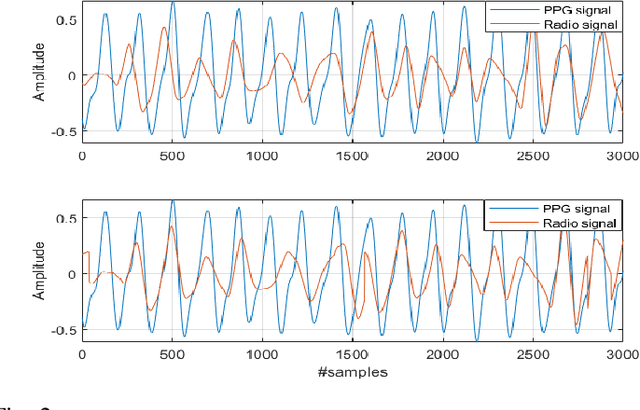
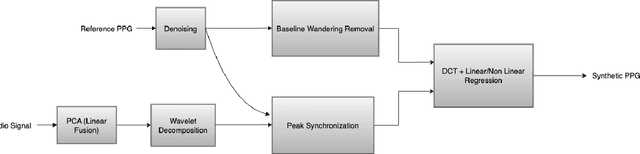
We present for the first time a novel method that utilizes the chest movement-modulated radio signals for non-contact acquisition of the photoplethysmography (PPG) signal. Under the proposed method, a software-defined radio (SDR) exposes the chest of a subject sitting nearby to an orthogonal frequency division multiplexing signal with 64 sub-carriers at a center frequency 5.24 GHz, while another SDR in the close vicinity collects the modulated radio signal reflected off the chest. This way, we construct a custom dataset by collecting 160 minutes of labeled data (both raw radio data as well as the reference PPG signal) from 16 healthy young subjects. With this, we first utilize principal component analysis for dimensionality reduction of the radio data. Next, we denoise the radio signal and reference PPG signal using wavelet technique, followed by segmentation and Z-score normalization. We then synchronize the radio and PPG segments using cross-correlation method. Finally, we proceed to the waveform translation (regression) task, whereby we first convert the radio and PPG segments into frequency domain using discrete cosine transform (DCT), and then learn the non-linear regression between them. Eventually, we reconstruct the synthetic PPG signal by taking inverse DCT of the output of regression block, with a mean absolute error of 8.1294. The synthetic PPG waveform has a great clinical significance as it could be used for non-contact performance assessment of cardiovascular and respiratory systems of patients suffering from infectious diseases, e.g., covid19.
On the Interplay of Artificial Intelligence and Space-Air-Ground Integrated Networks: A Survey
Jan 20, 2024



Space-Air-Ground Integrated Networks (SAGINs), which incorporate space and aerial networks with terrestrial wireless systems, are vital enablers of the emerging sixth-generation (6G) wireless networks. Besides bringing significant benefits to various applications and services, SAGINs are envisioned to extend high-speed broadband coverage to remote areas, such as small towns or mining sites, or areas where terrestrial infrastructure cannot reach, such as airplanes or maritime use cases. However, due to the limited power and storage resources, as well as other constraints introduced by the design of terrestrial networks, SAGINs must be intelligently configured and controlled to satisfy the envisioned requirements. Meanwhile, Artificial Intelligence (AI) is another critical enabler of 6G. Due to massive amounts of available data, AI has been leveraged to address pressing challenges of current and future wireless networks. By adding AI and facilitating the decision-making and prediction procedures, SAGINs can effectively adapt to their surrounding environment, thus enhancing the performance of various metrics. In this work, we aim to investigate the interplay of AI and SAGINs by providing a holistic overview of state-of-the-art research in AI-enabled SAGINs. Specifically, we present a comprehensive overview of some potential applications of AI in SAGINs. We also cover open issues in employing AI and detail the contributions of SAGINs in the development of AI. Finally, we highlight some limitations of the existing research works and outline potential future research directions.
Multi-RIS-Enabled 3D Sidelink Positioning
Feb 24, 2023



Positioning is expected to be a core function in intelligent transportation systems (ITSs) to support communication and location-based services, such as autonomous driving, traffic control, etc. With the advent of low-cost reflective reconfigurable intelligent surfaces (RISs) to be deployed in beyond 5G/6G networks, extra anchors with high angular resolutions can boost signal quality and makes high-precision positioning with extended coverage possible in ITS scenarios. However, the passive nature of the RIS requires a signal source such as a base station (BS), which limits the positioning service in extreme situations, such as tunnels or dense urban areas, where 5G/6G BSs are not accessible. In this work, we show that with the assistance of (at least) two RISs and sidelink communication between two user equipments (UEs), these UEs can be localized even without any BSs involvement. A two-stage 3D sidelink positioning algorithm is proposed, benchmarked by the derived Cram\'er-Rao bounds. The effects of multipath and RIS profile designs on positioning performance are evaluated, and several scenarios with different RIS and UE locations are discussed for localizability analysis. Simulation results demonstrate the promising positioning accuracy of the proposed BS-free sidelink communication system in challenging ITS scenarios. Additionally, we propose and evaluate several solutions to eliminate potential blind areas where positioning performance is poor, such as removing clock offset via round-trip communication, adding geometrical prior or constraints, as well as introducing more RISs.
Equitable 6G Access Service via Cloud-Enabled HAPS for Optimizing Hybrid Air-Ground Networks
Dec 05, 2022



The evolvement of wireless communication services concurs with significant growth in data traffic, thereby inflicting stringent requirements on terrestrial networks. This work invigorates a novel connectivity solution that integrates aerial and terrestrial communications with a cloud-enabled high-altitude platform station (HAPS) to promote an equitable connectivity landscape. Consider a cloud-enabled HAPS connected to both terrestrial base-stations and hot-air balloons via a data-sharing fronthauling strategy. The paper then assumes that both the terrestrial base-stations and the hot-air balloons are grouped into disjoint clusters to serve the aerial and terrestrial users in a coordinated fashion. The work then focuses on finding the user-to-transmitter scheduling and the associated beamforming policies in the downlink direction of cloud-enabled HAPS systems by maximizing two different objectives, namely, the sum-rate and sum-of-log of the long-term average rate, both subject to limited transmit power and finite fronthaul capacity. The paper proposes solving the two non-convex discrete and continuous optimization problems using numerical iterative optimization algorithms. The proposed algorithms rely on well-chosen convexification and approximation steps, namely, fractional programming and sparse beamforming via re-weighted $\ell_0$-norm approximation. The numerical results outline the yielded gain illustrated through equitable access service in crowded and unserved areas, and showcase the numerical benefits stemming from the proposed cloud-enabled HAPS coordination of hot-air balloons and terrestrial base-stations for democratizing connectivity and empowering the digital inclusion framework.
Weight Vector Tuning and Asymptotic Analysis of Binary Linear Classifiers
Oct 01, 2021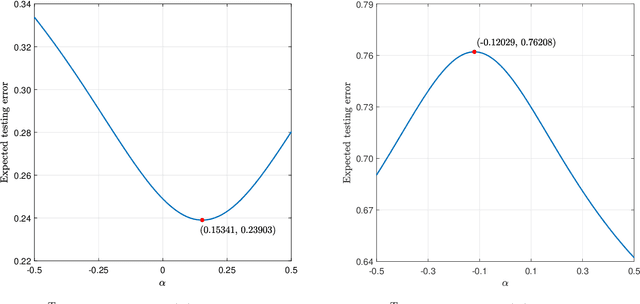
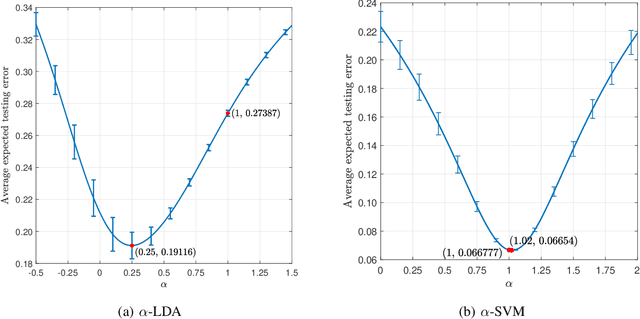
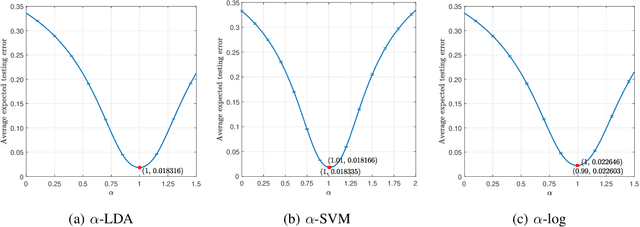
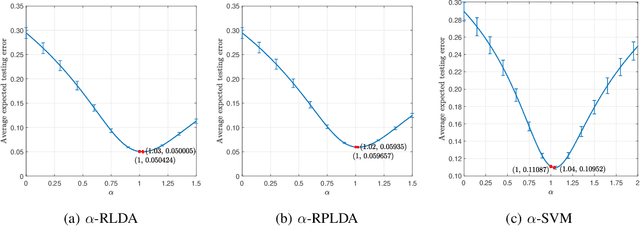
Unlike its intercept, a linear classifier's weight vector cannot be tuned by a simple grid search. Hence, this paper proposes weight vector tuning of a generic binary linear classifier through the parameterization of a decomposition of the discriminant by a scalar which controls the trade-off between conflicting informative and noisy terms. By varying this parameter, the original weight vector is modified in a meaningful way. Applying this method to a number of linear classifiers under a variety of data dimensionality and sample size settings reveals that the classification performance loss due to non-optimal native hyperparameters can be compensated for by weight vector tuning. This yields computational savings as the proposed tuning method reduces to tuning a scalar compared to tuning the native hyperparameter, which may involve repeated weight vector generation along with its burden of optimization, dimensionality reduction, etc., depending on the classifier. It is also found that weight vector tuning significantly improves the performance of Linear Discriminant Analysis (LDA) under high estimation noise. Proceeding from this second finding, an asymptotic study of the misclassification probability of the parameterized LDA classifier in the growth regime where the data dimensionality and sample size are comparable is conducted. Using random matrix theory, the misclassification probability is shown to converge to a quantity that is a function of the true statistics of the data. Additionally, an estimator of the misclassification probability is derived. Finally, computationally efficient tuning of the parameter using this estimator is demonstrated on real data.
Details Preserving Deep Collaborative Filtering-Based Method for Image Denoising
Jul 14, 2021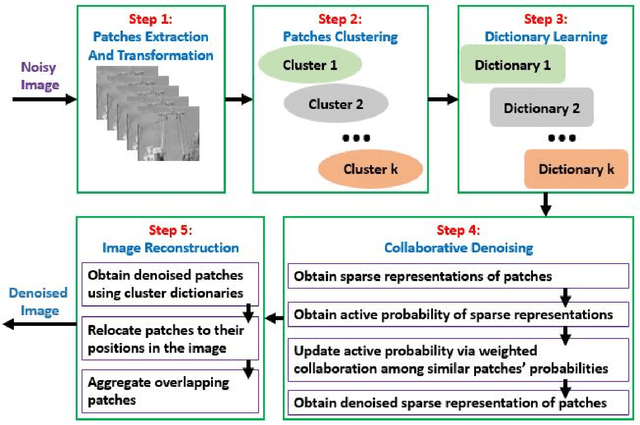
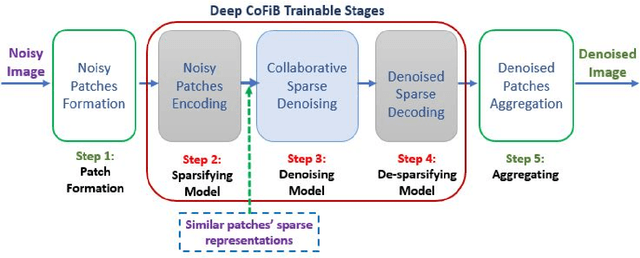

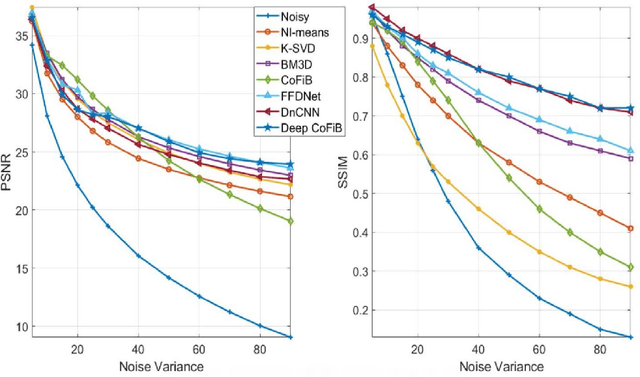
In spite of the improvements achieved by the several denoising algorithms over the years, many of them still fail at preserving the fine details of the image after denoising. This is as a result of the smooth-out effect they have on the images. Most neural network-based algorithms have achieved better quantitative performance than the classical denoising algorithms. However, they also suffer from qualitative (visual) performance as a result of the smooth-out effect. In this paper, we propose an algorithm to address this shortcoming. We propose a deep collaborative filtering-based (Deep-CoFiB) algorithm for image denoising. This algorithm performs collaborative denoising of image patches in the sparse domain using a set of optimized neural network models. This results in a fast algorithm that is able to excellently obtain a trade-off between noise removal and details preservation. Extensive experiments show that the DeepCoFiB performed quantitatively (in terms of PSNR and SSIM) and qualitatively (visually) better than many of the state-of-the-art denoising algorithms.
Collaborative Filtering-Based Method for Low-Resolution and Details Preserving Image Denoising
Jul 10, 2021


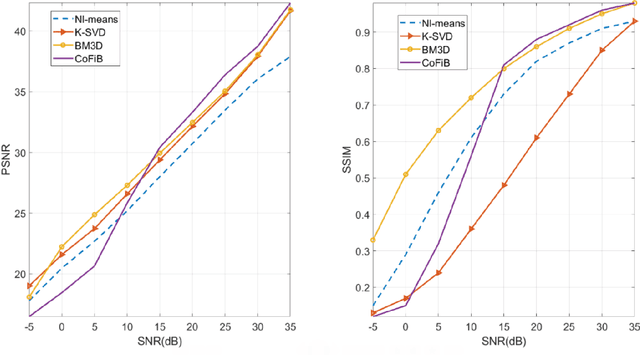
Over the years, progressive improvements in denoising performance have been achieved by several image denoising algorithms that have been proposed. Despite this, many of these state-of-the-art algorithms tend to smooth out the denoised image resulting in the loss of some image details after denoising. Many also distort images of lower resolution resulting in a partial or complete structural loss. In this paper, we address these shortcomings by proposing a collaborative filtering-based (CoFiB) denoising algorithm. Our proposed algorithm performs weighted sparse domain collaborative denoising by taking advantage of the fact that similar patches tend to have similar sparse representations in the sparse domain. This gives our algorithm the intelligence to strike a balance between image detail preservation and noise removal. Our extensive experiments showed that our proposed CoFiB algorithm does not only preserve the image details but also perform excellently for images of any given resolution where many denoising algorithms tend to struggle, specifically at low resolutions.