 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFractal and Regular Geometry of Deep Neural Networks
Apr 08, 2025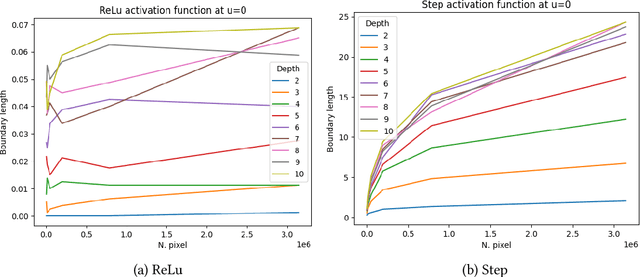
We study the geometric properties of random neural networks by investigating the boundary volumes of their excursion sets for different activation functions, as the depth increases. More specifically, we show that, for activations which are not very regular (e.g., the Heaviside step function), the boundary volumes exhibit fractal behavior, with their Hausdorff dimension monotonically increasing with the depth. On the other hand, for activations which are more regular (e.g., ReLU, logistic and $\tanh$), as the depth increases, the expected boundary volumes can either converge to zero, remain constant or diverge exponentially, depending on a single spectral parameter which can be easily computed. Our theoretical results are confirmed in some numerical experiments based on Monte Carlo simulations.
A Lipschitz spaces view of infinitely wide shallow neural networks
Oct 18, 2024
We revisit the mean field parametrization of shallow neural networks, using signed measures on unbounded parameter spaces and duality pairings that take into account the regularity and growth of activation functions. This setting directly leads to the use of unbalanced Kantorovich-Rubinstein norms defined by duality with Lipschitz functions, and of spaces of measures dual to those of continuous functions with controlled growth. These allow to make transparent the need for total variation and moment bounds or penalization to obtain existence of minimizers of variational formulations, under which we prove a compactness result in strong Kantorovich-Rubinstein norm, and in the absence of which we show several examples demonstrating undesirable behavior. Further, the Kantorovich-Rubinstein setting enables us to combine the advantages of a completely linear parametrization and ensuing reproducing kernel Banach space framework with optimal transport insights. We showcase this synergy with representer theorems and uniform large data limits for empirical risk minimization, and in proposed formulations for distillation and fusion applications.
Spectral complexity of deep neural networks
May 15, 2024



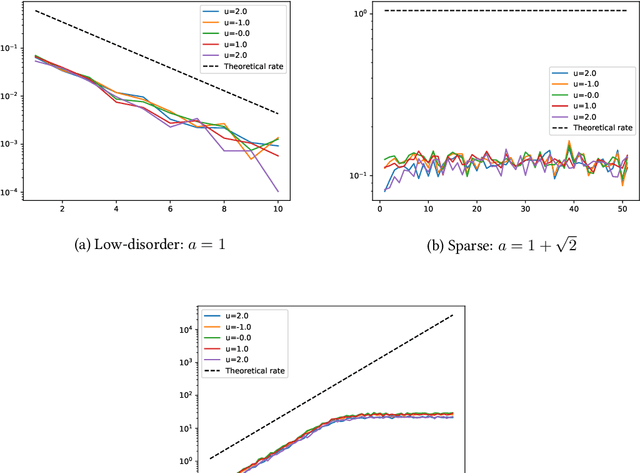
It is well-known that randomly initialized, push-forward, fully-connected neural networks weakly converge to isotropic Gaussian processes, in the limit where the width of all layers goes to infinity. In this paper, we propose to use the angular power spectrum of the limiting field to characterize the complexity of the network architecture. In particular, we define sequences of random variables associated with the angular power spectrum, and provide a full characterization of the network complexity in terms of the asymptotic distribution of these sequences as the depth diverges. On this basis, we classify neural networks as low-disorder, sparse, or high-disorder; we show how this classification highlights a number of distinct features for standard activation functions, and in particular, sparsity properties of ReLU networks. Our theoretical results are also validated by numerical simulations.
Neural reproducing kernel Banach spaces and representer theorems for deep networks
Mar 13, 2024Studying the function spaces defined by neural networks helps to understand the corresponding learning models and their inductive bias. While in some limits neural networks correspond to function spaces that are reproducing kernel Hilbert spaces, these regimes do not capture the properties of the networks used in practice. In contrast, in this paper we show that deep neural networks define suitable reproducing kernel Banach spaces. These spaces are equipped with norms that enforce a form of sparsity, enabling them to adapt to potential latent structures within the input data and their representations. In particular, leveraging the theory of reproducing kernel Banach spaces, combined with variational results, we derive representer theorems that justify the finite architectures commonly employed in applications. Our study extends analogous results for shallow networks and can be seen as a step towards considering more practically plausible neural architectures.
A Quantitative Functional Central Limit Theorem for Shallow Neural Networks
Jul 05, 2023
We prove a Quantitative Functional Central Limit Theorem for one-hidden-layer neural networks with generic activation function. The rates of convergence that we establish depend heavily on the smoothness of the activation function, and they range from logarithmic in non-differentiable cases such as the Relu to $\sqrt{n}$ for very regular activations. Our main tools are functional versions of the Stein-Malliavin approach; in particular, we exploit heavily a quantitative functional central limit theorem which has been recently established by Bourguin and Campese (2020).
How many samples are needed to leverage smoothness?
May 25, 2023


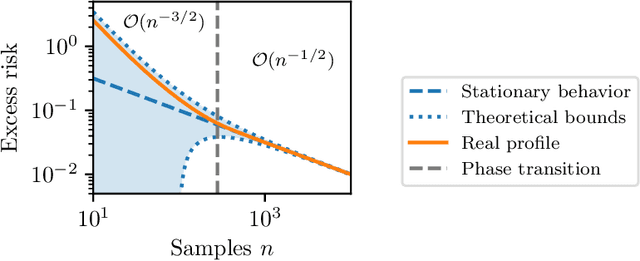
A core principle in statistical learning is that smoothness of target functions allows to break the curse of dimensionality. However, learning a smooth function through Taylor expansions requires enough samples close to one another to get meaningful estimate of high-order derivatives, which seems hard in machine learning problems where the ratio between number of data and input dimension is relatively small. Should we really hope to break the curse of dimensionality based on Taylor expansion estimation? What happens if Taylor expansions are replaced by Fourier or wavelet expansions? By deriving a new lower bound on the generalization error, this paper investigates the role of constants and transitory regimes which are usually not depicted beyond classical learning theory statements while that play a dominant role in practice.
A Case of Exponential Convergence Rates for SVM
May 20, 2022
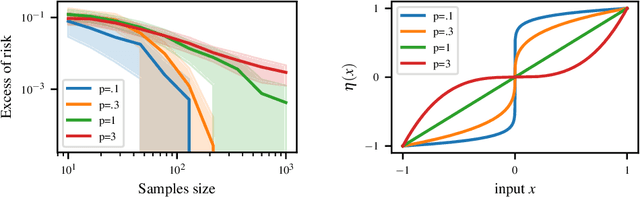
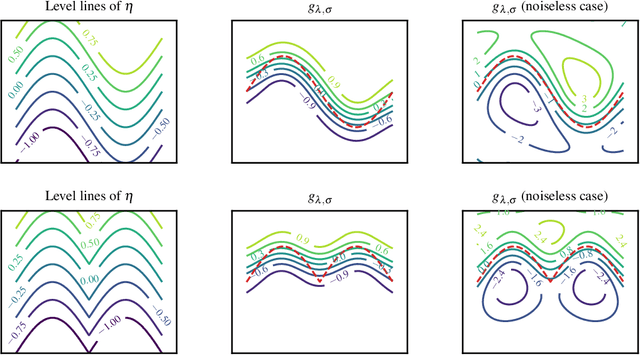
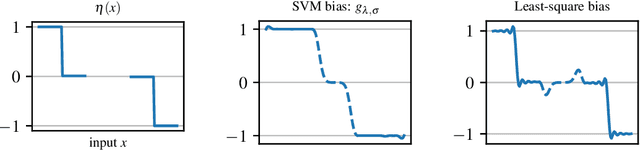
Classification is often the first problem described in introductory machine learning classes. Generalization guarantees of classification have historically been offered by Vapnik-Chervonenkis theory. Yet those guarantees are based on intractable algorithms, which has led to the theory of surrogate methods in classification. Guarantees offered by surrogate methods are based on calibration inequalities, which have been shown to be highly sub-optimal under some margin conditions, failing short to capture exponential convergence phenomena. Those "super" fast rates are becoming to be well understood for smooth surrogates, but the picture remains blurry for non-smooth losses such as the hinge loss, associated with the renowned support vector machines. In this paper, we present a simple mechanism to obtain fast convergence rates and we investigate its usage for SVM. In particular, we show that SVM can exhibit exponential convergence rates even without assuming the hard Tsybakov margin condition.
Multiclass learning with margin: exponential rates with no bias-variance trade-off
Feb 03, 2022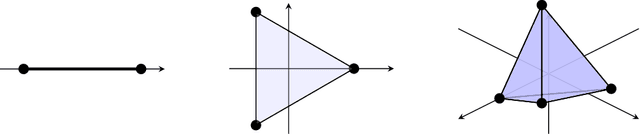

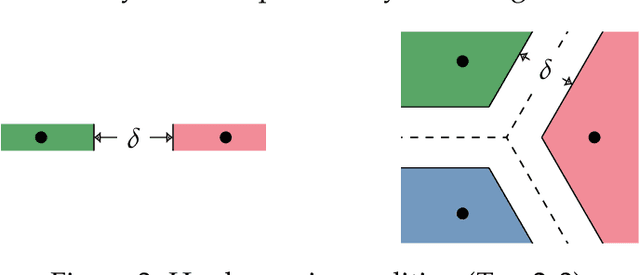
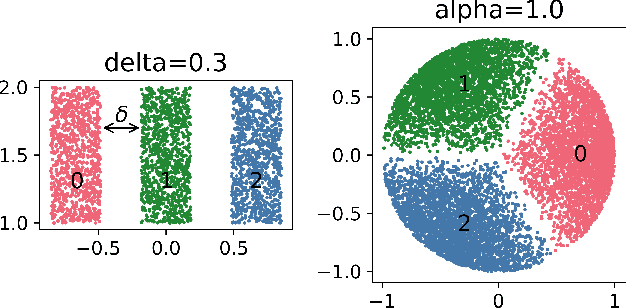
We study the behavior of error bounds for multiclass classification under suitable margin conditions. For a wide variety of methods we prove that the classification error under a hard-margin condition decreases exponentially fast without any bias-variance trade-off. Different convergence rates can be obtained in correspondence of different margin assumptions. With a self-contained and instructive analysis we are able to generalize known results from the binary to the multiclass setting.
Understanding neural networks with reproducing kernel Banach spaces
Sep 20, 2021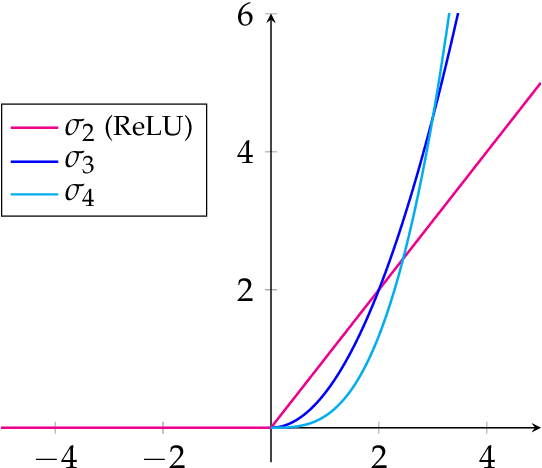

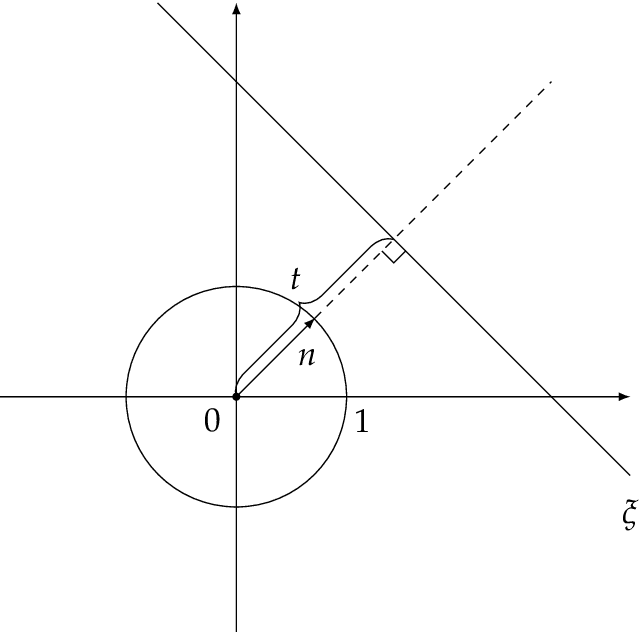

Characterizing the function spaces corresponding to neural networks can provide a way to understand their properties. In this paper we discuss how the theory of reproducing kernel Banach spaces can be used to tackle this challenge. In particular, we prove a representer theorem for a wide class of reproducing kernel Banach spaces that admit a suitable integral representation and include one hidden layer neural networks of possibly infinite width. Further, we show that, for a suitable class of ReLU activation functions, the norm in the corresponding reproducing kernel Banach space can be characterized in terms of the inverse Radon transform of a bounded real measure, with norm given by the total variation norm of the measure. Our analysis simplifies and extends recent results in [34,29,30].
ParK: Sound and Efficient Kernel Ridge Regression by Feature Space Partitions
Jun 23, 2021
We introduce ParK, a new large-scale solver for kernel ridge regression. Our approach combines partitioning with random projections and iterative optimization to reduce space and time complexity while provably maintaining the same statistical accuracy. In particular, constructing suitable partitions directly in the feature space rather than in the input space, we promote orthogonality between the local estimators, thus ensuring that key quantities such as local effective dimension and bias remain under control. We characterize the statistical-computational tradeoff of our model, and demonstrate the effectiveness of our method by numerical experiments on large-scale datasets.