 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Lipschitz spaces view of infinitely wide shallow neural networks
Oct 18, 2024
We revisit the mean field parametrization of shallow neural networks, using signed measures on unbounded parameter spaces and duality pairings that take into account the regularity and growth of activation functions. This setting directly leads to the use of unbalanced Kantorovich-Rubinstein norms defined by duality with Lipschitz functions, and of spaces of measures dual to those of continuous functions with controlled growth. These allow to make transparent the need for total variation and moment bounds or penalization to obtain existence of minimizers of variational formulations, under which we prove a compactness result in strong Kantorovich-Rubinstein norm, and in the absence of which we show several examples demonstrating undesirable behavior. Further, the Kantorovich-Rubinstein setting enables us to combine the advantages of a completely linear parametrization and ensuing reproducing kernel Banach space framework with optimal transport insights. We showcase this synergy with representer theorems and uniform large data limits for empirical risk minimization, and in proposed formulations for distillation and fusion applications.
Neural reproducing kernel Banach spaces and representer theorems for deep networks
Mar 13, 2024Studying the function spaces defined by neural networks helps to understand the corresponding learning models and their inductive bias. While in some limits neural networks correspond to function spaces that are reproducing kernel Hilbert spaces, these regimes do not capture the properties of the networks used in practice. In contrast, in this paper we show that deep neural networks define suitable reproducing kernel Banach spaces. These spaces are equipped with norms that enforce a form of sparsity, enabling them to adapt to potential latent structures within the input data and their representations. In particular, leveraging the theory of reproducing kernel Banach spaces, combined with variational results, we derive representer theorems that justify the finite architectures commonly employed in applications. Our study extends analogous results for shallow networks and can be seen as a step towards considering more practically plausible neural architectures.
Are Neural Operators Really Neural Operators? Frame Theory Meets Operator Learning
May 31, 2023



Recently, there has been significant interest in operator learning, i.e. learning mappings between infinite-dimensional function spaces. This has been particularly relevant in the context of learning partial differential equations from data. However, it has been observed that proposed models may not behave as operators when implemented on a computer, questioning the very essence of what operator learning should be. We contend that in addition to defining the operator at the continuous level, some form of continuous-discrete equivalence is necessary for an architecture to genuinely learn the underlying operator, rather than just discretizations of it. To this end, we propose to employ frames, a concept in applied harmonic analysis and signal processing that gives rise to exact and stable discrete representations of continuous signals. Extending these concepts to operators, we introduce a unifying mathematical framework of Representation equivalent Neural Operator (ReNO) to ensure operations at the continuous and discrete level are equivalent. Lack of this equivalence is quantified in terms of aliasing errors. We analyze various existing operator learning architectures to determine whether they fall within this framework, and highlight implications when they fail to do so.
Understanding neural networks with reproducing kernel Banach spaces
Sep 20, 2021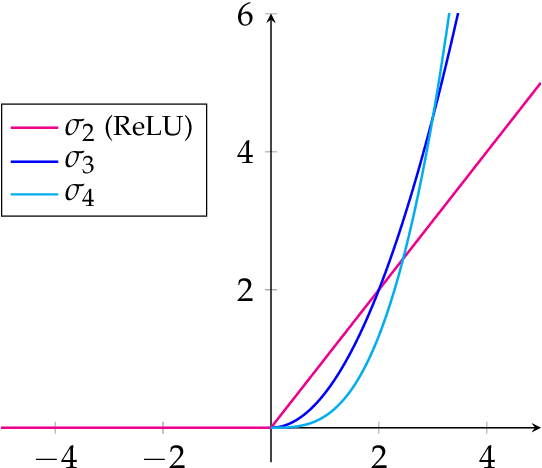

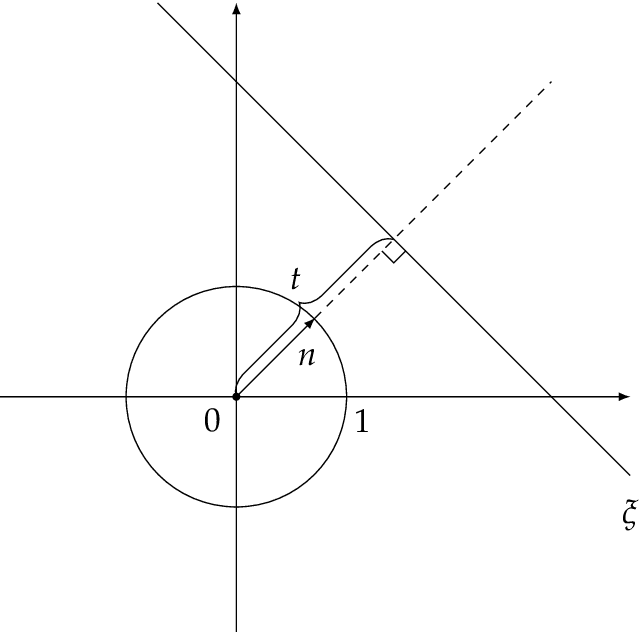

Characterizing the function spaces corresponding to neural networks can provide a way to understand their properties. In this paper we discuss how the theory of reproducing kernel Banach spaces can be used to tackle this challenge. In particular, we prove a representer theorem for a wide class of reproducing kernel Banach spaces that admit a suitable integral representation and include one hidden layer neural networks of possibly infinite width. Further, we show that, for a suitable class of ReLU activation functions, the norm in the corresponding reproducing kernel Banach space can be characterized in terms of the inverse Radon transform of a bounded real measure, with norm given by the total variation norm of the measure. Our analysis simplifies and extends recent results in [34,29,30].