 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Case of Exponential Convergence Rates for SVM
Paper and Code
May 20, 2022
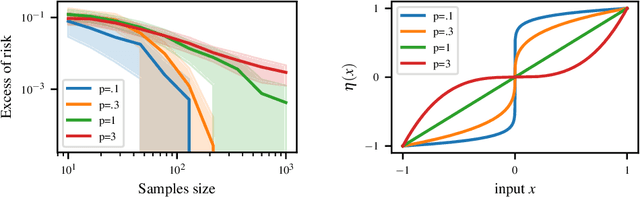
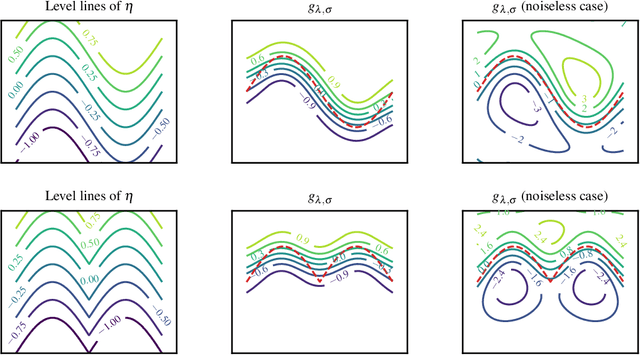
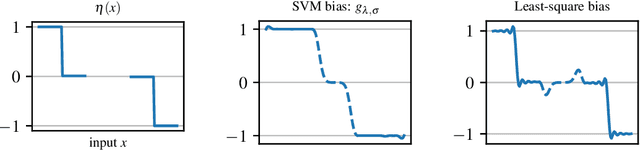
Classification is often the first problem described in introductory machine learning classes. Generalization guarantees of classification have historically been offered by Vapnik-Chervonenkis theory. Yet those guarantees are based on intractable algorithms, which has led to the theory of surrogate methods in classification. Guarantees offered by surrogate methods are based on calibration inequalities, which have been shown to be highly sub-optimal under some margin conditions, failing short to capture exponential convergence phenomena. Those "super" fast rates are becoming to be well understood for smooth surrogates, but the picture remains blurry for non-smooth losses such as the hinge loss, associated with the renowned support vector machines. In this paper, we present a simple mechanism to obtain fast convergence rates and we investigate its usage for SVM. In particular, we show that SVM can exhibit exponential convergence rates even without assuming the hard Tsybakov margin condition.