 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-Optimal Correlation Clustering with Privacy
Mar 02, 2022Correlation clustering is a central problem in unsupervised learning, with applications spanning community detection, duplicate detection, automated labelling and many more. In the correlation clustering problem one receives as input a set of nodes and for each node a list of co-clustering preferences, and the goal is to output a clustering that minimizes the disagreement with the specified nodes' preferences. In this paper, we introduce a simple and computationally efficient algorithm for the correlation clustering problem with provable privacy guarantees. Our approximation guarantees are stronger than those shown in prior work and are optimal up to logarithmic factors.
Correlation Clustering in Constant Many Parallel Rounds
Jun 15, 2021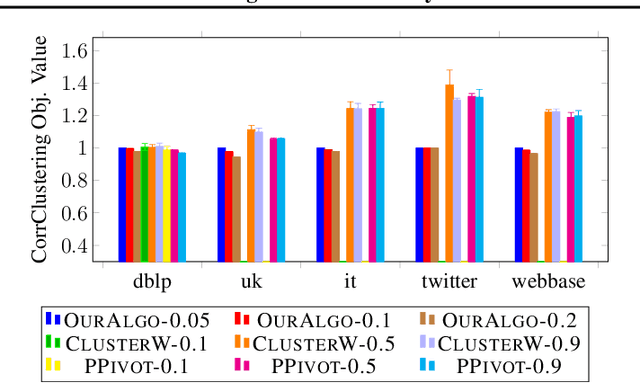
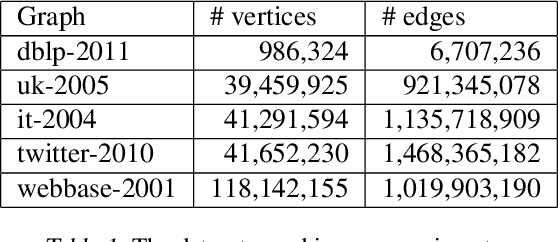
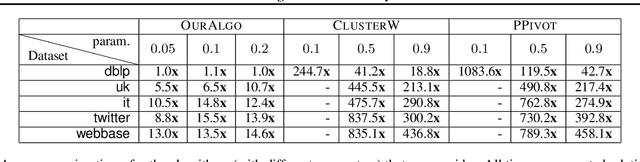
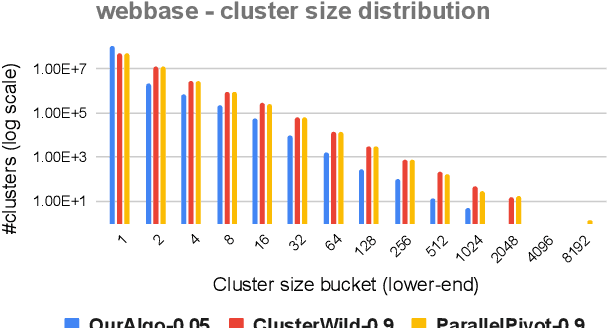
Correlation clustering is a central topic in unsupervised learning, with many applications in ML and data mining. In correlation clustering, one receives as input a signed graph and the goal is to partition it to minimize the number of disagreements. In this work we propose a massively parallel computation (MPC) algorithm for this problem that is considerably faster than prior work. In particular, our algorithm uses machines with memory sublinear in the number of nodes in the graph and returns a constant approximation while running only for a constant number of rounds. To the best of our knowledge, our algorithm is the first that can provably approximate a clustering problem on graphs using only a constant number of MPC rounds in the sublinear memory regime. We complement our analysis with an experimental analysis of our techniques.
Fairness in Streaming Submodular Maximization: Algorithms and Hardness
Oct 18, 2020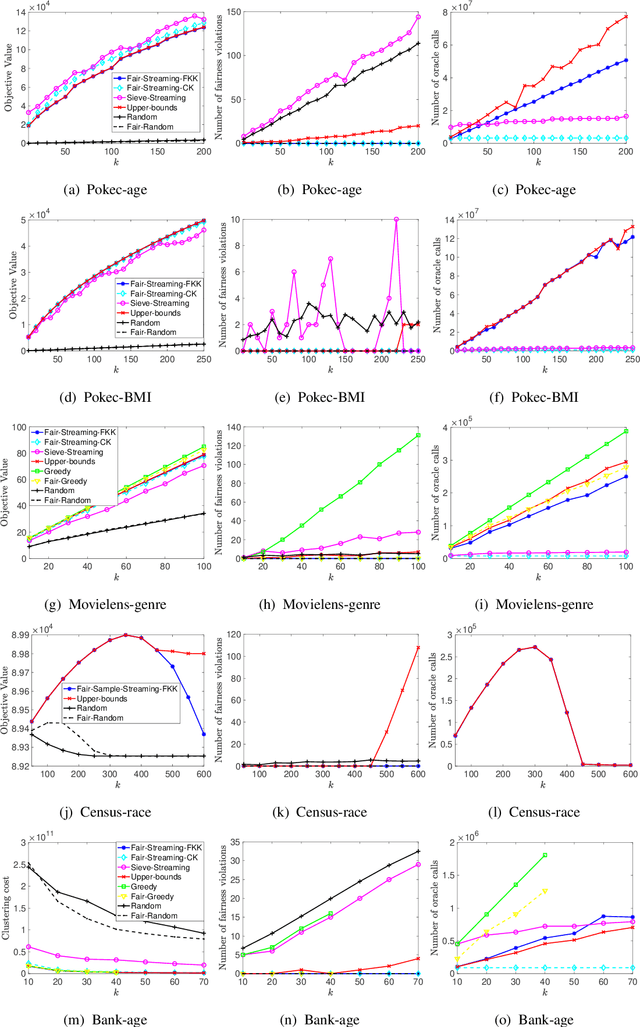
Submodular maximization has become established as the method of choice for the task of selecting representative and diverse summaries of data. However, if datapoints have sensitive attributes such as gender or age, such machine learning algorithms, left unchecked, are known to exhibit bias: under- or over-representation of particular groups. This has made the design of fair machine learning algorithms increasingly important. In this work we address the question: Is it possible to create fair summaries for massive datasets? To this end, we develop the first streaming approximation algorithms for submodular maximization under fairness constraints, for both monotone and non-monotone functions. We validate our findings empirically on exemplar-based clustering, movie recommendation, DPP-based summarization, and maximum coverage in social networks, showing that fairness constraints do not significantly impact utility.
Online Page Migration with ML Advice
Jun 09, 2020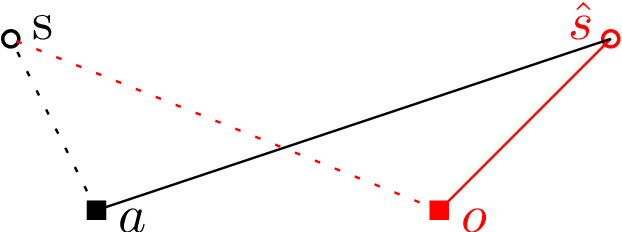
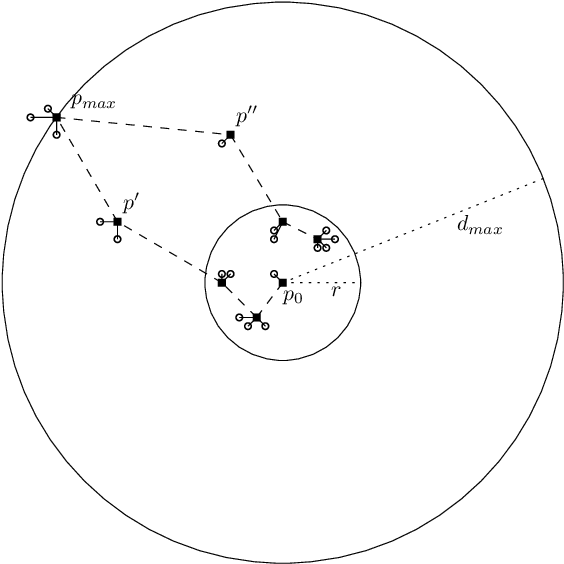
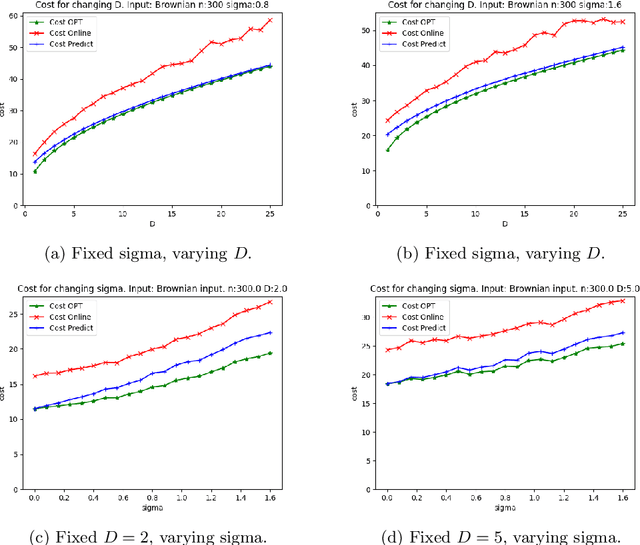
We consider online algorithms for the {\em page migration problem} that use predictions, potentially imperfect, to improve their performance. The best known online algorithms for this problem, due to Westbrook'94 and Bienkowski et al'17, have competitive ratios strictly bounded away from 1. In contrast, we show that if the algorithm is given a prediction of the input sequence, then it can achieve a competitive ratio that tends to $1$ as the prediction error rate tends to $0$. Specifically, the competitive ratio is equal to $1+O(q)$, where $q$ is the prediction error rate. We also design a ``fallback option'' that ensures that the competitive ratio of the algorithm for {\em any} input sequence is at most $O(1/q)$. Our result adds to the recent body of work that uses machine learning to improve the performance of ``classic'' algorithms.
Adversarially Robust Submodular Maximization under Knapsack Constraints
May 07, 2019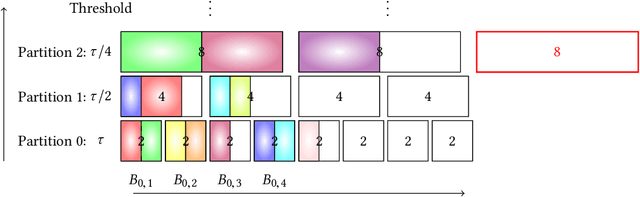

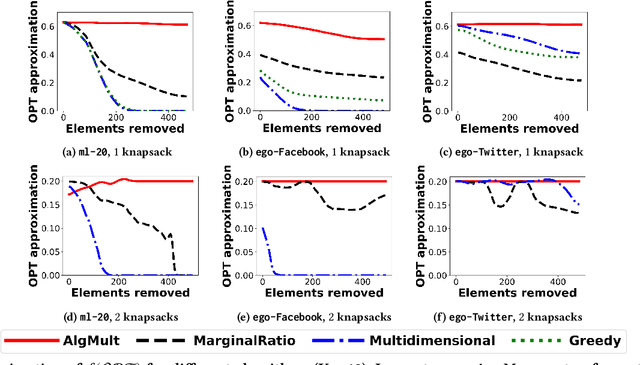
We propose the first adversarially robust algorithm for monotone submodular maximization under single and multiple knapsack constraints with scalable implementations in distributed and streaming settings. For a single knapsack constraint, our algorithm outputs a robust summary of almost optimal (up to polylogarithmic factors) size, from which a constant-factor approximation to the optimal solution can be constructed. For multiple knapsack constraints, our approximation is within a constant-factor of the best known non-robust solution. We evaluate the performance of our algorithms by comparison to natural robustifications of existing non-robust algorithms under two objectives: 1) dominating set for large social network graphs from Facebook and Twitter collected by the Stanford Network Analysis Project (SNAP), 2) movie recommendations on a dataset from MovieLens. Experimental results show that our algorithms give the best objective for a majority of the inputs and show strong performance even compared to offline algorithms that are given the set of removals in advance.
Beyond $1/2$-Approximation for Submodular Maximization on Massive Data Streams
Aug 06, 2018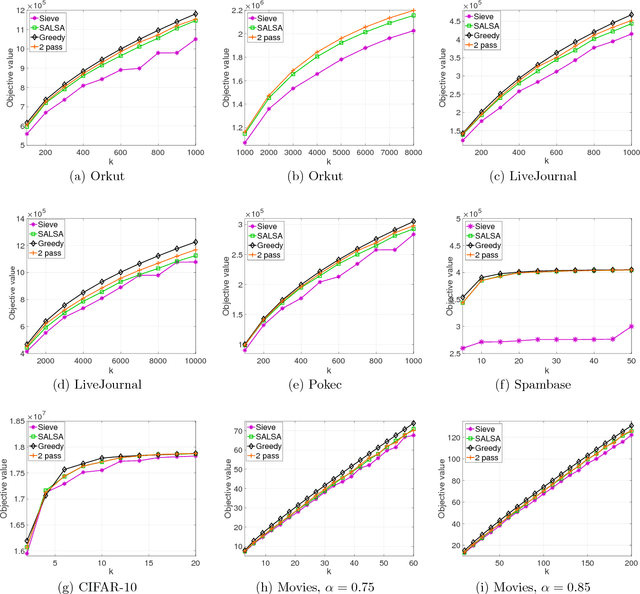
Many tasks in machine learning and data mining, such as data diversification, non-parametric learning, kernel machines, clustering etc., require extracting a small but representative summary from a massive dataset. Often, such problems can be posed as maximizing a submodular set function subject to a cardinality constraint. We consider this question in the streaming setting, where elements arrive over time at a fast pace and thus we need to design an efficient, low-memory algorithm. One such method, proposed by Badanidiyuru et al. (2014), always finds a $0.5$-approximate solution. Can this approximation factor be improved? We answer this question affirmatively by designing a new algorithm SALSA for streaming submodular maximization. It is the first low-memory, single-pass algorithm that improves the factor $0.5$, under the natural assumption that elements arrive in a random order. We also show that this assumption is necessary, i.e., that there is no such algorithm with better than $0.5$-approximation when elements arrive in arbitrary order. Our experiments demonstrate that SALSA significantly outperforms the state of the art in applications related to exemplar-based clustering, social graph analysis, and recommender systems.
Streaming Robust Submodular Maximization: A Partitioned Thresholding Approach
Nov 07, 2017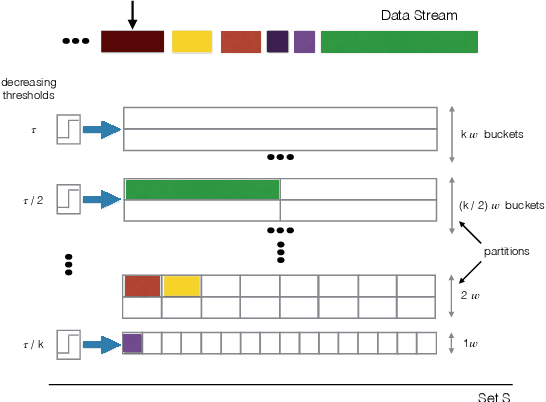
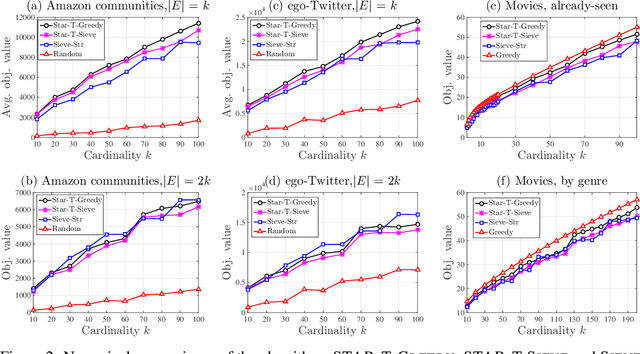
We study the classical problem of maximizing a monotone submodular function subject to a cardinality constraint k, with two additional twists: (i) elements arrive in a streaming fashion, and (ii) m items from the algorithm's memory are removed after the stream is finished. We develop a robust submodular algorithm STAR-T. It is based on a novel partitioning structure and an exponentially decreasing thresholding rule. STAR-T makes one pass over the data and retains a short but robust summary. We show that after the removal of any m elements from the obtained summary, a simple greedy algorithm STAR-T-GREEDY that runs on the remaining elements achieves a constant-factor approximation guarantee. In two different data summarization tasks, we demonstrate that it matches or outperforms existing greedy and streaming methods, even if they are allowed the benefit of knowing the removed subset in advance.
* To appear in NIPS 2017
Robust Submodular Maximization: A Non-Uniform Partitioning Approach
Jun 15, 2017
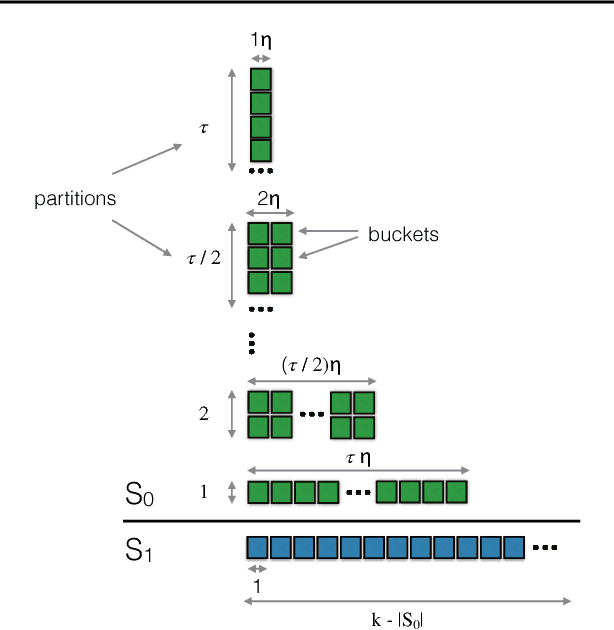

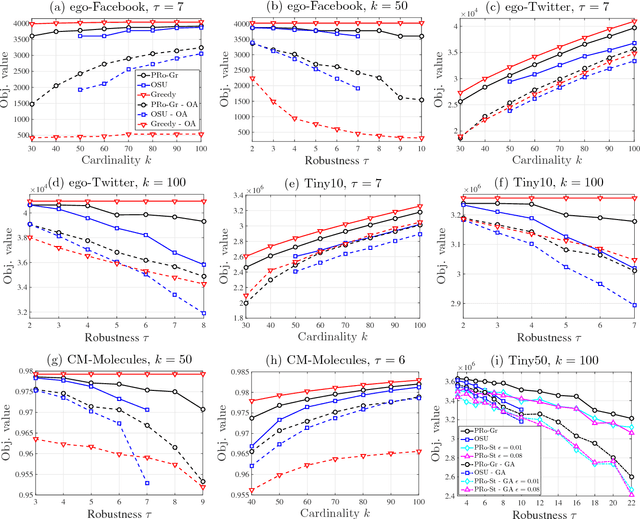
We study the problem of maximizing a monotone submodular function subject to a cardinality constraint $k$, with the added twist that a number of items $\tau$ from the returned set may be removed. We focus on the worst-case setting considered in (Orlin et al., 2016), in which a constant-factor approximation guarantee was given for $\tau = o(\sqrt{k})$. In this paper, we solve a key open problem raised therein, presenting a new Partitioned Robust (PRo) submodular maximization algorithm that achieves the same guarantee for more general $\tau = o(k)$. Our algorithm constructs partitions consisting of buckets with exponentially increasing sizes, and applies standard submodular optimization subroutines on the buckets in order to construct the robust solution. We numerically demonstrate the performance of PRo in data summarization and influence maximization, demonstrating gains over both the greedy algorithm and the algorithm of (Orlin et al., 2016).