 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Correlation Clustering in Sublinear Update Time
Jun 13, 2024We study the classic problem of correlation clustering in dynamic node streams. In this setting, nodes are either added or randomly deleted over time, and each node pair is connected by a positive or negative edge. The objective is to continuously find a partition which minimizes the sum of positive edges crossing clusters and negative edges within clusters. We present an algorithm that maintains an $O(1)$-approximation with $O$(polylog $n$) amortized update time. Prior to our work, Behnezhad, Charikar, Ma, and L. Tan achieved a $5$-approximation with $O(1)$ expected update time in edge streams which translates in node streams to an $O(D)$-update time where $D$ is the maximum possible degree. Finally we complement our theoretical analysis with experiments on real world data.
Multi-Swap $k$-Means++
Sep 28, 2023



The $k$-means++ algorithm of Arthur and Vassilvitskii (SODA 2007) is often the practitioners' choice algorithm for optimizing the popular $k$-means clustering objective and is known to give an $O(\log k)$-approximation in expectation. To obtain higher quality solutions, Lattanzi and Sohler (ICML 2019) proposed augmenting $k$-means++ with $O(k \log \log k)$ local search steps obtained through the $k$-means++ sampling distribution to yield a $c$-approximation to the $k$-means clustering problem, where $c$ is a large absolute constant. Here we generalize and extend their local search algorithm by considering larger and more sophisticated local search neighborhoods hence allowing to swap multiple centers at the same time. Our algorithm achieves a $9 + \varepsilon$ approximation ratio, which is the best possible for local search. Importantly we show that our approach yields substantial practical improvements, we show significant quality improvements over the approach of Lattanzi and Sohler (ICML 2019) on several datasets.
A Metaheuristic Algorithm for Large Maximum Weight Independent Set Problems
Mar 28, 2022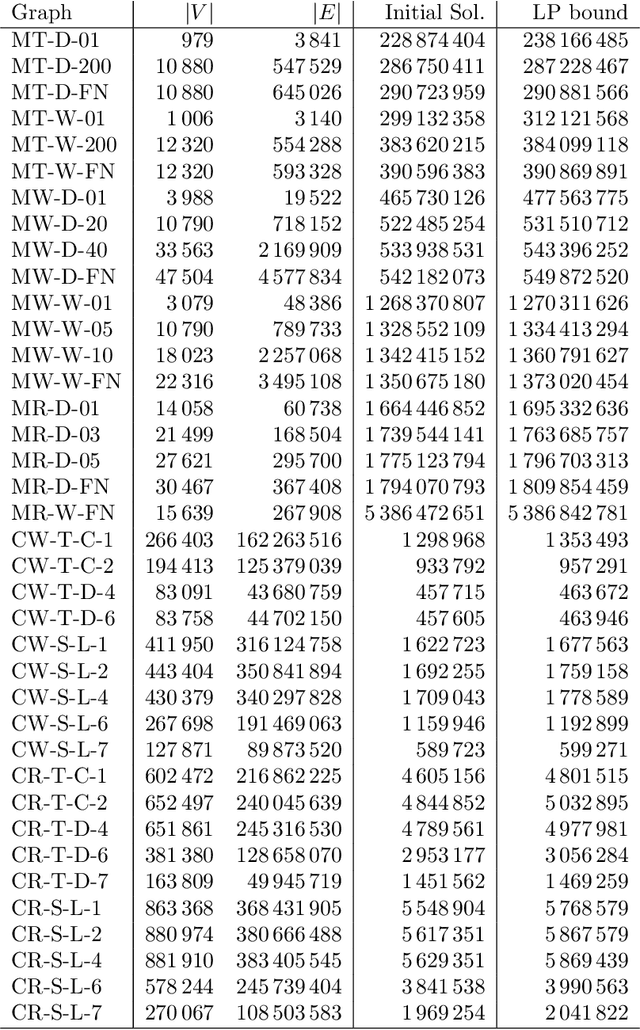
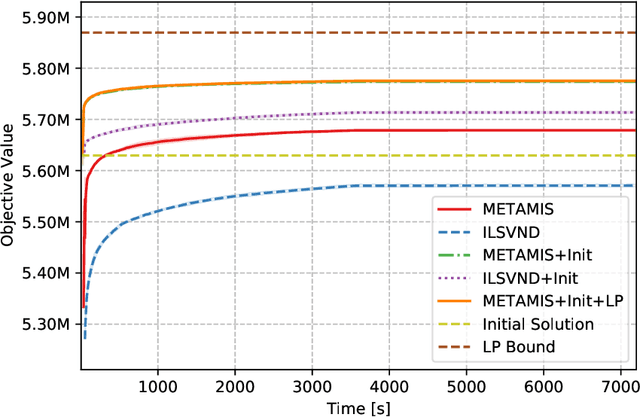
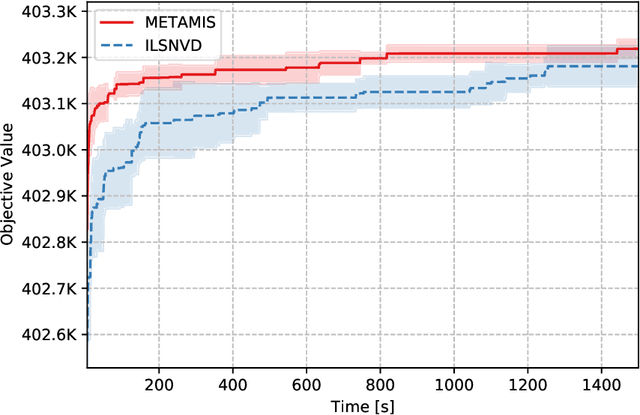
Motivated by a real-world vehicle routing application, we consider the maximum-weight independent set problem: Given a node-weighted graph, find a set of independent (mutually nonadjacent) nodes whose node-weight sum is maximum. Some of the graphs airsing in this application are large, having hundreds of thousands of nodes and hundreds of millions of edges. To solve instances of this size, we develop a new local search algorithm, which is a metaheuristic in the greedy randomized adaptive search (GRASP) framework. This algorithm, which we call METAMIS, uses a wider range of simple local search operations than previously described in the literature. We introduce data structures that make these operations efficient. A new variant of path-relinking is introduced to escape local optima and so is a new alternating augmenting-path local search move that improves algorithm performance. We compare an implementation of our algorithm with a state-of-the-art openly available code on public benchmark sets, including some large instances with hundreds of millions of vertices. Our algorithm is, in general, competitive and outperforms this openly available code on large vehicle routing instances. We hope that our results will lead to even better MWIS algorithms.
Near-Optimal Correlation Clustering with Privacy
Mar 02, 2022Correlation clustering is a central problem in unsupervised learning, with applications spanning community detection, duplicate detection, automated labelling and many more. In the correlation clustering problem one receives as input a set of nodes and for each node a list of co-clustering preferences, and the goal is to output a clustering that minimizes the disagreement with the specified nodes' preferences. In this paper, we introduce a simple and computationally efficient algorithm for the correlation clustering problem with provable privacy guarantees. Our approximation guarantees are stronger than those shown in prior work and are optimal up to logarithmic factors.
Correlation Clustering in Constant Many Parallel Rounds
Jun 15, 2021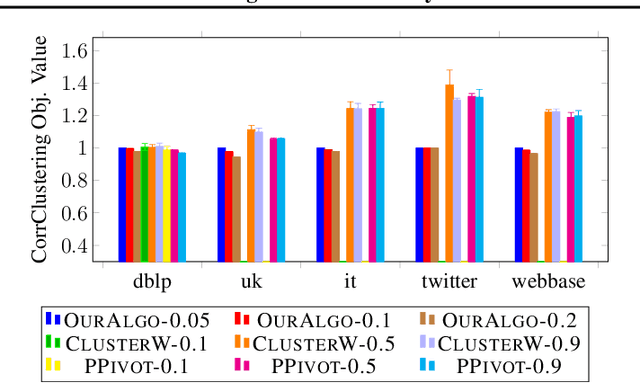
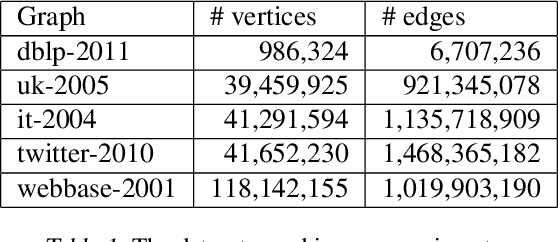
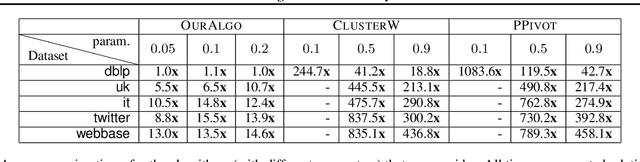
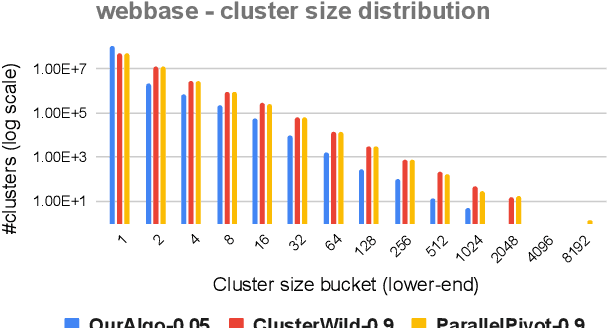
Correlation clustering is a central topic in unsupervised learning, with many applications in ML and data mining. In correlation clustering, one receives as input a signed graph and the goal is to partition it to minimize the number of disagreements. In this work we propose a massively parallel computation (MPC) algorithm for this problem that is considerably faster than prior work. In particular, our algorithm uses machines with memory sublinear in the number of nodes in the graph and returns a constant approximation while running only for a constant number of rounds. To the best of our knowledge, our algorithm is the first that can provably approximate a clustering problem on graphs using only a constant number of MPC rounds in the sublinear memory regime. We complement our analysis with an experimental analysis of our techniques.
Online Reciprocal Recommendation with Theoretical Performance Guarantees
Jun 04, 2018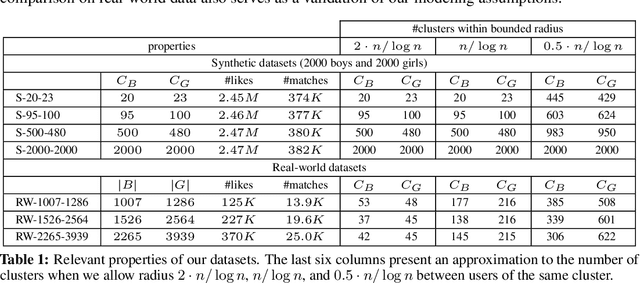
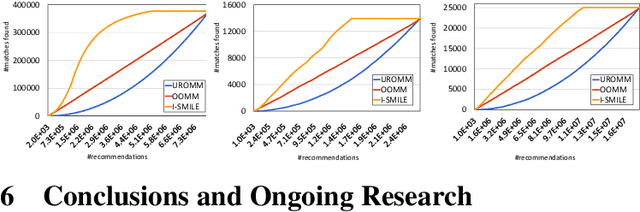
A reciprocal recommendation problem is one where the goal of learning is not just to predict a user's preference towards a passive item (e.g., a book), but to recommend the targeted user on one side another user from the other side such that a mutual interest between the two exists. The problem thus is sharply different from the more traditional items-to-users recommendation, since a good match requires meeting the preferences of both users. We initiate a rigorous theoretical investigation of the reciprocal recommendation task in a specific framework of sequential learning. We point out general limitations, formulate reasonable assumptions enabling effective learning and, under these assumptions, we design and analyze a computationally efficient algorithm that uncovers mutual likes at a pace comparable to those achieved by a clearvoyant algorithm knowing all user preferences in advance. Finally, we validate our algorithm against synthetic and real-world datasets, showing improved empirical performance over simple baselines.