 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJacta: A Versatile Planner for Learning Dexterous and Whole-body Manipulation
Aug 02, 2024



Robotic manipulation is challenging due to discontinuous dynamics, as well as high-dimensional state and action spaces. Data-driven approaches that succeed in manipulation tasks require large amounts of data and expert demonstrations, typically from humans. Existing manipulation planners are restricted to specific systems and often depend on specialized algorithms for using demonstration. Therefore, we introduce a flexible motion planner tailored to dexterous and whole-body manipulation tasks. Our planner creates readily usable demonstrations for reinforcement learning algorithms, eliminating the need for additional training pipeline complexities. With this approach, we can efficiently learn policies for complex manipulation tasks, where traditional reinforcement learning alone only makes little progress. Furthermore, we demonstrate that learned policies are transferable to real robotic systems for solving complex dexterous manipulation tasks.
Single-Level Differentiable Contact Simulation
Dec 13, 2022



We present a differentiable formulation of rigid-body contact dynamics for objects and robots represented as compositions of convex primitives. Existing optimization-based approaches simulating contact between convex primitives rely on a bilevel formulation that separates collision detection and contact simulation. These approaches are unreliable in realistic contact simulation scenarios because isolating the collision detection problem introduces contact location non-uniqueness. Our approach combines contact simulation and collision detection into a unified single-level optimization problem. This disambiguates the collision detection problem in a physics-informed manner. Compared to previous differentiable simulation approaches, our formulation features improved simulation robustness and a reduction in computational complexity by more than an order of magnitude. We illustrate the contact and collision differentiability on a robotic manipulation task requiring optimization-through-contact. We provide a numerically efficient implementation of our formulation in the Julia language called Silico.jl.
Differentiable Physics Simulation of Dynamics-Augmented Neural Objects
Oct 20, 2022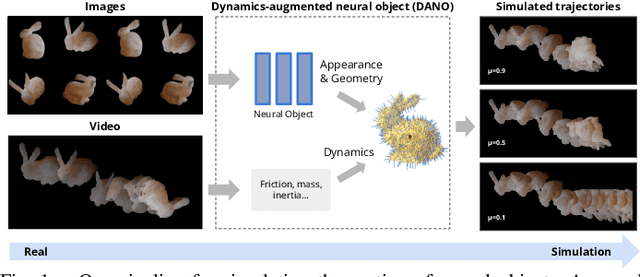

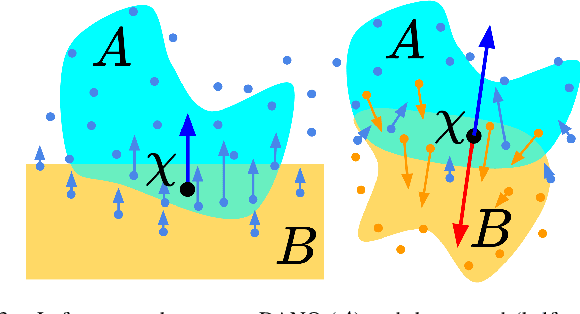
We present a differentiable pipeline for simulating the motion of objects that represent their geometry as a continuous density field parameterized as a deep network. This includes Neural Radiance Fields (NeRFs), and other related models. From the density field, we estimate the dynamical properties of the object, including its mass, center of mass, and inertia matrix. We then introduce a differentiable contact model based on the density field for computing normal and friction forces resulting from collisions. This allows a robot to autonomously build object models that are visually and dynamically accurate from still images and videos of objects in motion. The resulting Dynamics-Augmented Neural Objects (DANOs) are simulated with an existing differentiable simulation engine, Dojo, interacting with other standard simulation objects, such as spheres, planes, and robots specified as URDFs. A robot can use this simulation to optimize grasps and manipulation trajectories of neural objects, or to improve the neural object models through gradient-based real-to-simulation transfer. We demonstrate the pipeline to learn the coefficient of friction of a bar of soap from a real video of the soap sliding on a table. We also learn the coefficient of friction and mass of a Stanford bunny through interactions with a Panda robot arm from synthetic data, and we optimize trajectories in simulation for the Panda arm to push the bunny to a goal location.
CALIPSO: A Differentiable Solver for Trajectory Optimization with Conic and Complementarity Constraints
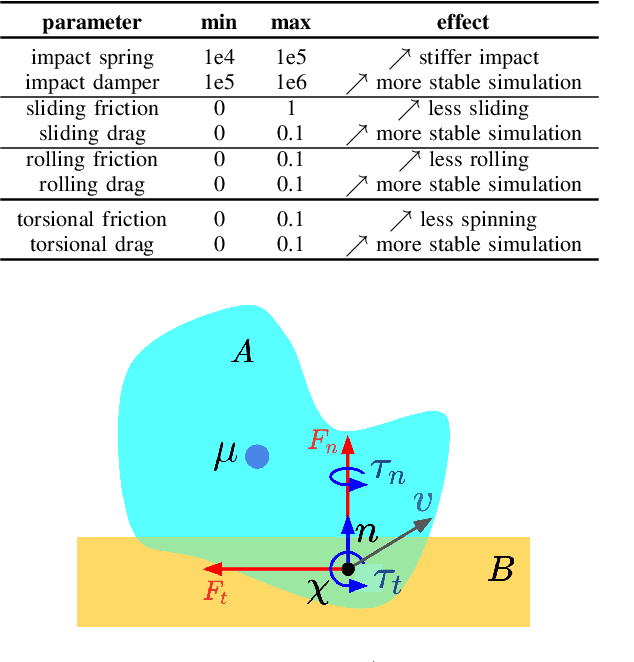
May 19, 2022
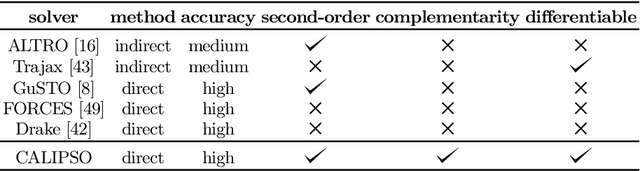
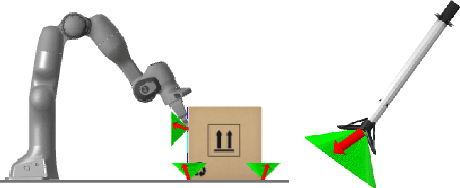
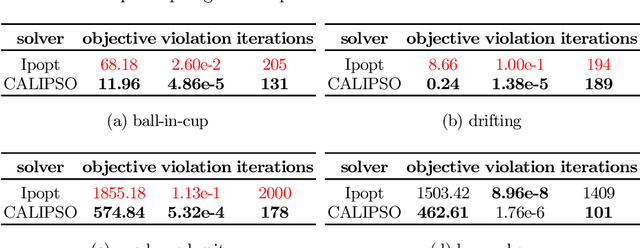
We present a new solver for non-convex trajectory optimization problems that is specialized for robotics applications. CALIPSO, or the Conic Augmented Lagrangian Interior-Point SOlver, combines several strategies for constrained numerical optimization to natively handle second-order cones and complementarity constraints. It reliably solves challenging motion-planning problems that include contact-implicit formulations of impacts and Coulomb friction, thrust limits subject to conic constraints, and state-triggered constraints where general-purpose nonlinear programming solvers like SNOPT and Ipopt fail to converge. Additionally, CALIPSO supports efficient differentiation of solutions with respect to problem data, enabling bi-level optimization applications like auto-tuning of feedback policies. Reliable convergence of the solver is demonstrated on a range of problems from manipulation, locomotion, and aerospace domains. An open-source implementation of this solver is available.
Dojo: A Differentiable Simulator for Robotics
Mar 03, 2022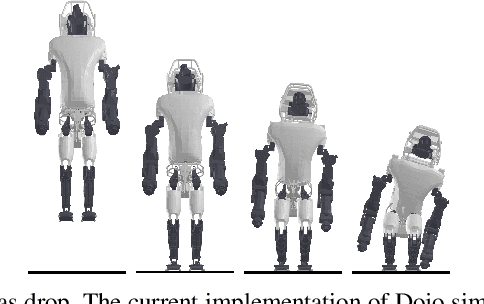
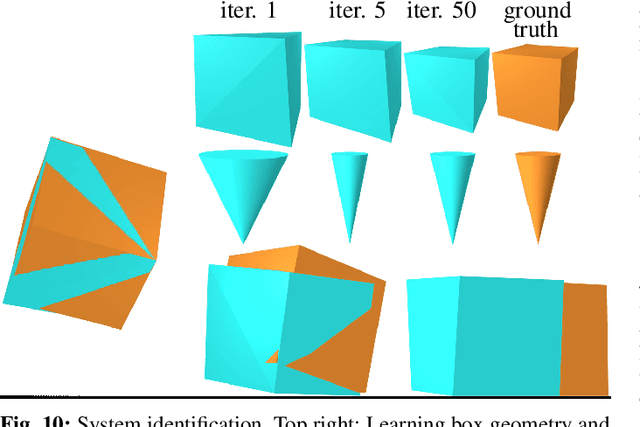
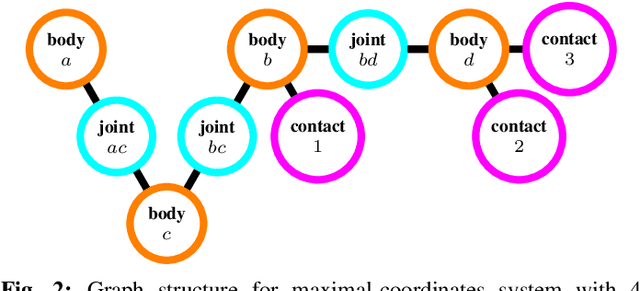

We present a differentiable rigid-body-dynamics simulator for robotics that prioritizes physical accuracy and differentiability: Dojo. The simulator utilizes an expressive maximal-coordinates representation, achieves stable simulation at low sample rates, and conserves energy and momentum by employing a variational integrator. A nonlinear complementarity problem, with nonlinear friction cones, models hard contact and is reliably solved using a custom primal-dual interior-point method. The implicit-function theorem enables efficient differentiation of an intermediate relaxed problem and computes smooth gradients from the contact model. We demonstrate the usefulness of the simulator and its gradients through a number of examples including: simulation, trajectory optimization, reinforcement learning, and system identification.
Trajectory Optimization with Optimization-Based Dynamics
Sep 10, 2021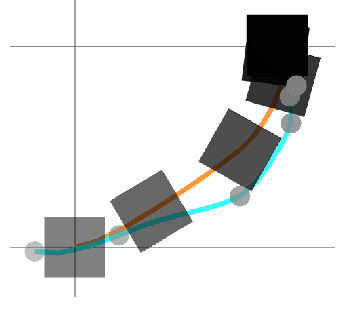
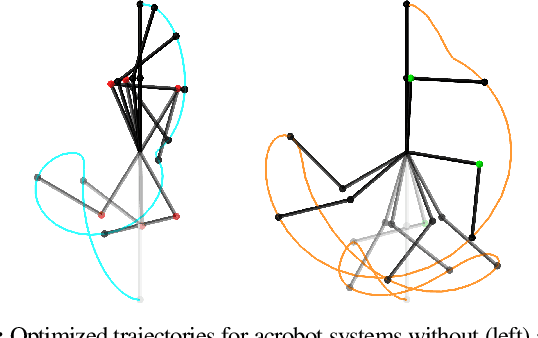
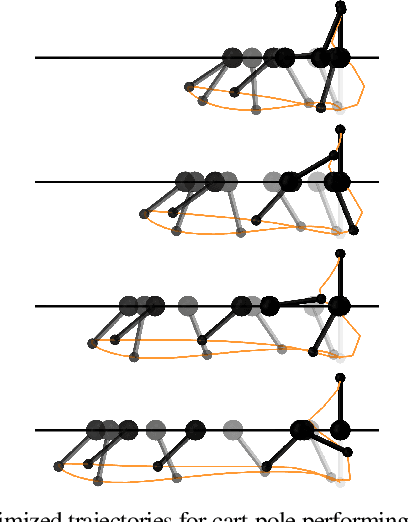
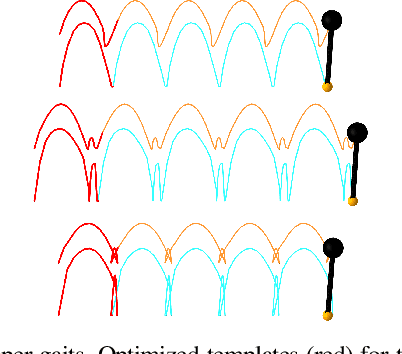
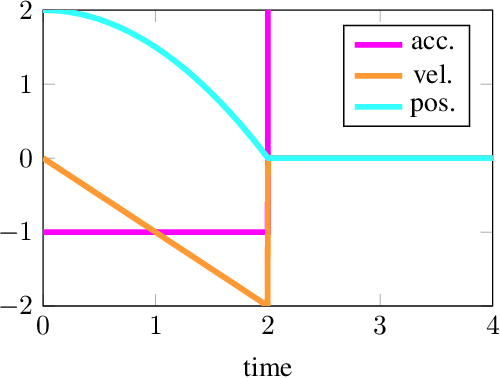
We present a framework for bi-level trajectory optimization in which a system's dynamics are encoded as the solution to a constrained optimization problem and smooth gradients of this lower-level problem are passed to an upper-level trajectory optimizer. This optimization-based dynamics representation enables constraint handling, additional variables, and non-smooth forces to be abstracted away from the upper-level optimizer, and allows classical unconstrained optimizers to synthesize trajectories for more complex systems. We provide a path-following method for efficient evaluation of constrained dynamics and utilize the implicit-function theorem to compute smooth gradients of this representation. We demonstrate the framework by modeling systems from locomotion, aerospace, and manipulation domains including: acrobot with joint limits, cart-pole subject to Coulomb friction, Raibert hopper, rocket landing with thrust limits, and planar-push task with optimization-based dynamics and then optimize trajectories using iterative LQR.
Linear Contact-Implicit Model-Predictive Control
Jul 12, 2021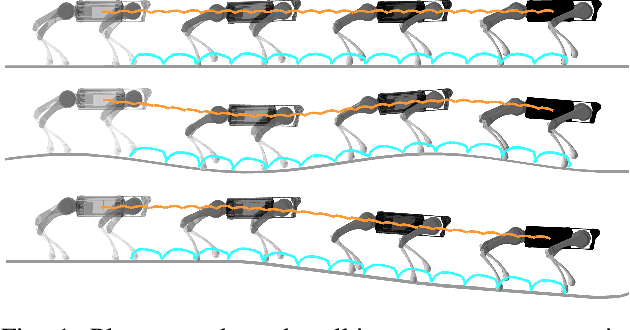

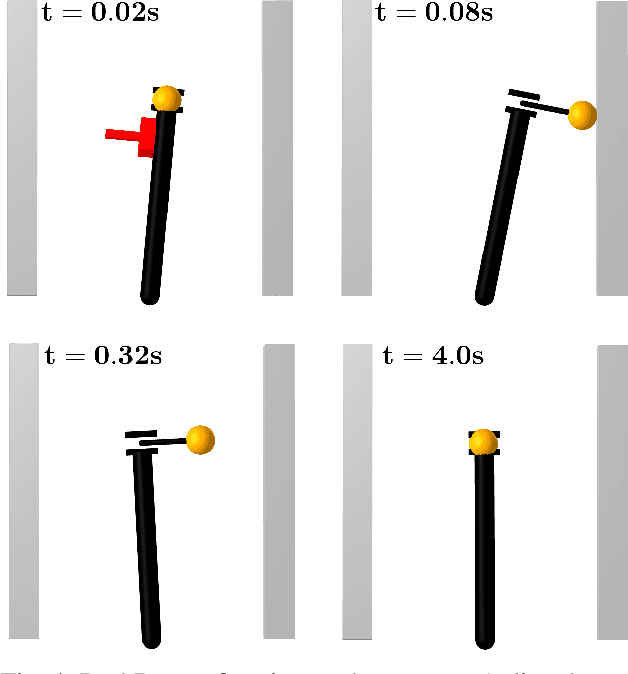
We present a general approach for controlling robotic systems that make and break contact with their environments: linear contact-implicit model-predictive control (LCI-MPC). Our use of differentiable contact dynamics provides a natural extension of linear model-predictive control to contact-rich settings. The policy leverages precomputed linearizations about a reference state or trajectory while contact modes, encoded via complementarity constraints, are explicitly retained, resulting in policies that can be efficiently evaluated while maintaining robustness to changes in contact timings. In many cases, the algorithm is even capable of generating entirely new contact sequences. To enable real-time performance, we devise a custom structure-exploiting linear solver for the contact dynamics. We demonstrate that the policy can respond to disturbances by discovering and exploiting new contact modes and is robust to model mismatch and unmodeled environments for a collection of simulated robotic systems, including: pushbot, hopper, quadruped, and biped.
ALGAMES: A Fast Augmented Lagrangian Solver for Constrained Dynamic Games
Apr 17, 2021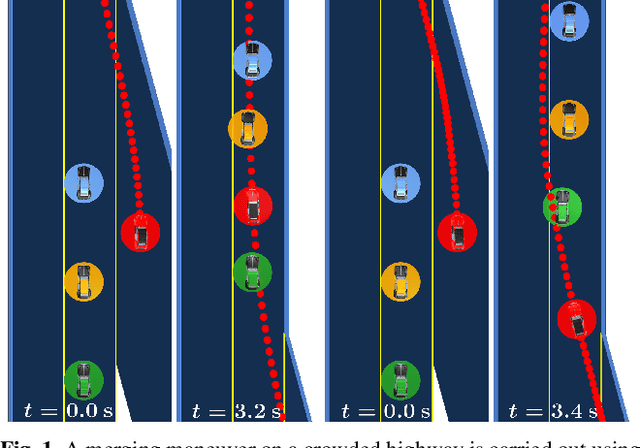
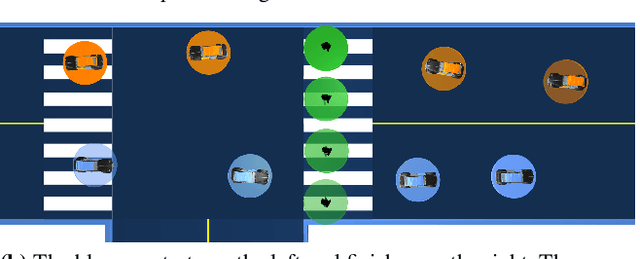

Dynamic games are an effective paradigm for dealing with the control of multiple interacting actors. This paper introduces ALGAMES (Augmented Lagrangian GAME-theoretic Solver), a solver that handles trajectory-optimization problems with multiple actors and general nonlinear state and input constraints. Its novelty resides in satisfying the first-order optimality conditions with a quasi-Newton root-finding algorithm and rigorously enforcing constraints using an augmented Lagrangian method. We evaluate our solver in the context of autonomous driving on scenarios with a strong level of interactions between the vehicles. We assess the robustness of the solver using Monte Carlo simulations. It is able to reliably solve complex problems like ramp merging with three vehicles three times faster than a state-of-the-art DDP-based approach. A model-predictive control (MPC) implementation of the algorithm, running at more than 60 Hz, demonstrates ALGAMES' ability to mitigate the "frozen robot" problem on complex autonomous driving scenarios like merging onto a crowded highway.
LUCIDGames: Online Unscented Inverse Dynamic Games for Adaptive Trajectory Prediction and Planning
Nov 16, 2020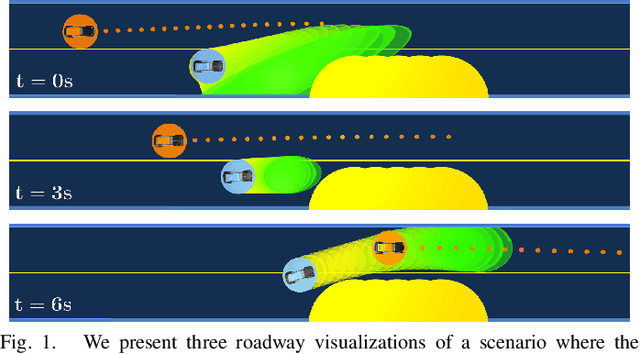
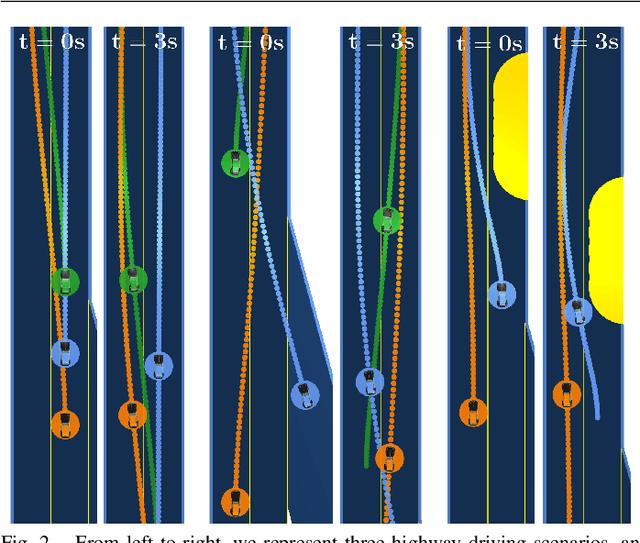
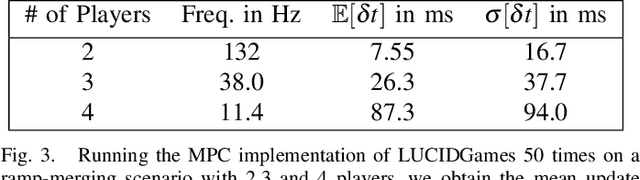
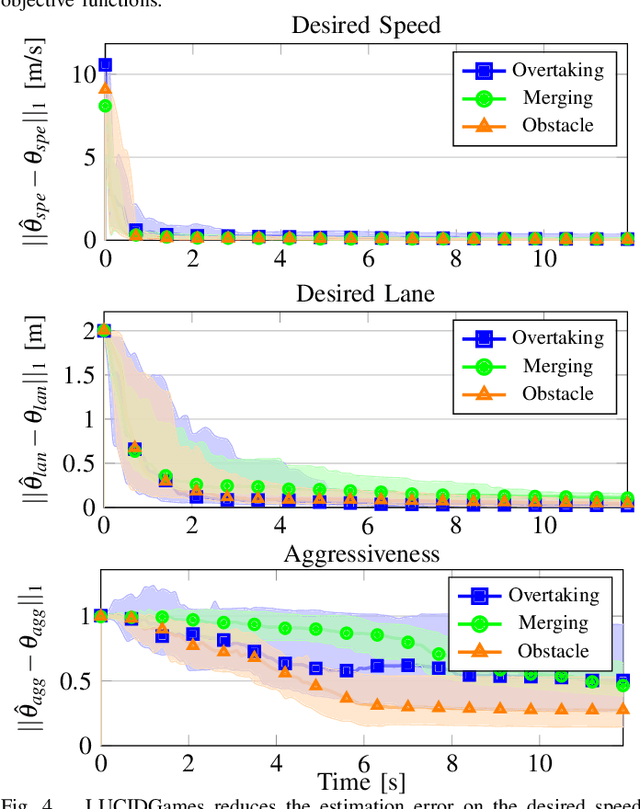
Existing game-theoretic planning methods assume that the robot knows the objective functions of the other agents a priori while, in practical scenarios, this is rarely the case. This paper introduces LUCIDGames, an inverse optimal control algorithm that is able to estimate the other agents' objective functions in real time, and incorporate those estimates online into a receding-horizon game-theoretic planner. LUCIDGames solves the inverse optimal control problem by recasting it in a recursive parameter-estimation framework. LUCIDGames uses an unscented Kalman filter (UKF) to iteratively update a Bayesian estimate of the other agents' cost function parameters, improving that estimate online as more data is gathered from the other agents' observed trajectories. The planner then takes account of the uncertainty in the Bayesian parameter estimates of other agents by planning a trajectory for the robot subject to uncertainty ellipse constraints. The algorithm assumes no explicit communication or coordination between the robot and the other agents in the environment. An MPC implementation of LUCIDGames demonstrates real-time performance on complex autonomous driving scenarios with an update frequency of 40 Hz. Empirical results demonstrate that LUCIDGames improves the robot's performance over existing game-theoretic and traditional MPC planning approaches. Our implementation of LUCIDGames is available at https://github.com/RoboticExplorationLab/LUCIDGames.jl.
Robust Entry Vehicle Guidance with Sampling-Based Invariant Funnels
Nov 04, 2020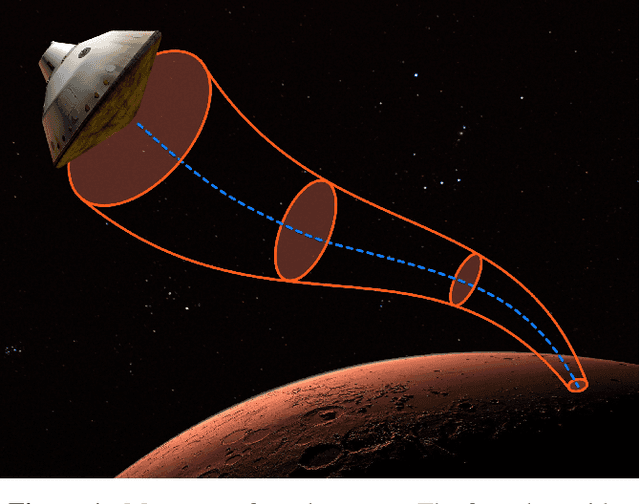
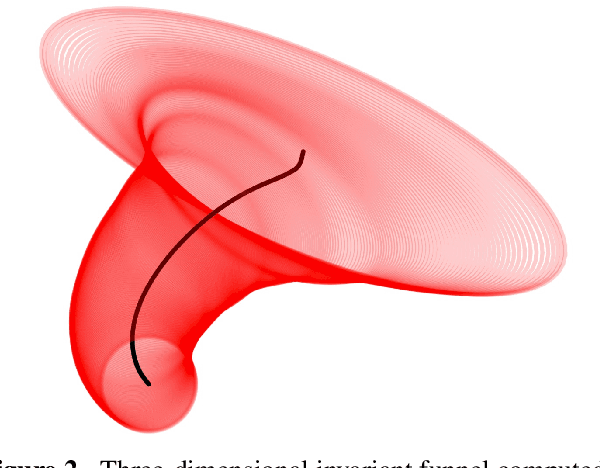
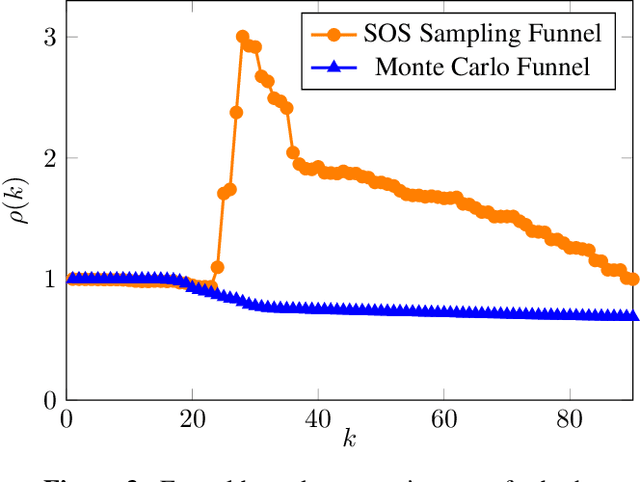
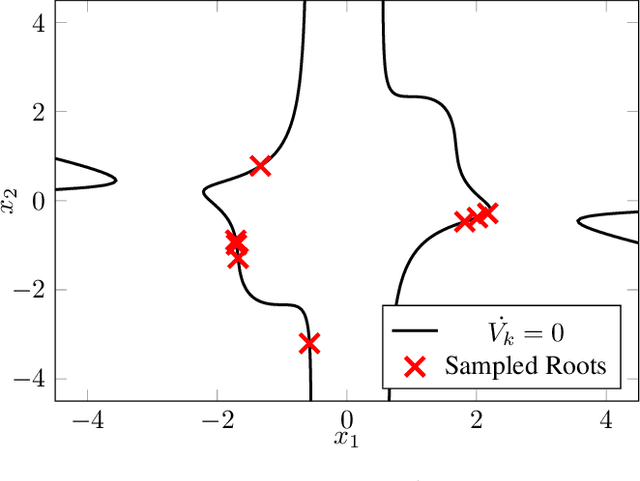
Managing uncertainty is a fundamental and critical issue in spacecraft entry guidance. This paper presents a novel approach for uncertainty propagation during entry, descent and landing that relies on a new sum-of-squares robust verification technique. Unlike risk-based and probabilistic approaches, our technique does not rely on any probabilistic assumptions. It uses a set-based description to bound uncertainties and disturbances like vehicle and atmospheric parameters and winds. The approach leverages a recently developed sampling-based version of sum-of-squares programming to compute regions of finite time invariance, commonly referred to as "invariant funnels". We apply this approach to a three-degree-of-freedom entry vehicle model and test it using a Mars Science Laboratory reference trajectory. We compute tight approximations of robust invariant funnels that are guaranteed to reach a goal region with increased landing accuracy while respecting realistic thermal constraints.