 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Whole Slide Foundation Model for Pathology
Nov 29, 2024



The field of computational pathology has been transformed with recent advances in foundation models that encode histopathology region-of-interests (ROIs) into versatile and transferable feature representations via self-supervised learning (SSL). However, translating these advancements to address complex clinical challenges at the patient and slide level remains constrained by limited clinical data in disease-specific cohorts, especially for rare clinical conditions. We propose TITAN, a multimodal whole slide foundation model pretrained using 335,645 WSIs via visual self-supervised learning and vision-language alignment with corresponding pathology reports and 423,122 synthetic captions generated from a multimodal generative AI copilot for pathology. Without any finetuning or requiring clinical labels, TITAN can extract general-purpose slide representations and generate pathology reports that generalize to resource-limited clinical scenarios such as rare disease retrieval and cancer prognosis. We evaluate TITAN on diverse clinical tasks and find that TITAN outperforms both ROI and slide foundation models across machine learning settings such as linear probing, few-shot and zero-shot classification, rare cancer retrieval and cross-modal retrieval, and pathology report generation.
Multistain Pretraining for Slide Representation Learning in Pathology
Aug 05, 2024Developing self-supervised learning (SSL) models that can learn universal and transferable representations of H&E gigapixel whole-slide images (WSIs) is becoming increasingly valuable in computational pathology. These models hold the potential to advance critical tasks such as few-shot classification, slide retrieval, and patient stratification. Existing approaches for slide representation learning extend the principles of SSL from small images (e.g., 224 x 224 patches) to entire slides, usually by aligning two different augmentations (or views) of the slide. Yet the resulting representation remains constrained by the limited clinical and biological diversity of the views. Instead, we postulate that slides stained with multiple markers, such as immunohistochemistry, can be used as different views to form a rich task-agnostic training signal. To this end, we introduce Madeleine, a multimodal pretraining strategy for slide representation learning. Madeleine is trained with a dual global-local cross-stain alignment objective on large cohorts of breast cancer samples (N=4,211 WSIs across five stains) and kidney transplant samples (N=12,070 WSIs across four stains). We demonstrate the quality of slide representations learned by Madeleine on various downstream evaluations, ranging from morphological and molecular classification to prognostic prediction, comprising 21 tasks using 7,299 WSIs from multiple medical centers. Code is available at https://github.com/mahmoodlab/MADELEINE.
A General-Purpose Self-Supervised Model for Computational Pathology
Aug 29, 2023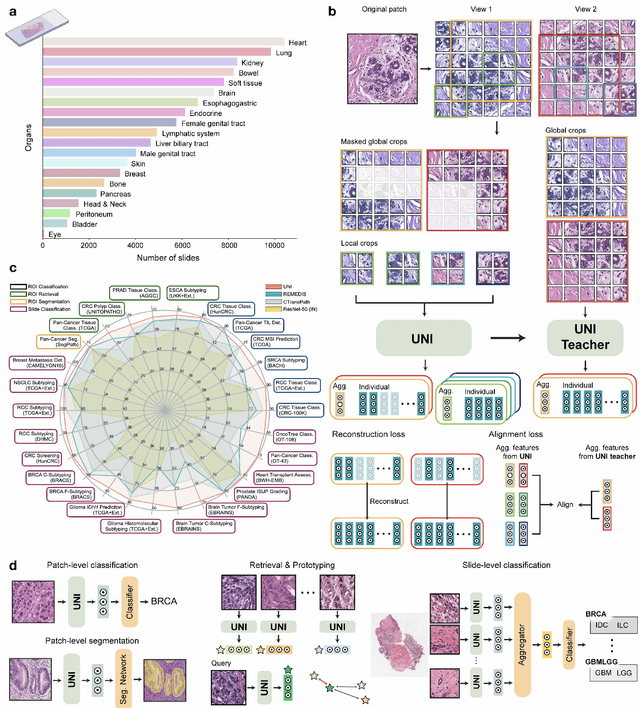

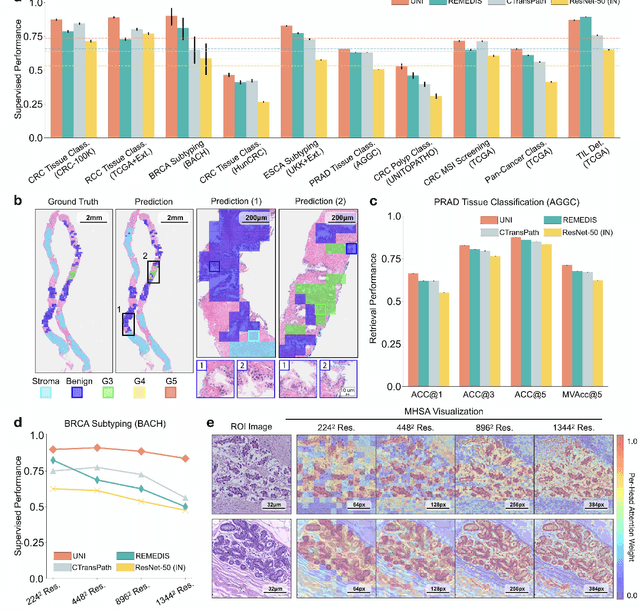

Tissue phenotyping is a fundamental computational pathology (CPath) task in learning objective characterizations of histopathologic biomarkers in anatomic pathology. However, whole-slide imaging (WSI) poses a complex computer vision problem in which the large-scale image resolutions of WSIs and the enormous diversity of morphological phenotypes preclude large-scale data annotation. Current efforts have proposed using pretrained image encoders with either transfer learning from natural image datasets or self-supervised pretraining on publicly-available histopathology datasets, but have not been extensively developed and evaluated across diverse tissue types at scale. We introduce UNI, a general-purpose self-supervised model for pathology, pretrained using over 100 million tissue patches from over 100,000 diagnostic haematoxylin and eosin-stained WSIs across 20 major tissue types, and evaluated on 33 representative CPath clinical tasks in CPath of varying diagnostic difficulties. In addition to outperforming previous state-of-the-art models, we demonstrate new modeling capabilities in CPath such as resolution-agnostic tissue classification, slide classification using few-shot class prototypes, and disease subtyping generalization in classifying up to 108 cancer types in the OncoTree code classification system. UNI advances unsupervised representation learning at scale in CPath in terms of both pretraining data and downstream evaluation, enabling data-efficient AI models that can generalize and transfer to a gamut of diagnostically-challenging tasks and clinical workflows in anatomic pathology.
Algorithm Fairness in AI for Medicine and Healthcare
Oct 01, 2021
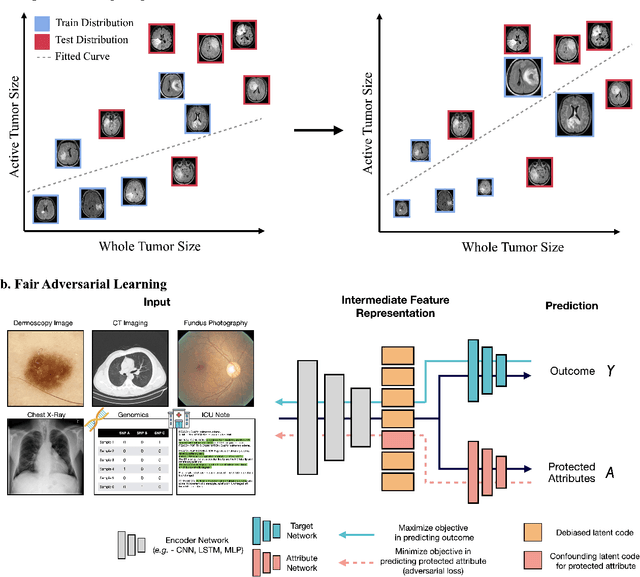

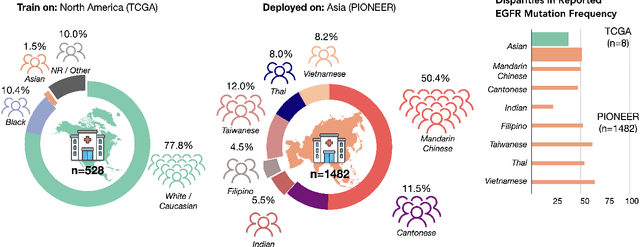
In the current development and deployment of many artificial intelligence (AI) systems in healthcare, algorithm fairness is a challenging problem in delivering equitable care. Recent evaluation of AI models stratified across race sub-populations have revealed enormous inequalities in how patients are diagnosed, given treatments, and billed for healthcare costs. In this perspective article, we summarize the intersectional field of fairness in machine learning through the context of current issues in healthcare, outline how algorithmic biases (e.g. - image acquisition, genetic variation, intra-observer labeling variability) arise in current clinical workflows and their resulting healthcare disparities. Lastly, we also review emerging strategies for mitigating bias via decentralized learning, disentanglement, and model explainability.