 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFair k-Means Clustering
Jun 17, 2020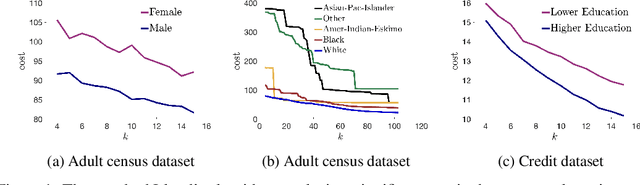
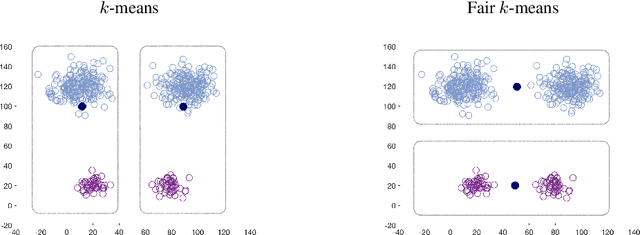
We show that the popular $k$-means clustering algorithm (Lloyd's heuristic), used for a variety of scientific data, can result in outcomes that are unfavorable to subgroups of data (e.g., demographic groups). Such biased clusterings can have deleterious implications for human-centric applications such as resource allocation. We present a fair $k$-means objective and algorithm to choose cluster centers that provide equitable costs for different groups. The algorithm, Fair-Lloyd, is a modification of Lloyd's heuristic for $k$-means, inheriting its simplicity, efficiency, and stability. In comparison with standard Lloyd's, we find that on benchmark data sets, Fair-Lloyd exhibits unbiased performance by ensuring that all groups have balanced costs in the output $k$-clustering, while incurring a negligible increase in running time, thus making it a viable fair option wherever $k$-means is currently used.
Robustly Clustering a Mixture of Gaussians
Nov 26, 2019We give an efficient algorithm for robustly clustering of a mixture of arbitrary Gaussians, a central open problem in the theory of computationally efficient robust estimation, assuming only that for each pair of component Gaussians, their means are well-separated or their covariances are well-separated.
Fair Dimensionality Reduction and Iterative Rounding for SDPs
Feb 28, 2019
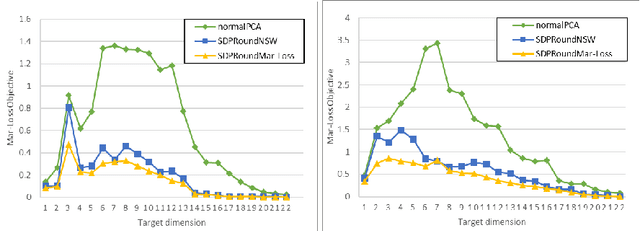
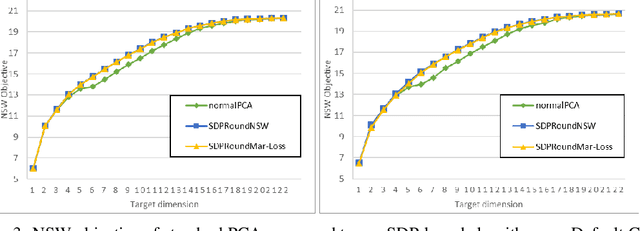
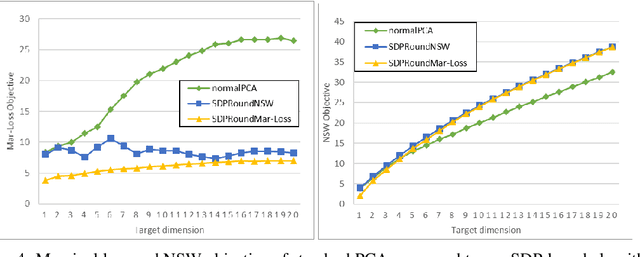
We model "fair" dimensionality reduction as an optimization problem. A central example is the fair PCA problem: the input data is divided into $k$ groups, and the goal is to find a single $d$-dimensional representation for all groups for which the maximum variance (or minimum reconstruction error) is optimized for all groups in a fair (or balanced) manner, e.g., by maximizing the minimum variance over the $k$ groups of the projection to a $d$-dimensional subspace. This problem was introduced by Samadi et al. (2018) who gave a polynomial-time algorithm which, for $k=2$ groups, returns a $(d+1)$-dimensional solution of value at least the best $d$-dimensional solution. We give an exact polynomial-time algorithm for $k=2$ groups. The result relies on extending results of Pataki (1998) regarding rank of extreme point solutions to semi-definite programs. This approach applies more generally to any monotone concave function of the individual group objectives. For $k>2$ groups, our results generalize to give a $(d+\sqrt{2k+0.25}-1.5)$-dimensional solution with objective value as good as the optimal $d$-dimensional solution for arbitrary $k,d$ in polynomial time. Using our extreme point characterization result for SDPs, we give an iterative rounding framework for general SDPs which generalizes the well-known iterative rounding approach for LPs. It returns low-rank solutions with bounded violation of constraints. We obtain a $d$-dimensional projection where the violation in the objective can be bounded additively in terms of the top $O(\sqrt{k})$-singular values of the data matrices. We also give an exact polynomial-time algorithm for any fixed number of groups and target dimension via the algorithm of Grigoriev and Pasechnik (2005). In contrast, when the number of groups is part of the input, even for target dimension $d=1$, we show this problem is NP-hard.
The Price of Fair PCA: One Extra Dimension
Oct 31, 2018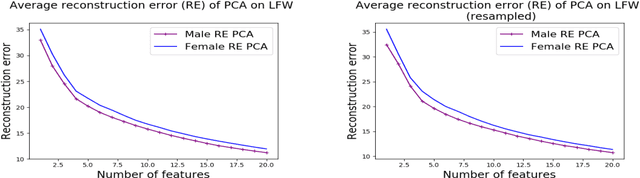
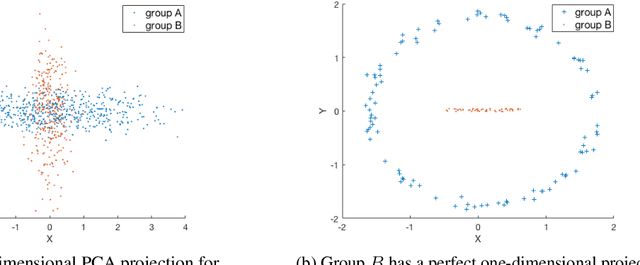
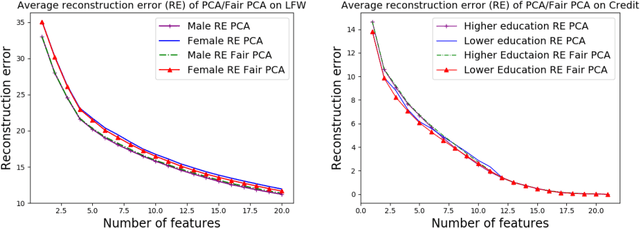
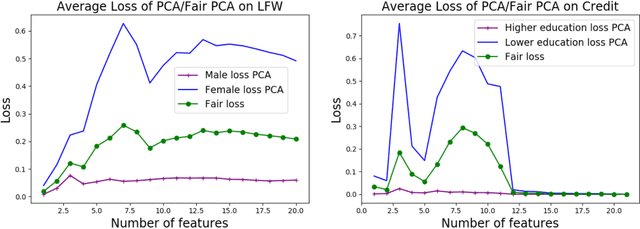
We investigate whether the standard dimensionality reduction technique of PCA inadvertently produces data representations with different fidelity for two different populations. We show on several real-world data sets, PCA has higher reconstruction error on population A than on B (for example, women versus men or lower- versus higher-educated individuals). This can happen even when the data set has a similar number of samples from A and B. This motivates our study of dimensionality reduction techniques which maintain similar fidelity for A and B. We define the notion of Fair PCA and give a polynomial-time algorithm for finding a low dimensional representation of the data which is nearly-optimal with respect to this measure. Finally, we show on real-world data sets that our algorithm can be used to efficiently generate a fair low dimensional representation of the data.
Smoothed Analysis of Discrete Tensor Decomposition and Assemblies of Neurons
Oct 28, 2018We analyze linear independence of rank one tensors produced by tensor powers of randomly perturbed vectors. This enables efficient decomposition of sums of high-order tensors. Our analysis builds upon [BCMV14] but allows for a wider range of perturbation models, including discrete ones. We give an application to recovering assemblies of neurons. Assemblies are large sets of neurons representing specific memories or concepts. The size of the intersection of two assemblies has been shown in experiments to represent the extent to which these memories co-occur or these concepts are related; the phenomenon is called association of assemblies. This suggests that an animal's memory is a complex web of associations, and poses the problem of recovering this representation from cognitive data. Motivated by this problem, we study the following more general question: Can we reconstruct the Venn diagram of a family of sets, given the sizes of their $\ell$-wise intersections? We show that as long as the family of sets is randomly perturbed, it is enough for the number of measurements to be polynomially larger than the number of nonempty regions of the Venn diagram to fully reconstruct the diagram.
Polynomial Convergence of Gradient Descent for Training One-Hidden-Layer Neural Networks
May 07, 2018We analyze Gradient Descent applied to learning a bounded target function on $n$ real-valued inputs by training a neural network with a single hidden layer of nonlinear gates. Our main finding is that GD starting from a randomly initialized network converges in mean squared loss to the minimum error (in 2-norm) of the best approximation of the target function using a polynomial of degree at most $k$. Moreover, the size of the network and number of iterations needed are both bounded by $n^{O(k)}$. The core of our analysis is the following existence theorem, which is of independent interest: for any $\epsilon > 0$, any bounded function that has a degree-$k$ polynomial approximation with error $\epsilon_0$ (in 2-norm), can be approximated to within error $\epsilon_0 + \epsilon$ as a linear combination of $n^{O(k)} \mbox{poly}(1/\epsilon)$ randomly chosen gates from any class of gates whose corresponding activation function has nonzero coefficients in its harmonic expansion for degrees up to $k$. In particular, this applies to training networks of unbiased sigmoids and ReLUs.
On the Complexity of Learning Neural Networks
Jul 14, 2017
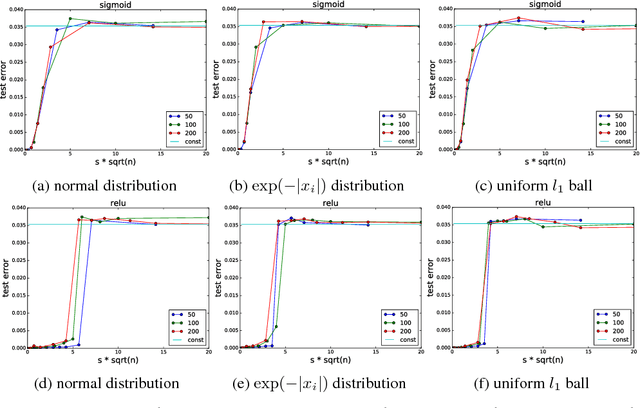
The stunning empirical successes of neural networks currently lack rigorous theoretical explanation. What form would such an explanation take, in the face of existing complexity-theoretic lower bounds? A first step might be to show that data generated by neural networks with a single hidden layer, smooth activation functions and benign input distributions can be learned efficiently. We demonstrate here a comprehensive lower bound ruling out this possibility: for a wide class of activation functions (including all currently used), and inputs drawn from any logconcave distribution, there is a family of one-hidden-layer functions whose output is a sum gate, that are hard to learn in a precise sense: any statistical query algorithm (which includes all known variants of stochastic gradient descent with any loss function) needs an exponential number of queries even using tolerance inversely proportional to the input dimensionality. Moreover, this hard family of functions is realizable with a small (sublinear in dimension) number of activation units in the single hidden layer. The lower bound is also robust to small perturbations of the true weights. Systematic experiments illustrate a phase transition in the training error as predicted by the analysis.
Statistical Query Algorithms for Mean Vector Estimation and Stochastic Convex Optimization
Nov 22, 2016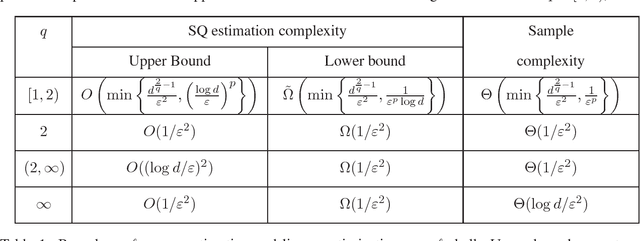

Stochastic convex optimization, where the objective is the expectation of a random convex function, is an important and widely used method with numerous applications in machine learning, statistics, operations research and other areas. We study the complexity of stochastic convex optimization given only statistical query (SQ) access to the objective function. We show that well-known and popular first-order iterative methods can be implemented using only statistical queries. For many cases of interest we derive nearly matching upper and lower bounds on the estimation (sample) complexity including linear optimization in the most general setting. We then present several consequences for machine learning, differential privacy and proving concrete lower bounds on the power of convex optimization based methods. The key ingredient of our work is SQ algorithms and lower bounds for estimating the mean vector of a distribution over vectors supported on a convex body in $\mathbb{R}^d$. This natural problem has not been previously studied and we show that our solutions can be used to get substantially improved SQ versions of Perceptron and other online algorithms for learning halfspaces.
Chi-squared Amplification: Identifying Hidden Hubs
Nov 16, 2016We consider the following general hidden hubs model: an $n \times n$ random matrix $A$ with a subset $S$ of $k$ special rows (hubs): entries in rows outside $S$ are generated from the probability distribution $p_0 \sim N(0,\sigma_0^2)$; for each row in $S$, some $k$ of its entries are generated from $p_1 \sim N(0,\sigma_1^2)$, $\sigma_1>\sigma_0$, and the rest of the entries from $p_0$. The problem is to identify the high-degree hubs efficiently. This model includes and significantly generalizes the planted Gaussian Submatrix Model, where the special entries are all in a $k \times k$ submatrix. There are two well-known barriers: if $k\geq c\sqrt{n\ln n}$, just the row sums are sufficient to find $S$ in the general model. For the submatrix problem, this can be improved by a $\sqrt{\ln n}$ factor to $k \ge c\sqrt{n}$ by spectral methods or combinatorial methods. In the variant with $p_0=\pm 1$ (with probability $1/2$ each) and $p_1\equiv 1$, neither barrier has been broken. We give a polynomial-time algorithm to identify all the hidden hubs with high probability for $k \ge n^{0.5-\delta}$ for some $\delta >0$, when $\sigma_1^2>2\sigma_0^2$. The algorithm extends to the setting where planted entries might have different variances each at least as large as $\sigma_1^2$. We also show a nearly matching lower bound: for $\sigma_1^2 \le 2\sigma_0^2$, there is no polynomial-time Statistical Query algorithm for distinguishing between a matrix whose entries are all from $N(0,\sigma_0^2)$ and a matrix with $k=n^{0.5-\delta}$ hidden hubs for any $\delta >0$. The lower bound as well as the algorithm are related to whether the chi-squared distance of the two distributions diverges. At the critical value $\sigma_1^2=2\sigma_0^2$, we show that the general hidden hubs problem can be solved for $k\geq c\sqrt n(\ln n)^{1/4}$, improving on the naive row sum-based method.
Agnostic Estimation of Mean and Covariance
Aug 14, 2016We consider the problem of estimating the mean and covariance of a distribution from iid samples in $\mathbb{R}^n$, in the presence of an $\eta$ fraction of malicious noise; this is in contrast to much recent work where the noise itself is assumed to be from a distribution of known type. The agnostic problem includes many interesting special cases, e.g., learning the parameters of a single Gaussian (or finding the best-fit Gaussian) when $\eta$ fraction of data is adversarially corrupted, agnostically learning a mixture of Gaussians, agnostic ICA, etc. We present polynomial-time algorithms to estimate the mean and covariance with error guarantees in terms of information-theoretic lower bounds. As a corollary, we also obtain an agnostic algorithm for Singular Value Decomposition.