 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a Latent Simplex in Input-Sparsity Time
May 17, 2021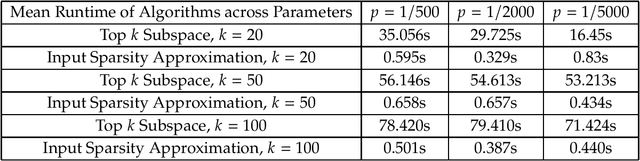

We consider the problem of learning a latent $k$-vertex simplex $K\subset\mathbb{R}^d$, given access to $A\in\mathbb{R}^{d\times n}$, which can be viewed as a data matrix with $n$ points that are obtained by randomly perturbing latent points in the simplex $K$ (potentially beyond $K$). A large class of latent variable models, such as adversarial clustering, mixed membership stochastic block models, and topic models can be cast as learning a latent simplex. Bhattacharyya and Kannan (SODA, 2020) give an algorithm for learning such a latent simplex in time roughly $O(k\cdot\textrm{nnz}(A))$, where $\textrm{nnz}(A)$ is the number of non-zeros in $A$. We show that the dependence on $k$ in the running time is unnecessary given a natural assumption about the mass of the top $k$ singular values of $A$, which holds in many of these applications. Further, we show this assumption is necessary, as otherwise an algorithm for learning a latent simplex would imply an algorithmic breakthrough for spectral low rank approximation. At a high level, Bhattacharyya and Kannan provide an adaptive algorithm that makes $k$ matrix-vector product queries to $A$ and each query is a function of all queries preceding it. Since each matrix-vector product requires $\textrm{nnz}(A)$ time, their overall running time appears unavoidable. Instead, we obtain a low-rank approximation to $A$ in input-sparsity time and show that the column space thus obtained has small $\sin\Theta$ (angular) distance to the right top-$k$ singular space of $A$. Our algorithm then selects $k$ points in the low-rank subspace with the largest inner product with $k$ carefully chosen random vectors. By working in the low-rank subspace, we avoid reading the entire matrix in each iteration and thus circumvent the $\Theta(k\cdot\textrm{nnz}(A))$ running time.
Chi-squared Amplification: Identifying Hidden Hubs
Nov 16, 2016We consider the following general hidden hubs model: an $n \times n$ random matrix $A$ with a subset $S$ of $k$ special rows (hubs): entries in rows outside $S$ are generated from the probability distribution $p_0 \sim N(0,\sigma_0^2)$; for each row in $S$, some $k$ of its entries are generated from $p_1 \sim N(0,\sigma_1^2)$, $\sigma_1>\sigma_0$, and the rest of the entries from $p_0$. The problem is to identify the high-degree hubs efficiently. This model includes and significantly generalizes the planted Gaussian Submatrix Model, where the special entries are all in a $k \times k$ submatrix. There are two well-known barriers: if $k\geq c\sqrt{n\ln n}$, just the row sums are sufficient to find $S$ in the general model. For the submatrix problem, this can be improved by a $\sqrt{\ln n}$ factor to $k \ge c\sqrt{n}$ by spectral methods or combinatorial methods. In the variant with $p_0=\pm 1$ (with probability $1/2$ each) and $p_1\equiv 1$, neither barrier has been broken. We give a polynomial-time algorithm to identify all the hidden hubs with high probability for $k \ge n^{0.5-\delta}$ for some $\delta >0$, when $\sigma_1^2>2\sigma_0^2$. The algorithm extends to the setting where planted entries might have different variances each at least as large as $\sigma_1^2$. We also show a nearly matching lower bound: for $\sigma_1^2 \le 2\sigma_0^2$, there is no polynomial-time Statistical Query algorithm for distinguishing between a matrix whose entries are all from $N(0,\sigma_0^2)$ and a matrix with $k=n^{0.5-\delta}$ hidden hubs for any $\delta >0$. The lower bound as well as the algorithm are related to whether the chi-squared distance of the two distributions diverges. At the critical value $\sigma_1^2=2\sigma_0^2$, we show that the general hidden hubs problem can be solved for $k\geq c\sqrt n(\ln n)^{1/4}$, improving on the naive row sum-based method.
Computing a Nonnegative Matrix Factorization -- Provably
Nov 03, 2011

In the Nonnegative Matrix Factorization (NMF) problem we are given an $n \times m$ nonnegative matrix $M$ and an integer $r > 0$. Our goal is to express $M$ as $A W$ where $A$ and $W$ are nonnegative matrices of size $n \times r$ and $r \times m$ respectively. In some applications, it makes sense to ask instead for the product $AW$ to approximate $M$ -- i.e. (approximately) minimize $\norm{M - AW}_F$ where $\norm{}_F$ denotes the Frobenius norm; we refer to this as Approximate NMF. This problem has a rich history spanning quantum mechanics, probability theory, data analysis, polyhedral combinatorics, communication complexity, demography, chemometrics, etc. In the past decade NMF has become enormously popular in machine learning, where $A$ and $W$ are computed using a variety of local search heuristics. Vavasis proved that this problem is NP-complete. We initiate a study of when this problem is solvable in polynomial time: 1. We give a polynomial-time algorithm for exact and approximate NMF for every constant $r$. Indeed NMF is most interesting in applications precisely when $r$ is small. 2. We complement this with a hardness result, that if exact NMF can be solved in time $(nm)^{o(r)}$, 3-SAT has a sub-exponential time algorithm. This rules out substantial improvements to the above algorithm. 3. We give an algorithm that runs in time polynomial in $n$, $m$ and $r$ under the separablity condition identified by Donoho and Stodden in 2003. The algorithm may be practical since it is simple and noise tolerant (under benign assumptions). Separability is believed to hold in many practical settings. To the best of our knowledge, this last result is the first example of a polynomial-time algorithm that provably works under a non-trivial condition on the input and we believe that this will be an interesting and important direction for future work.
Discovering Global Patterns in Linguistic Networks through Spectral Analysis: A Case Study of the Consonant Inventories
Jan 15, 2009
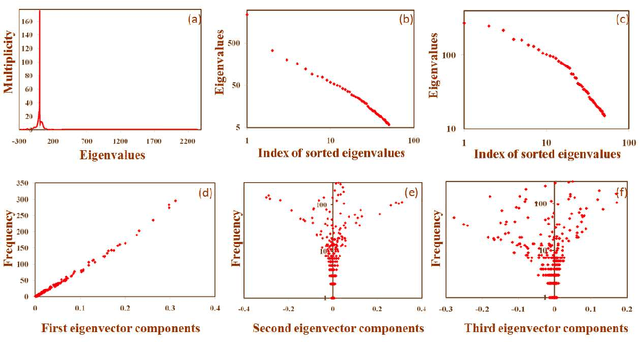

Recent research has shown that language and the socio-cognitive phenomena associated with it can be aptly modeled and visualized through networks of linguistic entities. However, most of the existing works on linguistic networks focus only on the local properties of the networks. This study is an attempt to analyze the structure of languages via a purely structural technique, namely spectral analysis, which is ideally suited for discovering the global correlations in a network. Application of this technique to PhoNet, the co-occurrence network of consonants, not only reveals several natural linguistic principles governing the structure of the consonant inventories, but is also able to quantify their relative importance. We believe that this powerful technique can be successfully applied, in general, to study the structure of natural languages.