 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a Latent Simplex in Input-Sparsity Time
Paper and Code
May 17, 2021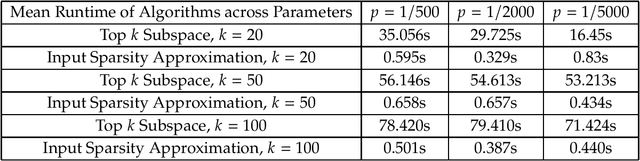

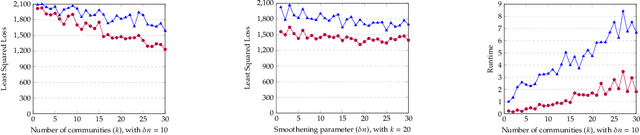
We consider the problem of learning a latent $k$-vertex simplex $K\subset\mathbb{R}^d$, given access to $A\in\mathbb{R}^{d\times n}$, which can be viewed as a data matrix with $n$ points that are obtained by randomly perturbing latent points in the simplex $K$ (potentially beyond $K$). A large class of latent variable models, such as adversarial clustering, mixed membership stochastic block models, and topic models can be cast as learning a latent simplex. Bhattacharyya and Kannan (SODA, 2020) give an algorithm for learning such a latent simplex in time roughly $O(k\cdot\textrm{nnz}(A))$, where $\textrm{nnz}(A)$ is the number of non-zeros in $A$. We show that the dependence on $k$ in the running time is unnecessary given a natural assumption about the mass of the top $k$ singular values of $A$, which holds in many of these applications. Further, we show this assumption is necessary, as otherwise an algorithm for learning a latent simplex would imply an algorithmic breakthrough for spectral low rank approximation. At a high level, Bhattacharyya and Kannan provide an adaptive algorithm that makes $k$ matrix-vector product queries to $A$ and each query is a function of all queries preceding it. Since each matrix-vector product requires $\textrm{nnz}(A)$ time, their overall running time appears unavoidable. Instead, we obtain a low-rank approximation to $A$ in input-sparsity time and show that the column space thus obtained has small $\sin\Theta$ (angular) distance to the right top-$k$ singular space of $A$. Our algorithm then selects $k$ points in the low-rank subspace with the largest inner product with $k$ carefully chosen random vectors. By working in the low-rank subspace, we avoid reading the entire matrix in each iteration and thus circumvent the $\Theta(k\cdot\textrm{nnz}(A))$ running time.