 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWE-bench-java: A GitHub Issue Resolving Benchmark for Java
Aug 26, 2024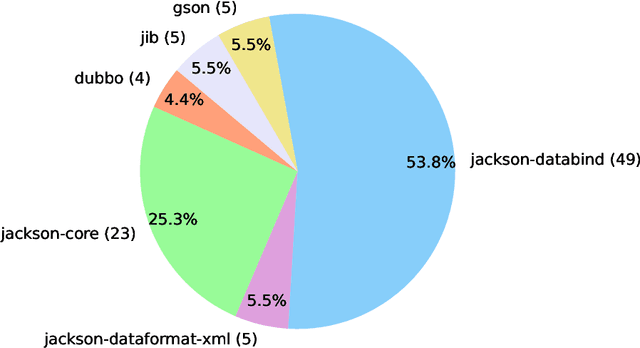



GitHub issue resolving is a critical task in software engineering, recently gaining significant attention in both industry and academia. Within this task, SWE-bench has been released to evaluate issue resolving capabilities of large language models (LLMs), but has so far only focused on Python version. However, supporting more programming languages is also important, as there is a strong demand in industry. As a first step toward multilingual support, we have developed a Java version of SWE-bench, called SWE-bench-java. We have publicly released the dataset, along with the corresponding Docker-based evaluation environment and leaderboard, which will be continuously maintained and updated in the coming months. To verify the reliability of SWE-bench-java, we implement a classic method SWE-agent and test several powerful LLMs on it. As is well known, developing a high-quality multi-lingual benchmark is time-consuming and labor-intensive, so we welcome contributions through pull requests or collaboration to accelerate its iteration and refinement, paving the way for fully automated programming.
CodeR: Issue Resolving with Multi-Agent and Task Graphs
Jun 03, 2024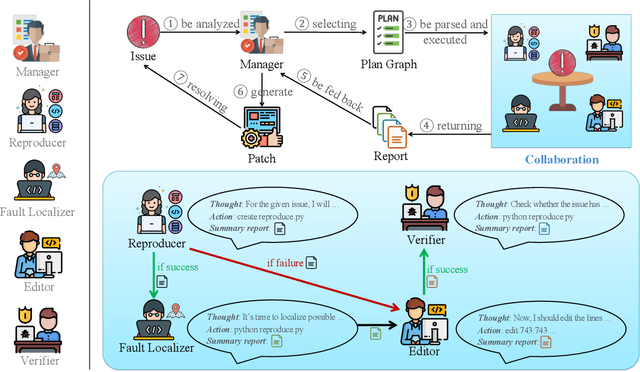
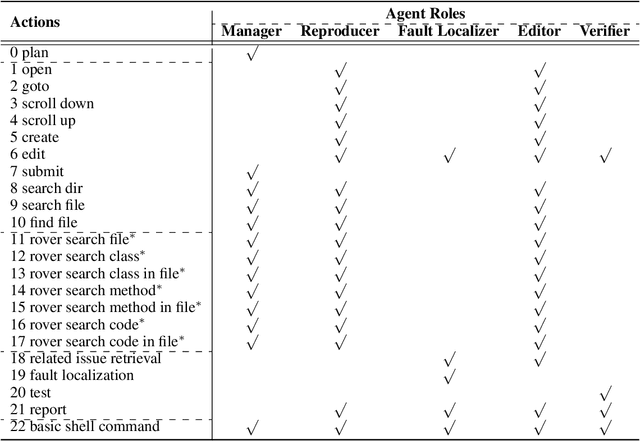

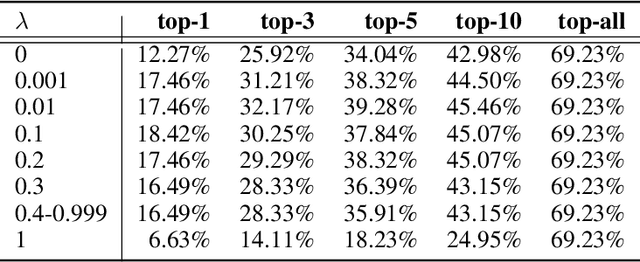
GitHub issue resolving recently has attracted significant attention from academia and industry. SWE-bench is proposed to measure the performance in resolving issues. In this paper, we propose CodeR, which adopts a multi-agent framework and pre-defined task graphs to Repair & Resolve reported bugs and add new features within code Repository. On SWE-bench lite, CodeR is able to solve 28.00% of issues, in the case of submitting only once for each issue. We examine the performance impact of each design of CodeR and offer insights to advance this research direction.
Deep Text Classification Can be Fooled
Apr 26, 2017

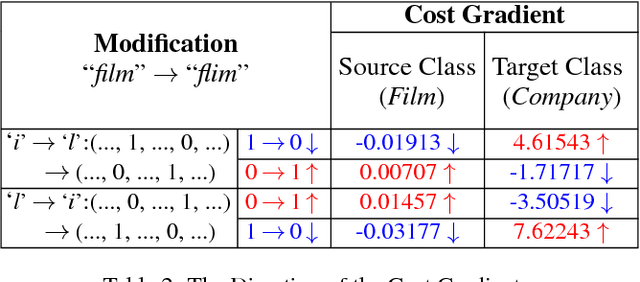

Deep neural networks (DNNs) play a key role in many applications. Current studies focus on crafting adversarial samples against DNN-based image classifiers by introducing some imperceptible perturbations to the input. However, DNNs for natural language processing have not got the attention they deserve. In fact, the existing perturbation algorithms for images cannot be directly applied to text. This paper presents a simple but effective method to attack DNN-based text classifiers. Three perturbation strategies, namely insertion, modification, and removal, are designed to generate an adversarial sample for a given text. By computing the cost gradients, what should be inserted, modified or removed, where to insert and how to modify are determined effectively. The experimental results show that the adversarial samples generated by our method can successfully fool a state-of-the-art model to misclassify them as any desirable classes without compromising their utilities. At the same time, the introduced perturbations are difficult to be perceived. Our study demonstrates that DNN-based text classifiers are also prone to the adversarial sample attack.