 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackdoor Sentinel: Detecting and Detoxifying Backdoors in Diffusion Models via Temporal Noise Consistency
Feb 02, 2026Diffusion models have been widely deployed in AIGC services; however, their reliance on opaque training data and procedures exposes a broad attack surface for backdoor injection. In practical auditing scenarios, due to the protection of intellectual property and commercial confidentiality, auditors are typically unable to access model parameters, rendering existing white-box or query-intensive detection methods impractical. More importantly, even after the backdoor is detected, existing detoxification approaches are often trapped in a dilemma between detoxification effectiveness and generation quality. In this work, we identify a previously unreported phenomenon called temporal noise unconsistency, where the noise predictions between adjacent diffusion timesteps is disrupted in specific temporal segments when the input is triggered, while remaining stable under clean inputs. Leveraging this finding, we propose Temporal Noise Consistency Defense (TNC-Defense), a unified framework for backdoor detection and detoxification. The framework first uses the adjacent timestep noise consistency to design a gray-box detection module, for identifying and locating anomalous diffusion timesteps. Furthermore, the framework uses the identified anomalous timesteps to construct a trigger-agnostic, timestep-aware detoxification module, which directly corrects the backdoor generation path. This effectively suppresses backdoor behavior while significantly reducing detoxification costs. We evaluate the proposed method under five representative backdoor attack scenarios and compare it with state-of-the-art defenses. The results show that TNC-Defense improves the average detection accuracy by $11\%$ with negligible additional overhead, and invalidates an average of $98.5\%$ of triggered samples with only a mild degradation in generation quality.
Detecting Adversarial Image Examples in Deep Networks with Adaptive Noise Reduction
Jun 03, 2018

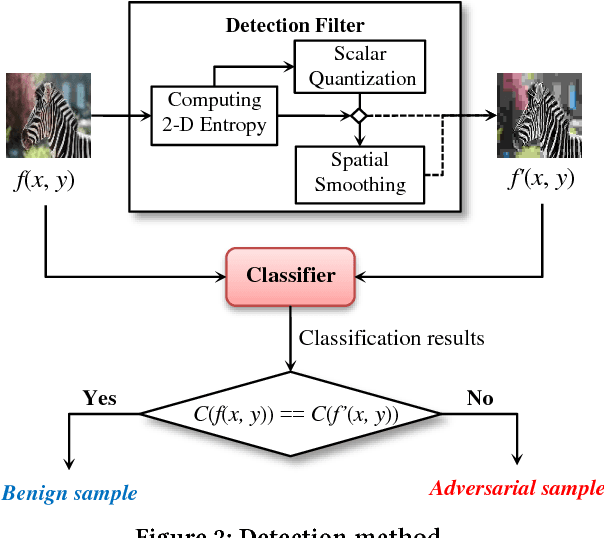
Recently, many studies have demonstrated deep neural network (DNN) classifiers can be fooled by the adversarial example, which is crafted via introducing some perturbations into an original sample. Accordingly, some powerful defense techniques were proposed. However, existing defense techniques often require modifying the target model or depend on the prior knowledge of attacks. In this paper, we propose a straightforward method for detecting adversarial image examples, which can be directly deployed into unmodified off-the-shelf DNN models. We consider the perturbation to images as a kind of noise and introduce two classic image processing techniques, scalar quantization and smoothing spatial filter, to reduce its effect. The image entropy is employed as a metric to implement an adaptive noise reduction for different kinds of images. Consequently, the adversarial example can be effectively detected by comparing the classification results of a given sample and its denoised version, without referring to any prior knowledge of attacks. More than 20,000 adversarial examples against some state-of-the-art DNN models are used to evaluate the proposed method, which are crafted with different attack techniques. The experiments show that our detection method can achieve a high overall F1 score of 96.39% and certainly raises the bar for defense-aware attacks.
Deep Text Classification Can be Fooled
Apr 26, 2017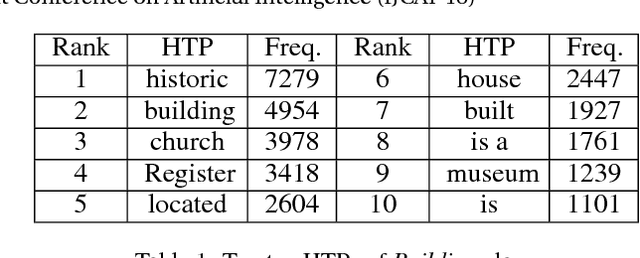

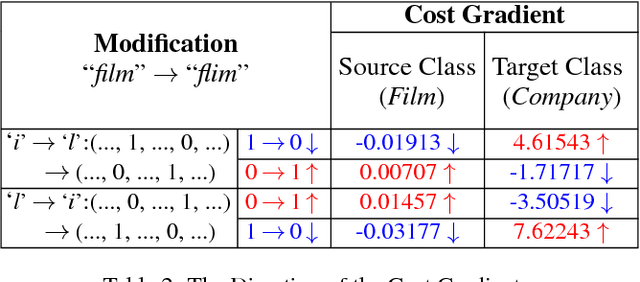

Deep neural networks (DNNs) play a key role in many applications. Current studies focus on crafting adversarial samples against DNN-based image classifiers by introducing some imperceptible perturbations to the input. However, DNNs for natural language processing have not got the attention they deserve. In fact, the existing perturbation algorithms for images cannot be directly applied to text. This paper presents a simple but effective method to attack DNN-based text classifiers. Three perturbation strategies, namely insertion, modification, and removal, are designed to generate an adversarial sample for a given text. By computing the cost gradients, what should be inserted, modified or removed, where to insert and how to modify are determined effectively. The experimental results show that the adversarial samples generated by our method can successfully fool a state-of-the-art model to misclassify them as any desirable classes without compromising their utilities. At the same time, the introduced perturbations are difficult to be perceived. Our study demonstrates that DNN-based text classifiers are also prone to the adversarial sample attack.