 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Resolution Image Editing via Multi-Stage Blended Diffusion
Oct 24, 2022



Diffusion models have shown great results in image generation and in image editing. However, current approaches are limited to low resolutions due to the computational cost of training diffusion models for high-resolution generation. We propose an approach that uses a pre-trained low-resolution diffusion model to edit images in the megapixel range. We first use Blended Diffusion to edit the image at a low resolution, and then upscale it in multiple stages, using a super-resolution model and Blended Diffusion. Using our approach, we achieve higher visual fidelity than by only applying off the shelf super-resolution methods to the output of the diffusion model. We also obtain better global consistency than directly using the diffusion model at a higher resolution.
Surrogate Gradient Field for Latent Space Manipulation
Apr 20, 2021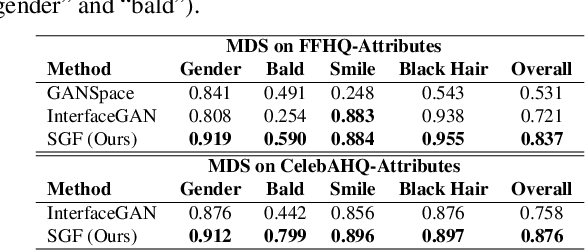


Generative adversarial networks (GANs) can generate high-quality images from sampled latent codes. Recent works attempt to edit an image by manipulating its underlying latent code, but rarely go beyond the basic task of attribute adjustment. We propose the first method that enables manipulation with multidimensional condition such as keypoints and captions. Specifically, we design an algorithm that searches for a new latent code that satisfies the target condition based on the Surrogate Gradient Field (SGF) induced by an auxiliary mapping network. For quantitative comparison, we propose a metric to evaluate the disentanglement of manipulation methods. Thorough experimental analysis on the facial attribute adjustment task shows that our method outperforms state-of-the-art methods in disentanglement. We further apply our method to tasks of various condition modalities to demonstrate that our method can alter complex image properties such as keypoints and captions.
Unsupervised Image-to-Image Translation with Stacked Cycle-Consistent Adversarial Networks
Jul 28, 2018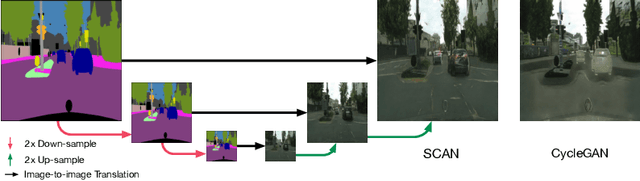
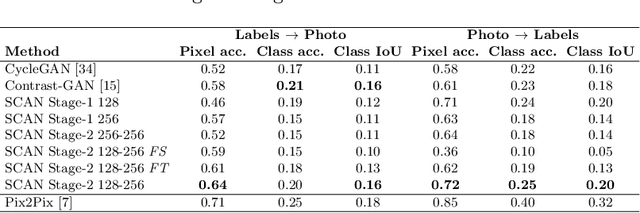
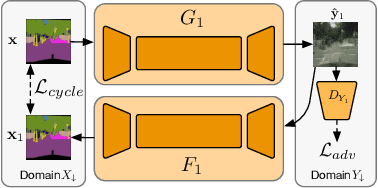
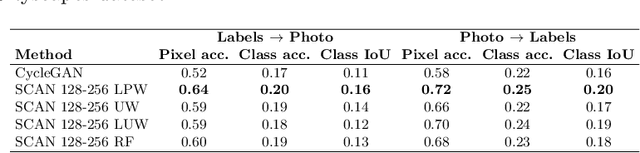
Recent studies on unsupervised image-to-image translation have made a remarkable progress by training a pair of generative adversarial networks with a cycle-consistent loss. However, such unsupervised methods may generate inferior results when the image resolution is high or the two image domains are of significant appearance differences, such as the translations between semantic layouts and natural images in the Cityscapes dataset. In this paper, we propose novel Stacked Cycle-Consistent Adversarial Networks (SCANs) by decomposing a single translation into multi-stage transformations, which not only boost the image translation quality but also enable higher resolution image-to-image translations in a coarse-to-fine manner. Moreover, to properly exploit the information from the previous stage, an adaptive fusion block is devised to learn a dynamic integration of the current stage's output and the previous stage's output. Experiments on multiple datasets demonstrate that our proposed approach can improve the translation quality compared with previous single-stage unsupervised methods.
Towards the Automatic Anime Characters Creation with Generative Adversarial Networks
Aug 18, 2017
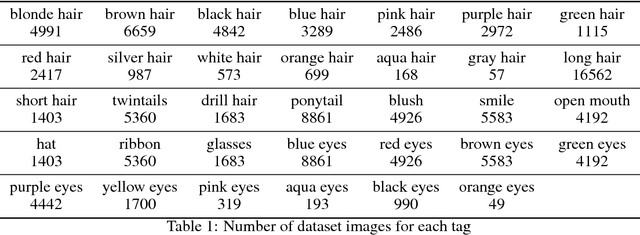


Automatic generation of facial images has been well studied after the Generative Adversarial Network (GAN) came out. There exists some attempts applying the GAN model to the problem of generating facial images of anime characters, but none of the existing work gives a promising result. In this work, we explore the training of GAN models specialized on an anime facial image dataset. We address the issue from both the data and the model aspect, by collecting a more clean, well-suited dataset and leverage proper, empirical application of DRAGAN. With quantitative analysis and case studies we demonstrate that our efforts lead to a stable and high-quality model. Moreover, to assist people with anime character design, we build a website (http://make.girls.moe) with our pre-trained model available online, which makes the model easily accessible to general public.
Weakly Supervised Dense Video Captioning
Apr 05, 2017
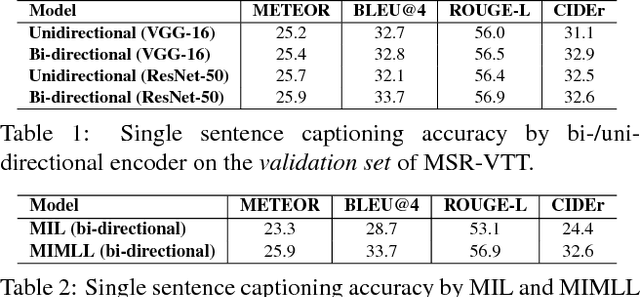
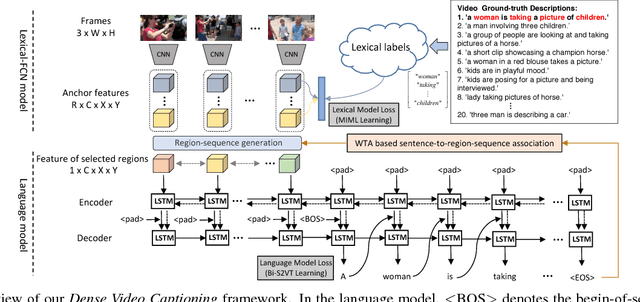
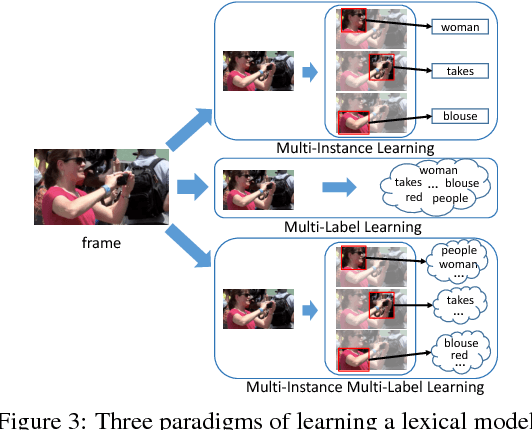
This paper focuses on a novel and challenging vision task, dense video captioning, which aims to automatically describe a video clip with multiple informative and diverse caption sentences. The proposed method is trained without explicit annotation of fine-grained sentence to video region-sequence correspondence, but is only based on weak video-level sentence annotations. It differs from existing video captioning systems in three technical aspects. First, we propose lexical fully convolutional neural networks (Lexical-FCN) with weakly supervised multi-instance multi-label learning to weakly link video regions with lexical labels. Second, we introduce a novel submodular maximization scheme to generate multiple informative and diverse region-sequences based on the Lexical-FCN outputs. A winner-takes-all scheme is adopted to weakly associate sentences to region-sequences in the training phase. Third, a sequence-to-sequence learning based language model is trained with the weakly supervised information obtained through the association process. We show that the proposed method can not only produce informative and diverse dense captions, but also outperform state-of-the-art single video captioning methods by a large margin.