 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Reinforcement Learning from Datasets with Structured Non-Stationarity
May 23, 2024



Current Reinforcement Learning (RL) is often limited by the large amount of data needed to learn a successful policy. Offline RL aims to solve this issue by using transitions collected by a different behavior policy. We address a novel Offline RL problem setting in which, while collecting the dataset, the transition and reward functions gradually change between episodes but stay constant within each episode. We propose a method based on Contrastive Predictive Coding that identifies this non-stationarity in the offline dataset, accounts for it when training a policy, and predicts it during evaluation. We analyze our proposed method and show that it performs well in simple continuous control tasks and challenging, high-dimensional locomotion tasks. We show that our method often achieves the oracle performance and performs better than baselines.
Leveraging Domain-Unlabeled Data in Offline Reinforcement Learning across Two Domains
Apr 11, 2024



In this paper, we investigate an offline reinforcement learning (RL) problem where datasets are collected from two domains. In this scenario, having datasets with domain labels facilitates efficient policy training. However, in practice, the task of assigning domain labels can be resource-intensive or infeasible at a large scale, leading to a prevalence of domain-unlabeled data. To formalize this challenge, we introduce a novel offline RL problem setting named Positive-Unlabeled Offline RL (PUORL), which incorporates domain-unlabeled data. To address PUORL, we develop an offline RL algorithm utilizing positive-unlabeled learning to predict the domain labels of domain-unlabeled data, enabling the integration of this data into policy training. Our experiments show the effectiveness of our method in accurately identifying domains and learning policies that outperform baselines in the PUORL setting, highlighting its capability to leverage domain-unlabeled data effectively.
High-Resolution Image Editing via Multi-Stage Blended Diffusion
Oct 24, 2022



Diffusion models have shown great results in image generation and in image editing. However, current approaches are limited to low resolutions due to the computational cost of training diffusion models for high-resolution generation. We propose an approach that uses a pre-trained low-resolution diffusion model to edit images in the megapixel range. We first use Blended Diffusion to edit the image at a low resolution, and then upscale it in multiple stages, using a super-resolution model and Blended Diffusion. Using our approach, we achieve higher visual fidelity than by only applying off the shelf super-resolution methods to the output of the diffusion model. We also obtain better global consistency than directly using the diffusion model at a higher resolution.
Reducing Overestimation Bias in Multi-Agent Domains Using Double Centralized Critics
Oct 03, 2019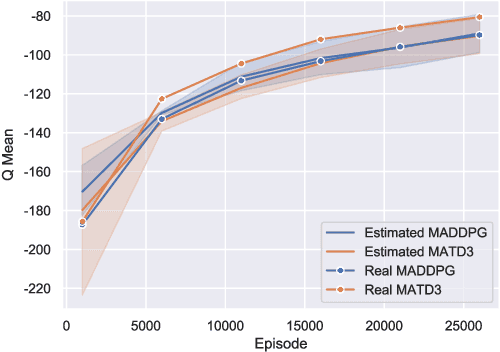
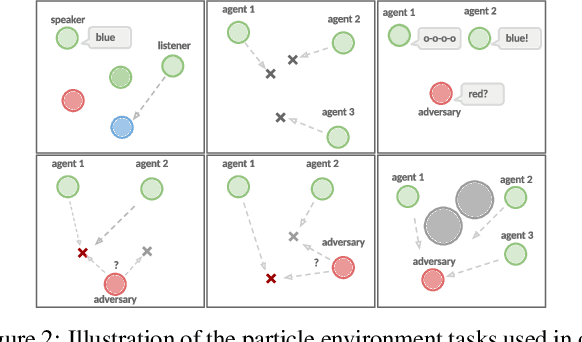
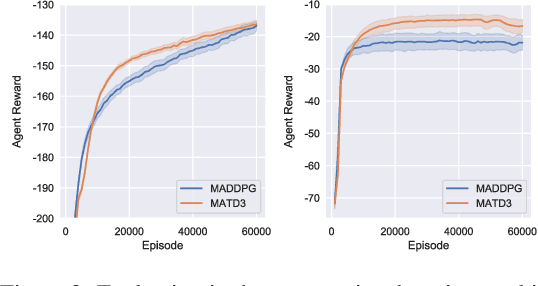
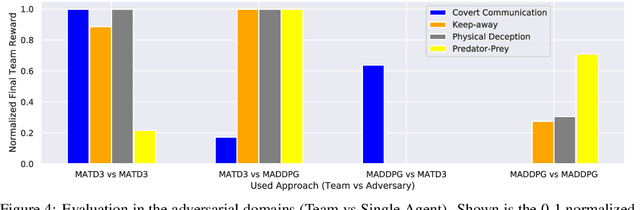
Many real world tasks require multiple agents to work together. Multi-agent reinforcement learning (RL) methods have been proposed in recent years to solve these tasks, but current methods often fail to efficiently learn policies. We thus investigate the presence of a common weakness in single-agent RL, namely value function overestimation bias, in the multi-agent setting. Based on our findings, we propose an approach that reduces this bias by using double centralized critics. We evaluate it on six mixed cooperative-competitive tasks, showing a significant advantage over current methods. Finally, we investigate the application of multi-agent methods to high-dimensional robotic tasks and show that our approach can be used to learn decentralized policies in this domain.