 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSee-through: Single-image Layer Decomposition for Anime Characters
Feb 03, 2026We introduce a framework that automates the transformation of static anime illustrations into manipulatable 2.5D models. Current professional workflows require tedious manual segmentation and the artistic ``hallucination'' of occluded regions to enable motion. Our approach overcomes this by decomposing a single image into fully inpainted, semantically distinct layers with inferred drawing orders. To address the scarcity of training data, we introduce a scalable engine that bootstraps high-quality supervision from commercial Live2D models, capturing pixel-perfect semantics and hidden geometry. Our methodology couples a diffusion-based Body Part Consistency Module, which enforces global geometric coherence, with a pixel-level pseudo-depth inference mechanism. This combination resolves the intricate stratification of anime characters, e.g., interleaving hair strands, allowing for dynamic layer reconstruction. We demonstrate that our approach yields high-fidelity, manipulatable models suitable for professional, real-time animation applications.
Surrogate Gradient Field for Latent Space Manipulation
Apr 20, 2021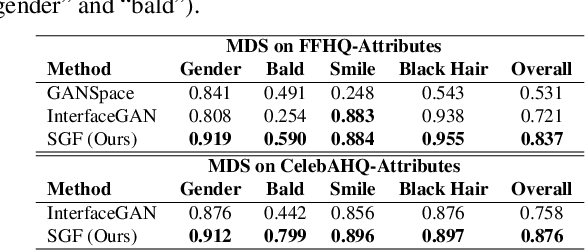


Generative adversarial networks (GANs) can generate high-quality images from sampled latent codes. Recent works attempt to edit an image by manipulating its underlying latent code, but rarely go beyond the basic task of attribute adjustment. We propose the first method that enables manipulation with multidimensional condition such as keypoints and captions. Specifically, we design an algorithm that searches for a new latent code that satisfies the target condition based on the Surrogate Gradient Field (SGF) induced by an auxiliary mapping network. For quantitative comparison, we propose a metric to evaluate the disentanglement of manipulation methods. Thorough experimental analysis on the facial attribute adjustment task shows that our method outperforms state-of-the-art methods in disentanglement. We further apply our method to tasks of various condition modalities to demonstrate that our method can alter complex image properties such as keypoints and captions.
Fast Soft Color Segmentation
Apr 17, 2020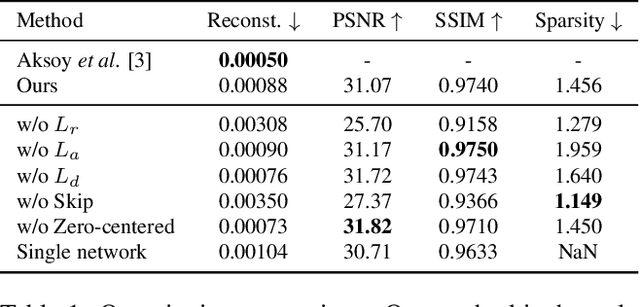


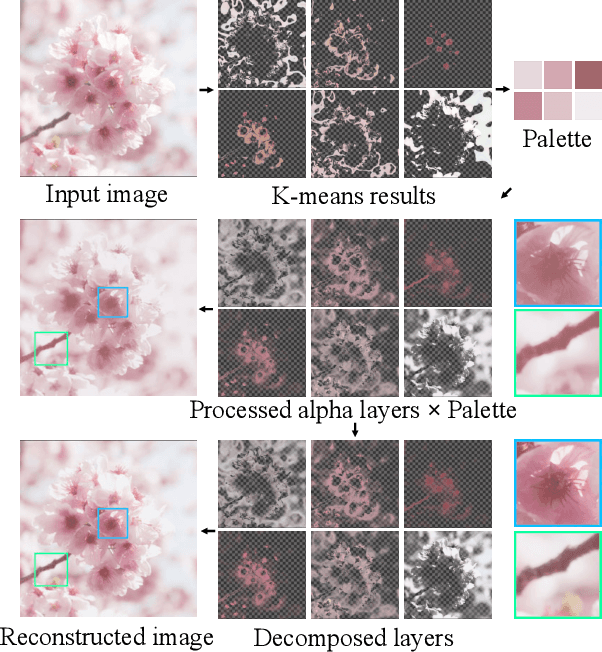
We address the problem of soft color segmentation, defined as decomposing a given image into several RGBA layers, each containing only homogeneous color regions. The resulting layers from decomposition pave the way for applications that benefit from layer-based editing, such as recoloring and compositing of images and videos. The current state-of-the-art approach for this problem is hindered by slow processing time due to its iterative nature, and consequently does not scale to certain real-world scenarios. To address this issue, we propose a neural network based method for this task that decomposes a given image into multiple layers in a single forward pass. Furthermore, our method separately decomposes the color layers and the alpha channel layers. By leveraging a novel training objective, our method achieves proper assignment of colors amongst layers. As a consequence, our method achieve promising quality without existing issue of inference speed for iterative approaches. Our thorough experimental analysis shows that our method produces qualitative and quantitative results comparable to previous methods while achieving a 300,000x speed improvement. Finally, we utilize our proposed method on several applications, and demonstrate its speed advantage, especially in video editing.
Towards the Automatic Anime Characters Creation with Generative Adversarial Networks
Aug 18, 2017
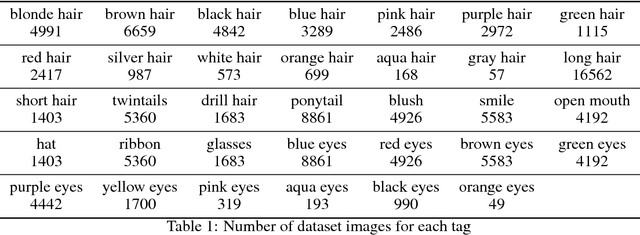


Automatic generation of facial images has been well studied after the Generative Adversarial Network (GAN) came out. There exists some attempts applying the GAN model to the problem of generating facial images of anime characters, but none of the existing work gives a promising result. In this work, we explore the training of GAN models specialized on an anime facial image dataset. We address the issue from both the data and the model aspect, by collecting a more clean, well-suited dataset and leverage proper, empirical application of DRAGAN. With quantitative analysis and case studies we demonstrate that our efforts lead to a stable and high-quality model. Moreover, to assist people with anime character design, we build a website (http://make.girls.moe) with our pre-trained model available online, which makes the model easily accessible to general public.