 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGegelati: Lightweight Artificial Intelligence through Generic and Evolvable Tangled Program Graphs
Dec 15, 2020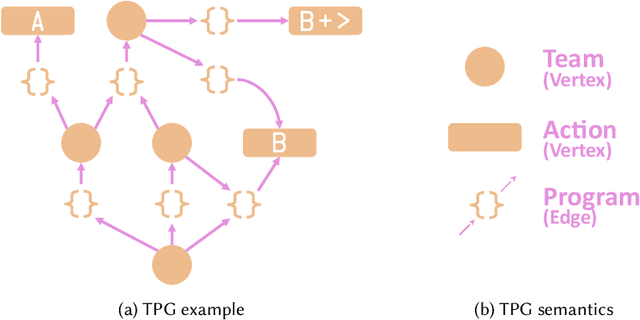
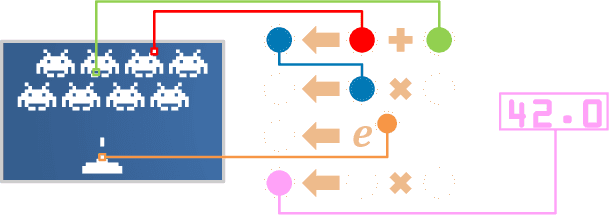
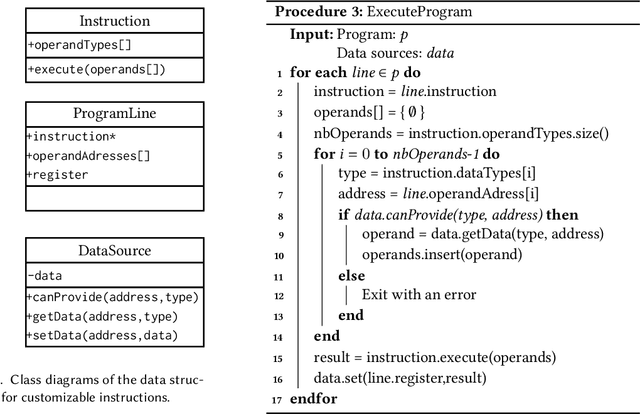
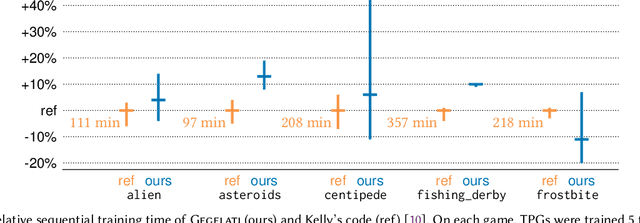
Tangled Program Graph (TPG) is a reinforcement learning technique based on genetic programming concepts. On state-of-the-art learning environments, TPGs have been shown to offer comparable competence with Deep Neural Networks (DNNs), for a fraction of their computational and storage cost. This lightness of TPGs, both for training and inference, makes them an interesting model to implement Artificial Intelligences (AIs) on embedded systems with limited computational and storage resources. In this paper, we introduce the Gegelati library for TPGs. Besides introducing the general concepts and features of the library, two main contributions are detailed in the paper: 1/ The parallelization of the deterministic training process of TPGs, for supporting heterogeneous Multiprocessor Systems-on-Chips (MPSoCs). 2/ The support for customizable instruction sets and data types within the genetically evolved programs of the TPG model. The scalability of the parallel training process is demonstrated through experiments on architectures ranging from a high-end 24-core processor to a low-power heterogeneous MPSoC. The impact of customizable instructions on the outcome of a training process is demonstrated on a state-of-the-art reinforcement learning environment. CCS Concepts: $\bullet$ Computer systems organization $\rightarrow$ Embedded systems; $\bullet$ Computing methodologies $\rightarrow$ Machine learning.
NTIRE 2020 Challenge on Image Demoireing: Methods and Results
May 06, 2020



This paper reviews the Challenge on Image Demoireing that was part of the New Trends in Image Restoration and Enhancement (NTIRE) workshop, held in conjunction with CVPR 2020. Demoireing is a difficult task of removing moire patterns from an image to reveal an underlying clean image. The challenge was divided into two tracks. Track 1 targeted the single image demoireing problem, which seeks to remove moire patterns from a single image. Track 2 focused on the burst demoireing problem, where a set of degraded moire images of the same scene were provided as input, with the goal of producing a single demoired image as output. The methods were ranked in terms of their fidelity, measured using the peak signal-to-noise ratio (PSNR) between the ground truth clean images and the restored images produced by the participants' methods. The tracks had 142 and 99 registered participants, respectively, with a total of 14 and 6 submissions in the final testing stage. The entries span the current state-of-the-art in image and burst image demoireing problems.
NoiseBreaker: Gradual Image Denoising Guided by Noise Analysis
Feb 18, 2020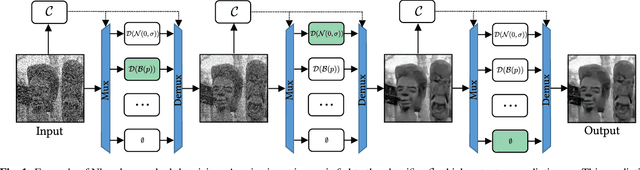
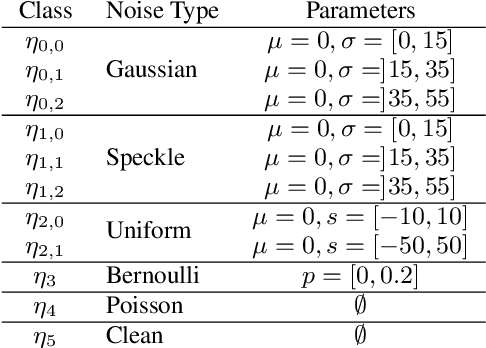

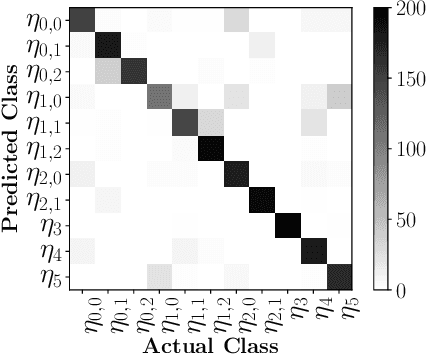
Fully supervised deep-learning based denoisers are currently the most performing image denoising solutions. However, they require clean reference images. When the target noise is complex, e.g. composed of an unknown mixture of primary noises with unknown intensity, fully supervised solutions are limited by the difficulty to build a suited training set for the problem. This paper proposes a gradual denoising strategy that iteratively detects the dominating noise in an image, and removes it using a tailored denoiser. The method is shown to keep up with state of the art blind denoisers on mixture noises. Moreover, noise analysis is demonstrated to guide denoisers efficiently not only on noise type, but also on noise intensity. The method provides an insight on the nature of the encountered noise, and it makes it possible to extend an existing denoiser with new noise nature. This feature makes the method adaptive to varied denoising cases.
OpenDenoising: an Extensible Benchmark for Building Comparative Studies of Image Denoisers
Oct 18, 2019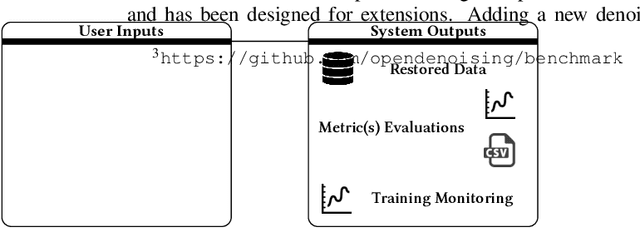
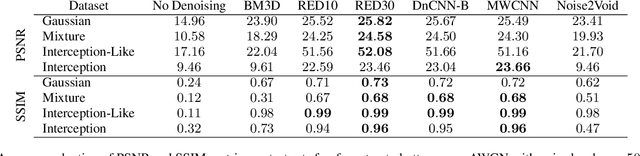
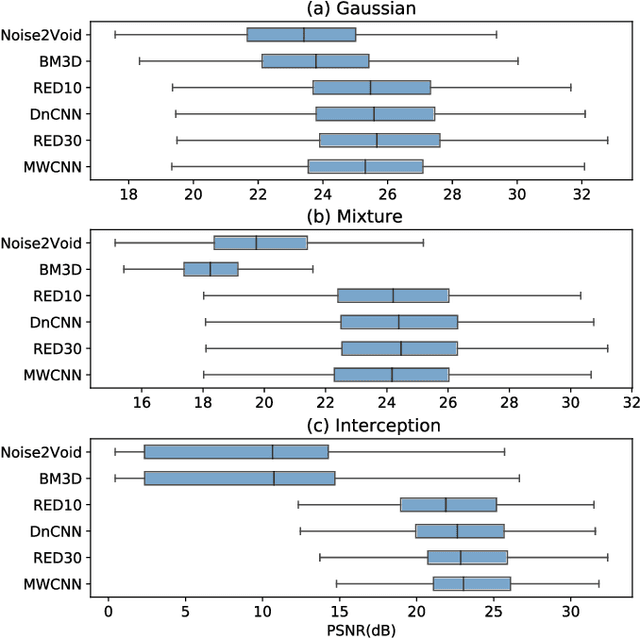

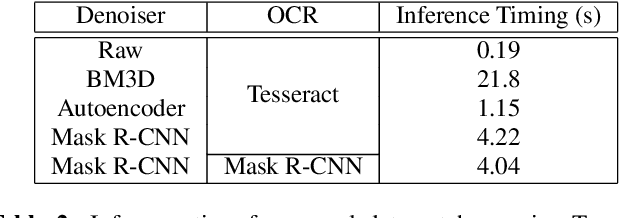
Image denoising has recently taken a leap forward due to machine learning. However, image denoisers, both expert-based and learning-based, are mostly tested on well-behaved generated noises (usually Gaussian) rather than on real-life noises, making performance comparisons difficult in real-world conditions. This is especially true for learning-based denoisers which performance depends on training data. Hence, choosing which method to use for a specific denoising problem is difficult. This paper proposes a comparative study of existing denoisers, as well as an extensible open tool that makes it possible to reproduce and extend the study. MWCNN is shown to outperform other methods when trained for a real-world image interception noise, and additionally is the second least compute hungry of the tested methods. To evaluate the robustness of conclusions, three test sets are compared. A Kendall's Tau correlation of only 60% is obtained on methods ranking between noise types, demonstrating the need for a benchmarking tool.
Electro-Magnetic Side-Channel Attack Through Learned Denoising and Classification
Oct 16, 2019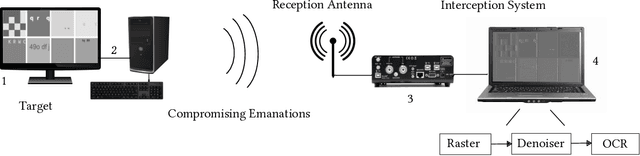
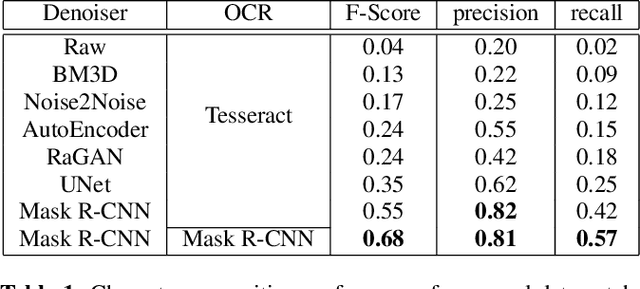
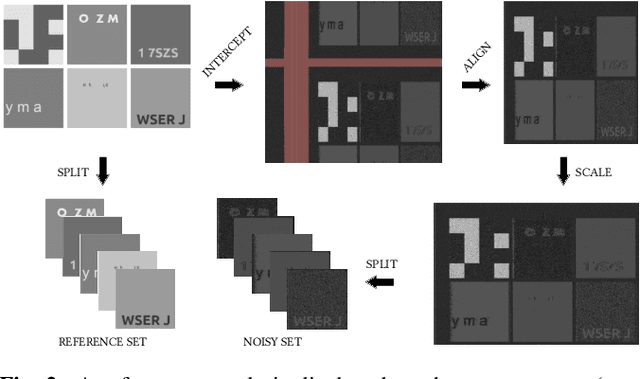
This paper proposes an upgraded electro-magnetic side-channel attack that automatically reconstructs the intercepted data. A novel system is introduced, running in parallel with leakage signal interception and catching compromising data in real-time. Based on deep learning and character recognition the proposed system retrieves more than 57% of characters present in intercepted signals regardless of signal type: analog or digital. The approach is also extended to a protection system that triggers an alarm if the system is compromised, demonstrating a success rate over 95%. Based on software-defined radio and graphics processing unit architectures, this solution can be easily deployed onto existing information systems where information shall be kept secret.
Accelerating CNN inference on FPGAs: A Survey
May 26, 2018
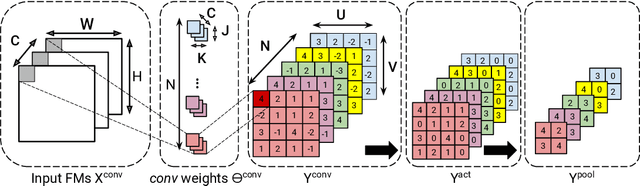
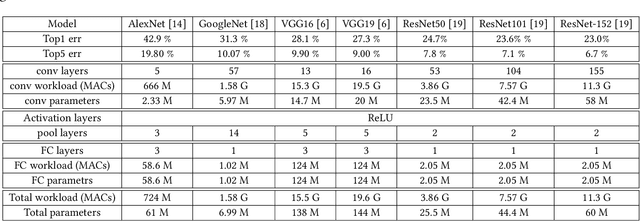
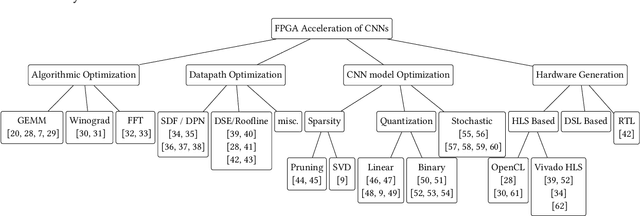
Convolutional Neural Networks (CNNs) are currently adopted to solve an ever greater number of problems, ranging from speech recognition to image classification and segmentation. The large amount of processing required by CNNs calls for dedicated and tailored hardware support methods. Moreover, CNN workloads have a streaming nature, well suited to reconfigurable hardware architectures such as FPGAs. The amount and diversity of research on the subject of CNN FPGA acceleration within the last 3 years demonstrates the tremendous industrial and academic interest. This paper presents a state-of-the-art of CNN inference accelerators over FPGAs. The computational workloads, their parallelism and the involved memory accesses are analyzed. At the level of neurons, optimizations of the convolutional and fully connected layers are explained and the performances of the different methods compared. At the network level, approximate computing and datapath optimization methods are covered and state-of-the-art approaches compared. The methods and tools investigated in this survey represent the recent trends in FPGA CNN inference accelerators and will fuel the future advances on efficient hardware deep learning.
Tactics to Directly Map CNN graphs on Embedded FPGAs
Nov 20, 2017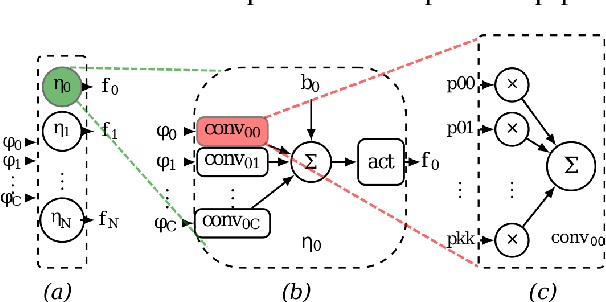
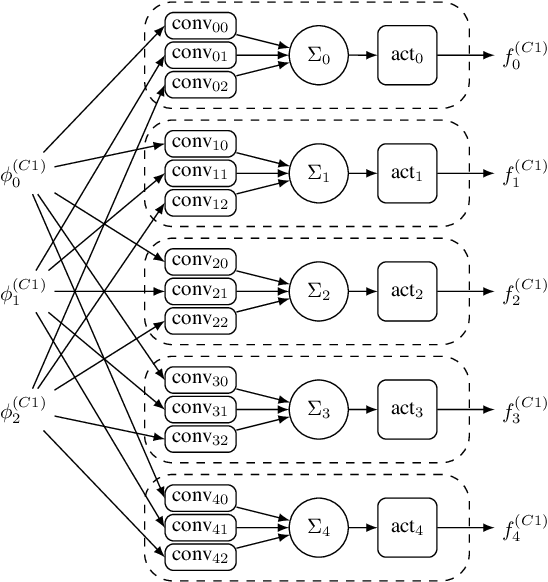

Deep Convolutional Neural Networks (CNNs) are the state-of-the-art in image classification. Since CNN feed forward propagation involves highly regular parallel computation, it benefits from a significant speed-up when running on fine grain parallel programmable logic devices. As a consequence, several studies have proposed FPGA-based accelerators for CNNs. However, because of the large computationalpower required by CNNs, none of the previous studies has proposed a direct mapping of the CNN onto the physical resources of an FPGA, allocating each processing actor to its own hardware instance.In this paper, we demonstrate the feasibility of the so called direct hardware mapping (DHM) and discuss several tactics we explore to make DHM usable in practice. As a proof of concept, we introduce the HADDOC2 open source tool, that automatically transforms a CNN description into a synthesizable hardware description with platform-independent direct hardware mapping.
A Holistic Approach for Optimizing DSP Block Utilization of a CNN implementation on FPGA
Mar 21, 2017
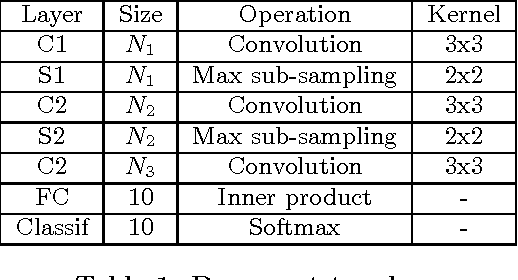
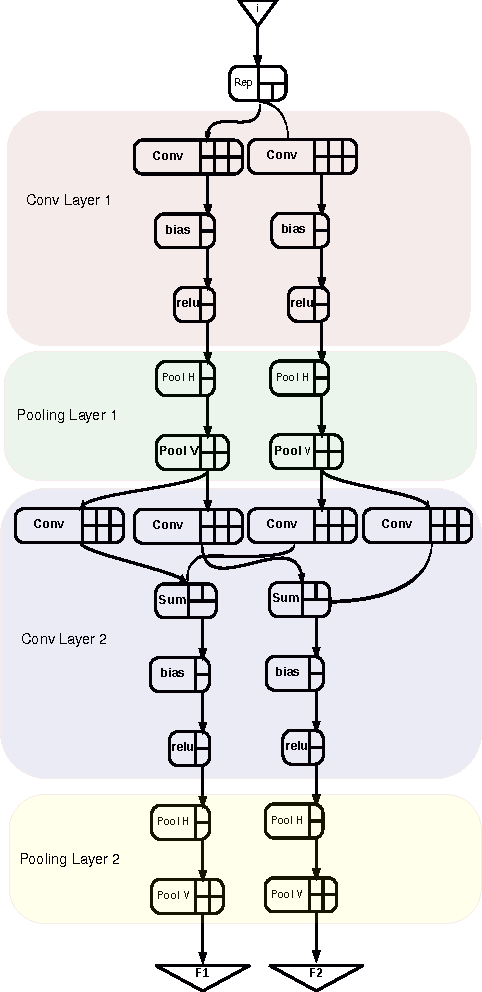

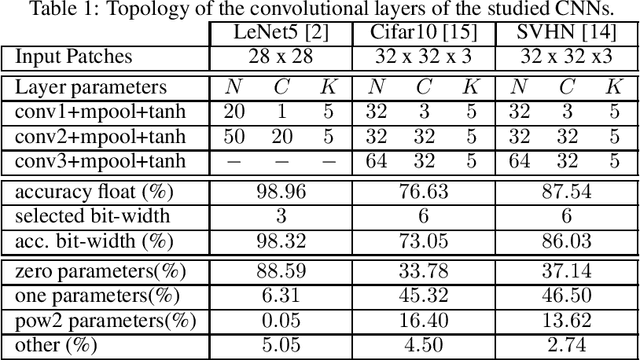
Deep Neural Networks are becoming the de-facto standard models for image understanding, and more generally for computer vision tasks. As they involve highly parallelizable computations, CNN are well suited to current fine grain programmable logic devices. Thus, multiple CNN accelerators have been successfully implemented on FPGAs. Unfortunately, FPGA resources such as logic elements or DSP units remain limited. This work presents a holistic method relying on approximate computing and design space exploration to optimize the DSP block utilization of a CNN implementation on an FPGA. This method was tested when implementing a reconfigurable OCR convolutional neural network on an Altera Stratix V device and varying both data representation and CNN topology in order to find the best combination in terms of DSP block utilization and classification accuracy. This exploration generated dataflow architectures of 76 CNN topologies with 5 different fixed point representation. Most efficient implementation performs 883 classifications/sec at 256 x 256 resolution using 8% of the available DSP blocks.