 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating CNN inference on FPGAs: A Survey
May 26, 2018
Convolutional Neural Networks (CNNs) are currently adopted to solve an ever greater number of problems, ranging from speech recognition to image classification and segmentation. The large amount of processing required by CNNs calls for dedicated and tailored hardware support methods. Moreover, CNN workloads have a streaming nature, well suited to reconfigurable hardware architectures such as FPGAs. The amount and diversity of research on the subject of CNN FPGA acceleration within the last 3 years demonstrates the tremendous industrial and academic interest. This paper presents a state-of-the-art of CNN inference accelerators over FPGAs. The computational workloads, their parallelism and the involved memory accesses are analyzed. At the level of neurons, optimizations of the convolutional and fully connected layers are explained and the performances of the different methods compared. At the network level, approximate computing and datapath optimization methods are covered and state-of-the-art approaches compared. The methods and tools investigated in this survey represent the recent trends in FPGA CNN inference accelerators and will fuel the future advances on efficient hardware deep learning.
Tactics to Directly Map CNN graphs on Embedded FPGAs
Nov 20, 2017
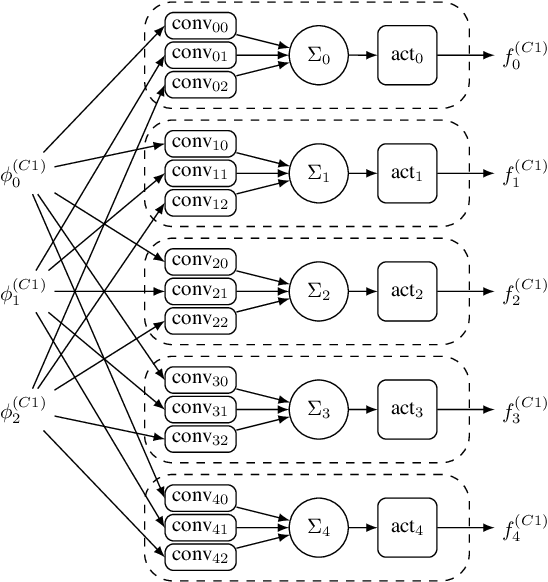

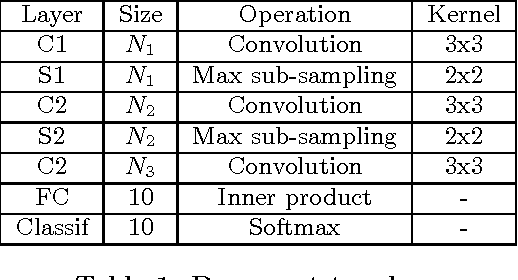
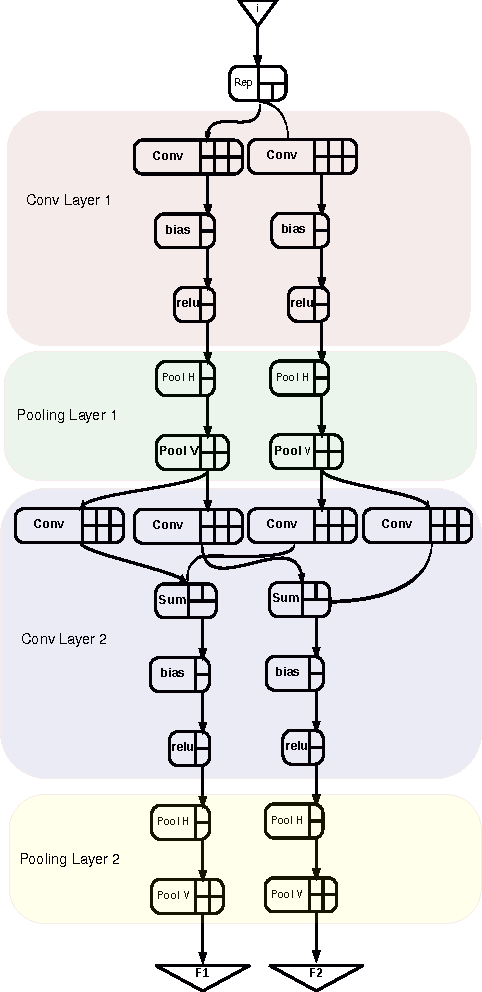
Deep Convolutional Neural Networks (CNNs) are the state-of-the-art in image classification. Since CNN feed forward propagation involves highly regular parallel computation, it benefits from a significant speed-up when running on fine grain parallel programmable logic devices. As a consequence, several studies have proposed FPGA-based accelerators for CNNs. However, because of the large computationalpower required by CNNs, none of the previous studies has proposed a direct mapping of the CNN onto the physical resources of an FPGA, allocating each processing actor to its own hardware instance.In this paper, we demonstrate the feasibility of the so called direct hardware mapping (DHM) and discuss several tactics we explore to make DHM usable in practice. As a proof of concept, we introduce the HADDOC2 open source tool, that automatically transforms a CNN description into a synthesizable hardware description with platform-independent direct hardware mapping.
A Holistic Approach for Optimizing DSP Block Utilization of a CNN implementation on FPGA
Mar 21, 2017

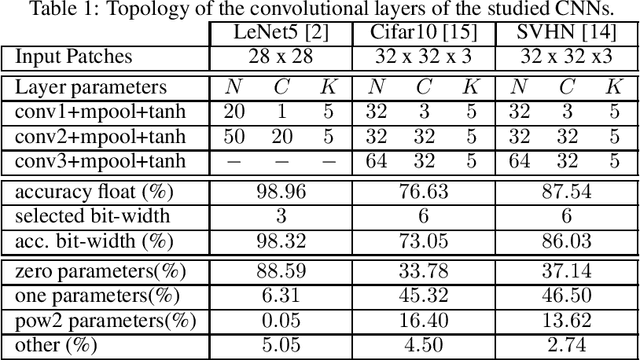
Deep Neural Networks are becoming the de-facto standard models for image understanding, and more generally for computer vision tasks. As they involve highly parallelizable computations, CNN are well suited to current fine grain programmable logic devices. Thus, multiple CNN accelerators have been successfully implemented on FPGAs. Unfortunately, FPGA resources such as logic elements or DSP units remain limited. This work presents a holistic method relying on approximate computing and design space exploration to optimize the DSP block utilization of a CNN implementation on an FPGA. This method was tested when implementing a reconfigurable OCR convolutional neural network on an Altera Stratix V device and varying both data representation and CNN topology in order to find the best combination in terms of DSP block utilization and classification accuracy. This exploration generated dataflow architectures of 76 CNN topologies with 5 different fixed point representation. Most efficient implementation performs 883 classifications/sec at 256 x 256 resolution using 8% of the available DSP blocks.