 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTactics to Directly Map CNN graphs on Embedded FPGAs
Nov 20, 2017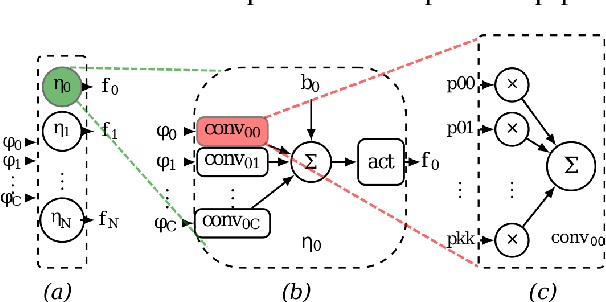
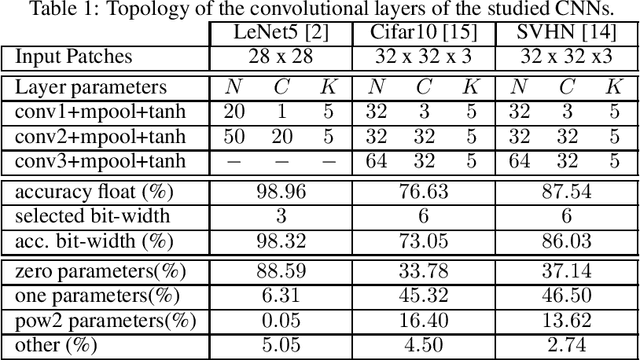
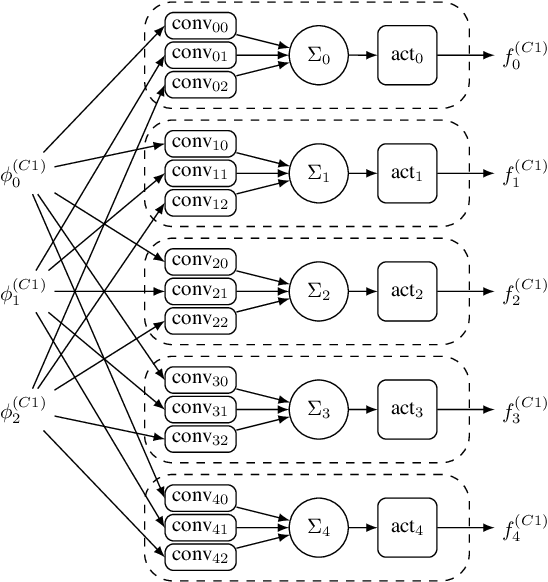

Deep Convolutional Neural Networks (CNNs) are the state-of-the-art in image classification. Since CNN feed forward propagation involves highly regular parallel computation, it benefits from a significant speed-up when running on fine grain parallel programmable logic devices. As a consequence, several studies have proposed FPGA-based accelerators for CNNs. However, because of the large computationalpower required by CNNs, none of the previous studies has proposed a direct mapping of the CNN onto the physical resources of an FPGA, allocating each processing actor to its own hardware instance.In this paper, we demonstrate the feasibility of the so called direct hardware mapping (DHM) and discuss several tactics we explore to make DHM usable in practice. As a proof of concept, we introduce the HADDOC2 open source tool, that automatically transforms a CNN description into a synthesizable hardware description with platform-independent direct hardware mapping.