 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Power of Localization for Efficiently Learning Linear Separators with Noise
Jun 03, 2018

We introduce a new approach for designing computationally efficient learning algorithms that are tolerant to noise, and demonstrate its effectiveness by designing algorithms with improved noise tolerance guarantees for learning linear separators. We consider both the malicious noise model and the adversarial label noise model. For malicious noise, where the adversary can corrupt both the label and the features, we provide a polynomial-time algorithm for learning linear separators in $\Re^d$ under isotropic log-concave distributions that can tolerate a nearly information-theoretically optimal noise rate of $\eta = \Omega(\epsilon)$. For the adversarial label noise model, where the distribution over the feature vectors is unchanged, and the overall probability of a noisy label is constrained to be at most $\eta$, we also give a polynomial-time algorithm for learning linear separators in $\Re^d$ under isotropic log-concave distributions that can handle a noise rate of $\eta = \Omega\left(\epsilon\right)$. We show that, in the active learning model, our algorithms achieve a label complexity whose dependence on the error parameter $\epsilon$ is polylogarithmic. This provides the first polynomial-time active learning algorithm for learning linear separators in the presence of malicious noise or adversarial label noise.
Data Driven Resource Allocation for Distributed Learning
Dec 15, 2016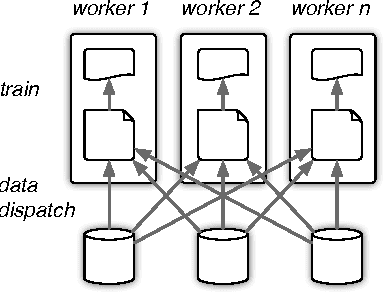

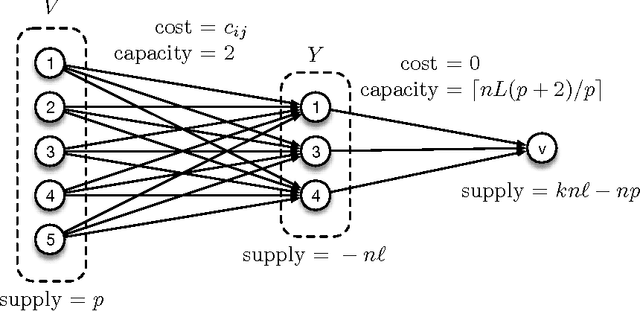
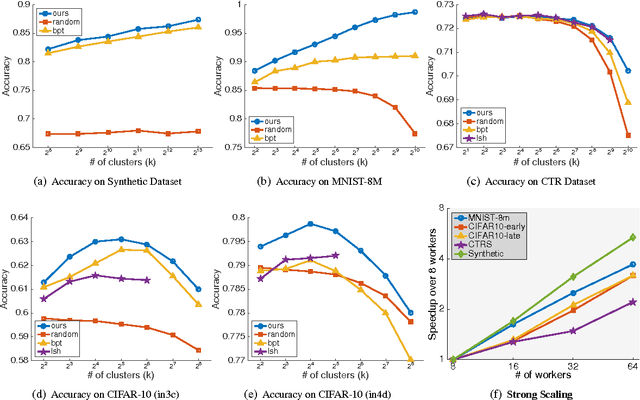
In distributed machine learning, data is dispatched to multiple machines for processing. Motivated by the fact that similar data points often belong to the same or similar classes, and more generally, classification rules of high accuracy tend to be "locally simple but globally complex" (Vapnik & Bottou 1993), we propose data dependent dispatching that takes advantage of such structure. We present an in-depth analysis of this model, providing new algorithms with provable worst-case guarantees, analysis proving existing scalable heuristics perform well in natural non worst-case conditions, and techniques for extending a dispatching rule from a small sample to the entire distribution. We overcome novel technical challenges to satisfy important conditions for accurate distributed learning, including fault tolerance and balancedness. We empirically compare our approach with baselines based on random partitioning, balanced partition trees, and locality sensitive hashing, showing that we achieve significantly higher accuracy on both synthetic and real world image and advertising datasets. We also demonstrate that our technique strongly scales with the available computing power.
Clustering under Perturbation Resilience
Dec 11, 2016

Motivated by the fact that distances between data points in many real-world clustering instances are often based on heuristic measures, Bilu and Linial~\cite{BL} proposed analyzing objective based clustering problems under the assumption that the optimum clustering to the objective is preserved under small multiplicative perturbations to distances between points. The hope is that by exploiting the structure in such instances, one can overcome worst case hardness results. In this paper, we provide several results within this framework. For center-based objectives, we present an algorithm that can optimally cluster instances resilient to perturbations of factor $(1 + \sqrt{2})$, solving an open problem of Awasthi et al.~\cite{ABS10}. For $k$-median, a center-based objective of special interest, we additionally give algorithms for a more relaxed assumption in which we allow the optimal solution to change in a small $\epsilon$ fraction of the points after perturbation. We give the first bounds known for $k$-median under this more realistic and more general assumption. We also provide positive results for min-sum clustering which is typically a harder objective than center-based objectives from approximability standpoint. Our algorithms are based on new linkage criteria that may be of independent interest. Additionally, we give sublinear-time algorithms, showing algorithms that can return an implicit clustering from only access to a small random sample.
Label Efficient Learning by Exploiting Multi-class Output Codes
Nov 25, 2016

We present a new perspective on the popular multi-class algorithmic techniques of one-vs-all and error correcting output codes. Rather than studying the behavior of these techniques for supervised learning, we establish a connection between the success of these methods and the existence of label-efficient learning procedures. We show that in both the realizable and agnostic cases, if output codes are successful at learning from labeled data, they implicitly assume structure on how the classes are related. By making that structure explicit, we design learning algorithms to recover the classes with low label complexity. We provide results for the commonly studied cases of one-vs-all learning and when the codewords of the classes are well separated. We additionally consider the more challenging case where the codewords are not well separated, but satisfy a boundary features condition that captures the natural intuition that every bit of the codewords should be significant.
An Improved Gap-Dependency Analysis of the Noisy Power Method
Feb 23, 2016We consider the noisy power method algorithm, which has wide applications in machine learning and statistics, especially those related to principal component analysis (PCA) under resource (communication, memory or privacy) constraints. Existing analysis of the noisy power method shows an unsatisfactory dependency over the "consecutive" spectral gap $(\sigma_k-\sigma_{k+1})$ of an input data matrix, which could be very small and hence limits the algorithm's applicability. In this paper, we present a new analysis of the noisy power method that achieves improved gap dependency for both sample complexity and noise tolerance bounds. More specifically, we improve the dependency over $(\sigma_k-\sigma_{k+1})$ to dependency over $(\sigma_k-\sigma_{q+1})$, where $q$ is an intermediate algorithm parameter and could be much larger than the target rank $k$. Our proofs are built upon a novel characterization of proximity between two subspaces that differ from canonical angle characterizations analyzed in previous works. Finally, we apply our improved bounds to distributed private PCA and memory-efficient streaming PCA and obtain bounds that are superior to existing results in the literature.
Statistical Active Learning Algorithms for Noise Tolerance and Differential Privacy
Nov 05, 2014We describe a framework for designing efficient active learning algorithms that are tolerant to random classification noise and are differentially-private. The framework is based on active learning algorithms that are statistical in the sense that they rely on estimates of expectations of functions of filtered random examples. It builds on the powerful statistical query framework of Kearns (1993). We show that any efficient active statistical learning algorithm can be automatically converted to an efficient active learning algorithm which is tolerant to random classification noise as well as other forms of "uncorrelated" noise. The complexity of the resulting algorithms has information-theoretically optimal quadratic dependence on $1/(1-2\eta)$, where $\eta$ is the noise rate. We show that commonly studied concept classes including thresholds, rectangles, and linear separators can be efficiently actively learned in our framework. These results combined with our generic conversion lead to the first computationally-efficient algorithms for actively learning some of these concept classes in the presence of random classification noise that provide exponential improvement in the dependence on the error $\epsilon$ over their passive counterparts. In addition, we show that our algorithms can be automatically converted to efficient active differentially-private algorithms. This leads to the first differentially-private active learning algorithms with exponential label savings over the passive case.
Budgeted Influence Maximization for Multiple Products
Apr 16, 2014
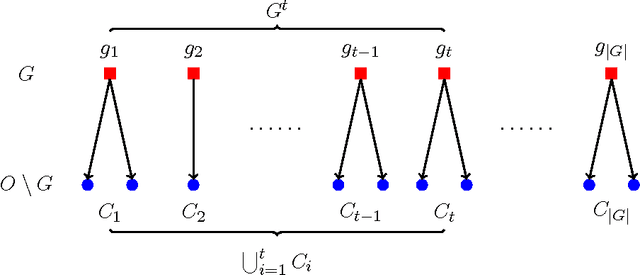
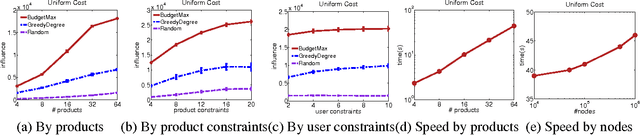
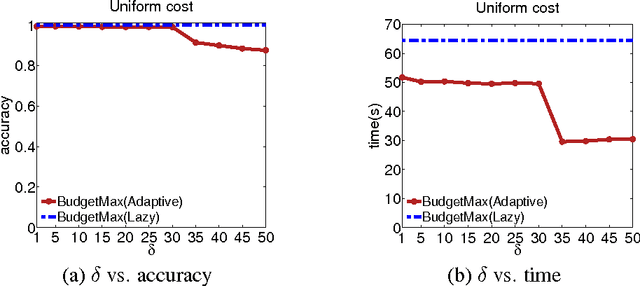
The typical algorithmic problem in viral marketing aims to identify a set of influential users in a social network, who, when convinced to adopt a product, shall influence other users in the network and trigger a large cascade of adoptions. However, the host (the owner of an online social platform) often faces more constraints than a single product, endless user attentions, unlimited budget and unbounded time; in reality, multiple products need to be advertised, each user can tolerate only a small number of recommendations, influencing user has a cost and advertisers have only limited budgets, and the adoptions need to be maximized within a short time window. Given theses myriads of user, monetary, and timing constraints, it is extremely challenging for the host to design principled and efficient viral market algorithms with provable guarantees. In this paper, we provide a novel solution by formulating the problem as a submodular maximization in a continuous-time diffusion model under an intersection of a matroid and multiple knapsack constraints. We also propose an adaptive threshold greedy algorithm which can be faster than the traditional greedy algorithm with lazy evaluation, and scalable to networks with million of nodes. Furthermore, our mathematical formulation allows us to prove that the algorithm can achieve an approximation factor of $k_a/(2+2 k)$ when $k_a$ out of the $k$ knapsack constraints are active, which also improves over previous guarantees from combinatorial optimization literature. In the case when influencing each user has uniform cost, the approximation becomes even better to a factor of $1/3$. Extensive synthetic and real world experiments demonstrate that our budgeted influence maximization algorithm achieves the-state-of-the-art in terms of both effectiveness and scalability, often beating the next best by significant margins.
Distributed k-Means and k-Median Clustering on General Topologies
Oct 30, 2013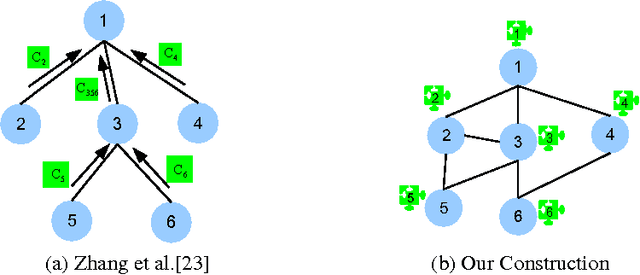
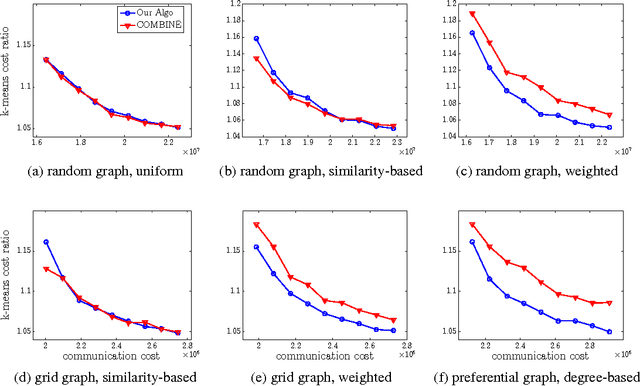
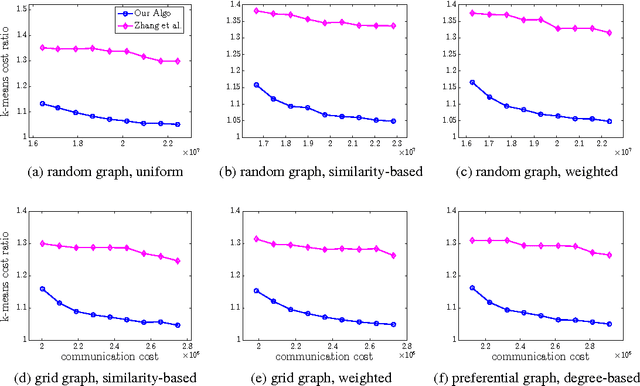
This paper provides new algorithms for distributed clustering for two popular center-based objectives, k-median and k-means. These algorithms have provable guarantees and improve communication complexity over existing approaches. Following a classic approach in clustering by \cite{har2004coresets}, we reduce the problem of finding a clustering with low cost to the problem of finding a coreset of small size. We provide a distributed method for constructing a global coreset which improves over the previous methods by reducing the communication complexity, and which works over general communication topologies. Experimental results on large scale data sets show that this approach outperforms other coreset-based distributed clustering algorithms.
Active and passive learning of linear separators under log-concave distributions
Apr 26, 2013We provide new results concerning label efficient, polynomial time, passive and active learning of linear separators. We prove that active learning provides an exponential improvement over PAC (passive) learning of homogeneous linear separators under nearly log-concave distributions. Building on this, we provide a computationally efficient PAC algorithm with optimal (up to a constant factor) sample complexity for such problems. This resolves an open question concerning the sample complexity of efficient PAC algorithms under the uniform distribution in the unit ball. Moreover, it provides the first bound for a polynomial-time PAC algorithm that is tight for an interesting infinite class of hypothesis functions under a general and natural class of data-distributions, providing significant progress towards a longstanding open question. We also provide new bounds for active and passive learning in the case that the data might not be linearly separable, both in the agnostic case and and under the Tsybakov low-noise condition. To derive our results, we provide new structural results for (nearly) log-concave distributions, which might be of independent interest as well.
Learning Valuation Functions
Sep 02, 2011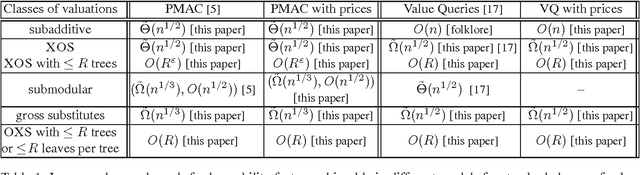
In this paper we study the approximate learnability of valuations commonly used throughout economics and game theory for the quantitative encoding of agent preferences. We provide upper and lower bounds regarding the learnability of important subclasses of valuation functions that express no-complementarities. Our main results concern their approximate learnability in the distributional learning (PAC-style) setting. We provide nearly tight lower and upper bounds of $\tilde{\Theta}(n^{1/2})$ on the approximation factor for learning XOS and subadditive valuations, both widely studied superclasses of submodular valuations. Interestingly, we show that the $\tilde{\Omega}(n^{1/2})$ lower bound can be circumvented for XOS functions of polynomial complexity; we provide an algorithm for learning the class of XOS valuations with a representation of polynomial size achieving an $O(n^{\eps})$ approximation factor in time $O(n^{1/\eps})$ for any $\eps > 0$. This highlights the importance of considering the complexity of the target function for polynomial time learning. We also provide new learning results for interesting subclasses of submodular functions. Our upper bounds for distributional learning leverage novel structural results for all these valuation classes. We show that many of these results provide new learnability results in the Goemans et al. model (SODA 2009) of approximate learning everywhere via value queries. We also introduce a new model that is more realistic in economic settings, in which the learner can set prices and observe purchase decisions at these prices rather than observing the valuation function directly. In this model, most of our upper bounds continue to hold despite the fact that the learner receives less information (both for learning in the distributional setting and with value queries), while our lower bounds naturally extend.