 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy-Efficient Motion Planner for Legged Robots
Mar 08, 2025We propose an online motion planner for legged robot locomotion with the primary objective of achieving energy efficiency. The conceptual idea is to leverage a placement set of footstep positions based on the robot's body position to determine when and how to execute steps. In particular, the proposed planner uses virtual placement sets beneath the hip joints of the legs and executes a step when the foot is outside of such placement set. Furthermore, we propose a parameter design framework that considers both energy-efficiency and robustness measures to optimize the gait by changing the shape of the placement set along with other parameters, such as step height and swing time, as a function of walking speed. We show that the planner produces trajectories that have a low Cost of Transport (CoT) and high robustness measure, and evaluate our approach against model-free Reinforcement Learning (RL) and motion imitation using biological dog motion priors as the reference. Overall, within low to medium velocity range, we show a 50.4% improvement in CoT and improved robustness over model-free RL, our best performing baseline. Finally, we show ability to handle slippery surfaces, gait transitions, and disturbances in simulation and hardware with the Unitree A1 robot.
Simultaneous State Estimation and Contact Detection for Legged Robots by Multiple-Model Kalman Filtering
Apr 04, 2024



This paper proposes an algorithm for combined contact detection and state estimation for legged robots. The proposed algorithm models the robot's movement as a switched system, in which different modes relate to different feet being in contact with the ground. The key element in the proposed algorithm is an interacting multiple-model Kalman filter, which identifies the currently-active mode defining contacts, while estimating the state. The rationale for the proposed estimation framework is that contacts (and contact forces) impact the robot's state and vice versa. This paper presents validation studies with a quadruped using (i) the high-fidelity simulator Gazebo for a comparison with ground truth values and a baseline estimator, and (ii) hardware experiments with the Unitree A1 robot. The simulation study shows that the proposed algorithm outperforms the baseline estimator, which does not simultaneous detect contacts. The hardware experiments showcase the applicability of the proposed algorithm and highlights the ability to detect contacts.
Gaussian Processes with State-Dependent Noise for Stochastic Control
May 25, 2023

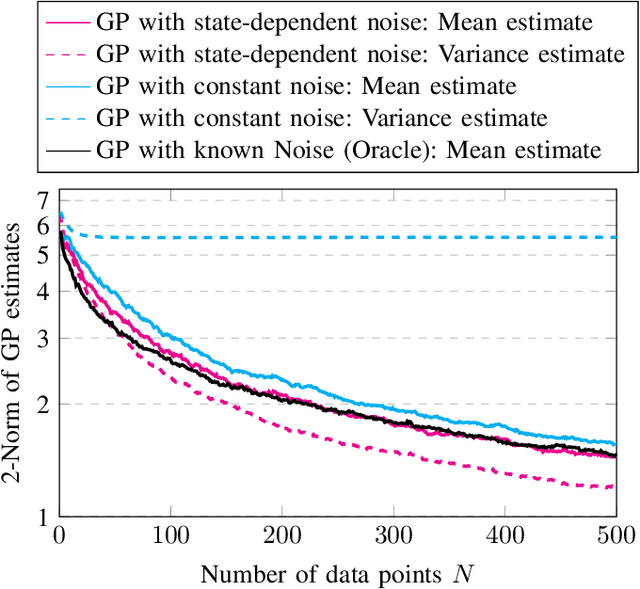
This paper considers a stochastic control framework, in which the residual model uncertainty of the dynamical system is learned using a Gaussian Process (GP). In the proposed formulation, the residual model uncertainty consists of a nonlinear function and state-dependent noise. The proposed formulation uses a posterior-GP to approximate the residual model uncertainty and a prior-GP to account for state-dependent noise. The two GPs are interdependent and are thus learned jointly using an iterative algorithm. Theoretical properties of the iterative algorithm are established. Advantages of the proposed state-dependent formulation include (i) faster convergence of the GP estimate to the unknown function as the GP learns which data samples are more trustworthy and (ii) an accurate estimate of state-dependent noise, which can, e.g., be useful for a controller or decision-maker to determine the uncertainty of an action. Simulation studies highlight these two advantages.
Real-to-Sim: Deep Learning with Auto-Tuning to Predict Residual Errors using Sparse Data
Sep 07, 2022
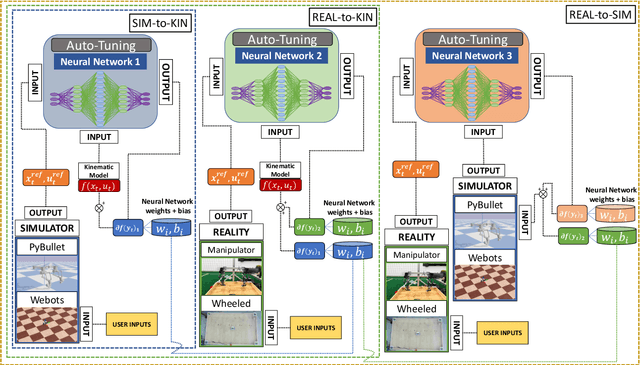
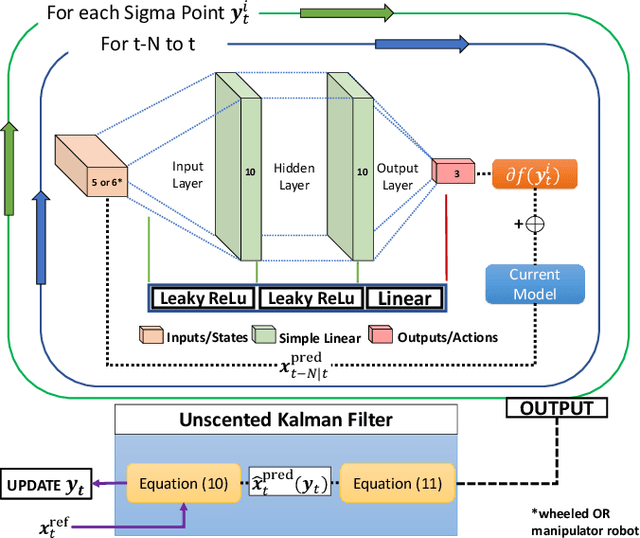

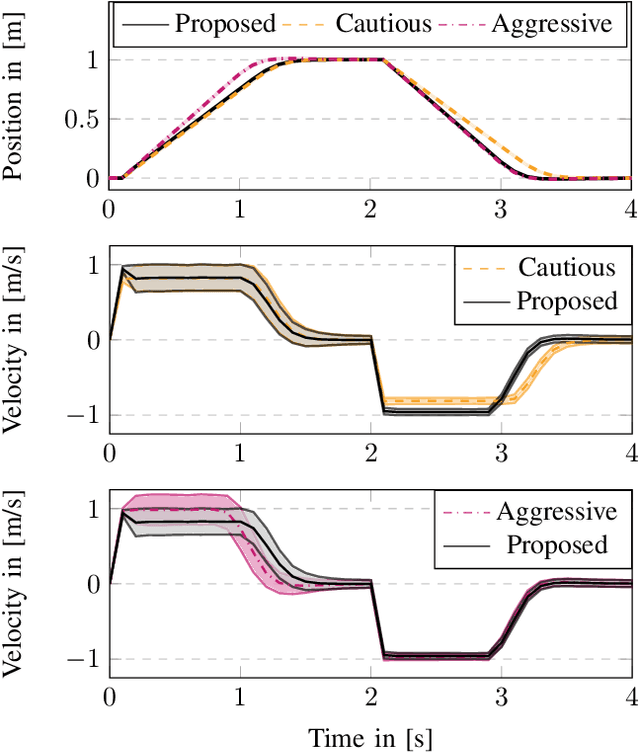
Achieving highly accurate kinematic or simulator models that are close to the real robot can facilitate model-based controls (e.g., model predictive control or linear-quadradic regulators), model-based trajectory planning (e.g., trajectory optimization), and decrease the amount of learning time necessary for reinforcement learning methods. Thus, the objective of this work is to learn the residual errors between a kinematic and/or simulator model and the real robot. This is achieved using auto-tuning and neural networks, where the parameters of a neural network are updated using an auto-tuning method that applies equations from an Unscented Kalman Filter (UKF) formulation. Using this method, we model these residual errors with only small amounts of data - a necessity as we improve the simulator/kinematic model by learning directly from hardware operation. We demonstrate our method on robotic hardware (e.g., manipulator arm), and show that with the learned residual errors, we can further close the reality gap between kinematic models, simulations, and the real robot.
Mobility, Communication and Computation Aware Federated Learning for Internet of Vehicles
May 17, 2022
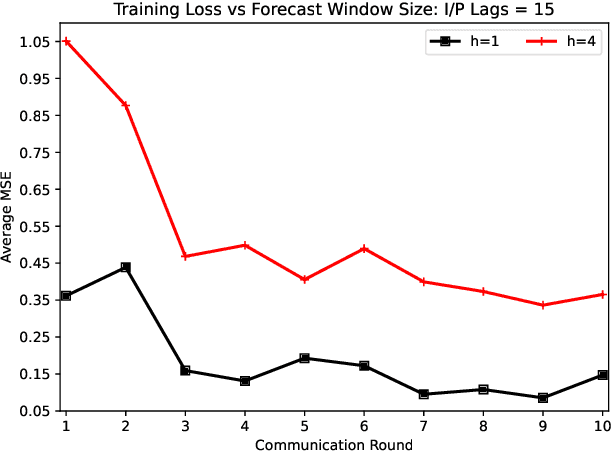
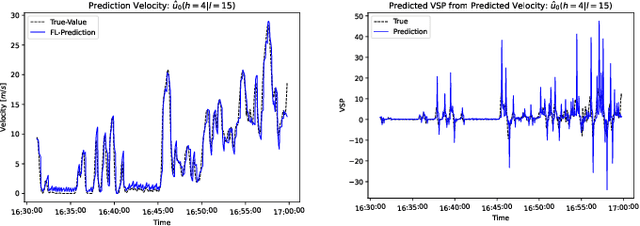
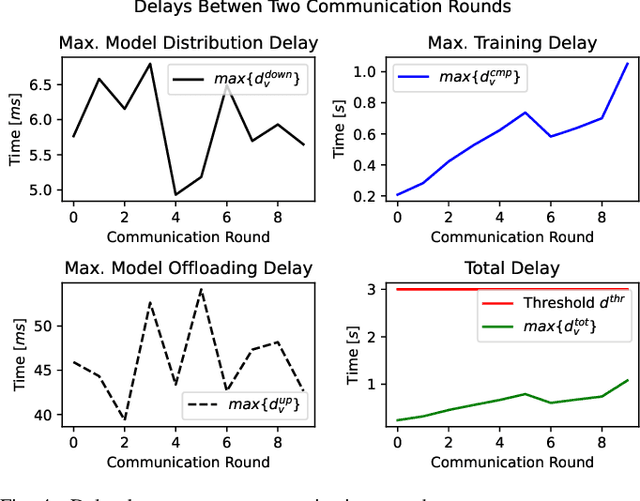
While privacy concerns entice connected and automated vehicles to incorporate on-board federated learning (FL) solutions, an integrated vehicle-to-everything communication with heterogeneous computation power aware learning platform is urgently necessary to make it a reality. Motivated by this, we propose a novel mobility, communication and computation aware online FL platform that uses on-road vehicles as learning agents. Thanks to the advanced features of modern vehicles, the on-board sensors can collect data as vehicles travel along their trajectories, while the on-board processors can train machine learning models using the collected data. To take the high mobility of vehicles into account, we consider the delay as a learning parameter and restrict it to be less than a tolerable threshold. To satisfy this threshold, the central server accepts partially trained models, the distributed roadside units (a) perform downlink multicast beamforming to minimize global model distribution delay and (b) allocate optimal uplink radio resources to minimize local model offloading delay, and the vehicle agents conduct heterogeneous local model training. Using real-world vehicle trace datasets, we validate our FL solutions. Simulation shows that the proposed integrated FL platform is robust and outperforms baseline models. With reasonable local training episodes, it can effectively satisfy all constraints and deliver near ground truth multi-horizon velocity and vehicle-specific power predictions.
Automated Controller Calibration by Kalman Filtering
Nov 21, 2021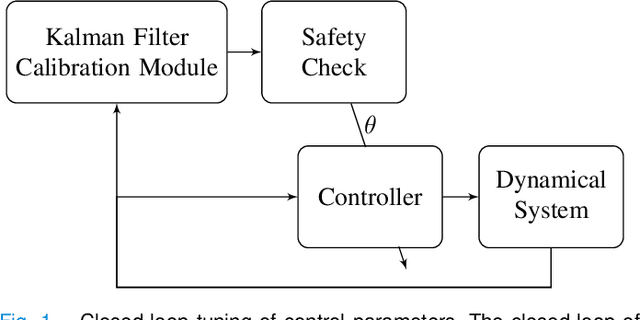

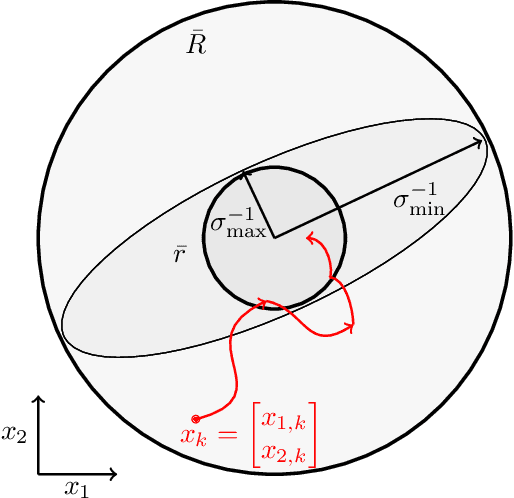
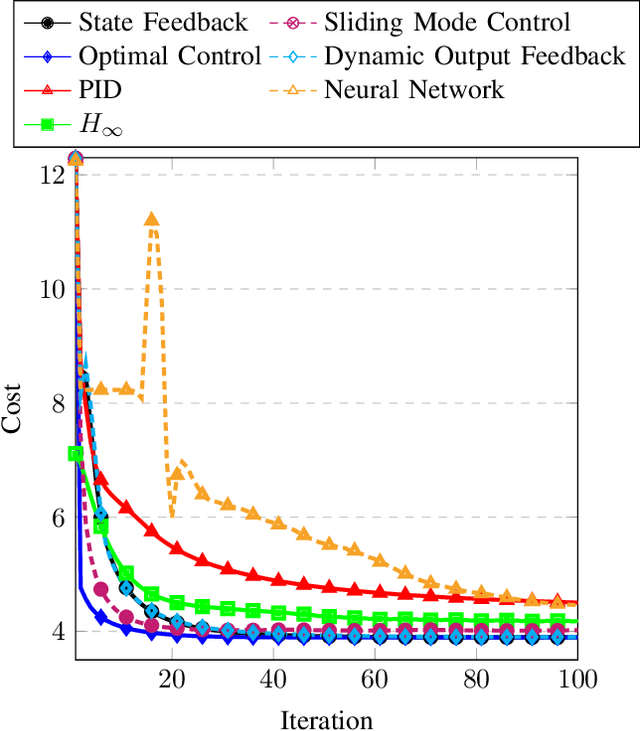
This paper proposes a method for calibrating control parameters. Examples of such control parameters are gains of PID controllers, weights of a cost function for optimal control, filter coefficients, the sliding surface of a sliding mode controller, or weights of a neural network. Hence, the proposed method can be applied to a wide range of controllers. The method uses a Kalman filter that estimates control parameters rather than the system's state, using data of closed-loop system operation. The control parameter calibration is driven by a training objective, which encompasses specifications on the performance of the dynamical system. The calibration method tunes the parameters online and robustly, is computationally efficient, has low data storage requirements, and is easy to implement making it appealing for many real-time applications. Simulation results show that the method is able to learn control parameters quickly (approximately 24% average decay factor of closed-loop cost), is able to tune the parameters to compensate for disturbances (approximately 29% improvement on tracking precision), and is robust to noise. Further, a simulation study with the high-fidelity vehicle simulator CarSim shows that the method can calibrate controllers of a complex dynamical system online, which indicates its applicability to a real-world system.
Maximum Likelihood Methods for Inverse Learning of Optimal Controllers
May 06, 2020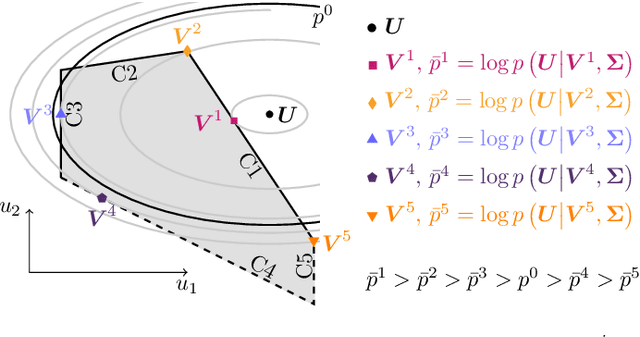


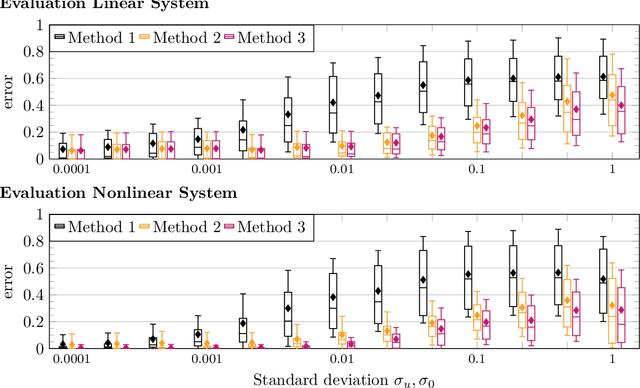
This paper presents a framework for inverse learning of objective functions for constrained optimal control problems, which is based on the Karush-Kuhn-Tucker (KKT) conditions. We discuss three variants corresponding to different model assumptions and computational complexities. The first method uses a convex relaxation of the KKT conditions and serves as the benchmark. The main contribution of this paper is the proposition of two learning methods that combine the KKT conditions with maximum likelihood estimation. The key benefit of this combination is the systematic treatment of constraints for learning from noisy data with a branch-and-bound algorithm using likelihood arguments. This paper discusses theoretic properties of the learning methods and presents simulation results that highlight the advantages of using the maximum likelihood formulation for learning objective functions.
Using Human Ratings for Feedback Control: A Supervised Learning Approach with Application to Rehabilitation Robotics
Jun 24, 2019
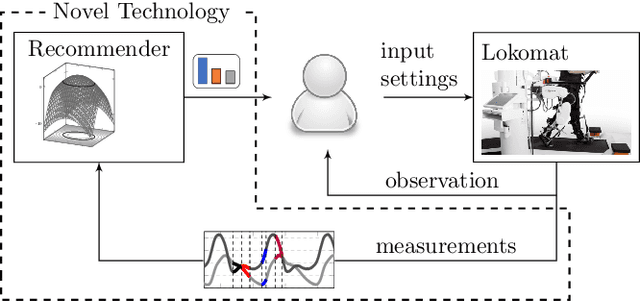

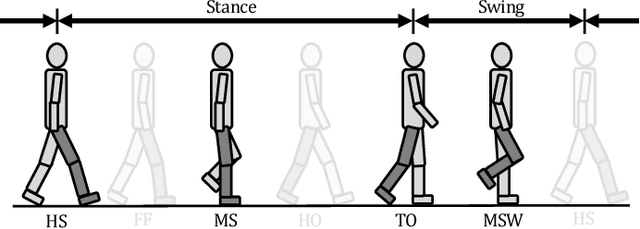
This paper presents a method for tailoring a parametric controller based on human ratings. The method leverages supervised learning concepts in order to train a reward model from data. It is applied to a gait rehabilitation robot with the goal of teaching the robot how to walk patients physiologically. In this context, the reward model judges the physiology of the gait cycle (instead of therapists) using sensor measurements provided by the robot and the automatic feedback controller chooses the input settings of the robot so as to maximize the reward. The key advantage of the proposed method is that only a few input adaptations are necessary to achieve a physiological gait cycle. Experiments with non-disabled subjects show that the proposed method permits the incorporation of human expertise into a control law and to automatically walk patients physiologically.